






 本文通过实例展示了如何使用霍夫曼编码进行图像压缩,包括编码与解码过程,并计算了压缩比、熵及霍夫曼编码的平均长度与冗余度。此外,还解释了为何在压缩领域中编码方法常与二叉树联系在一起。
本文通过实例展示了如何使用霍夫曼编码进行图像压缩,包括编码与解码过程,并计算了压缩比、熵及霍夫曼编码的平均长度与冗余度。此外,还解释了为何在压缩领域中编码方法常与二叉树联系在一起。
2. 利用程序huff_enc和huff_dec进行以下操作(在每种情况下,利用由被压缩图像生成的码本)。
(a)对Sena、Sensin和Omaha图像时行编码。
答案:
| 压缩前图像名称 | 压缩后名称 | 压缩前大小 | 压缩后大小 | 压缩比 |
| SENA.IMG | sena.huff | 64.0KB(65,536字节) | 56.1KB(57,503字节) | 87.6% |
| SENSIN.IMG | sensin.huff | 64.0KB(65,536字节) | 60.2KB(61,649字节) | 94.1% |
| OMAHA.IMG | omaha.huff | 64.0KB(65,536字节) | 57.0KB(58,374字节) | 89.1% |
4. 一个信源从符号集A={a1, a2, a3, a4, a5}中选择字母,概率为P(a1)=0.15,P(a2)=0.04,P(a3)=0.26,P(a4)=0.05,P(a5)=0.50。
(a)计算这个信源的熵。
(b)求这个信源的霍夫曼码。
(c)求(b)中代码的平均长度及其冗余度。
答:
(a)H=-P(a1)log2(P(a1))-P(a2)log2(P(a2))-P(a3)log2(P(a3))-P(a4)log2(P(a4))-P(a5)log2(P(a5))
=-0.15*log2(0.15)-0.04*log2(0.04)-0.26*log2(0.26)-0.05*log2(0.05)-0.50*log2(0.50)
=2.368bit
(b)霍夫曼编码:
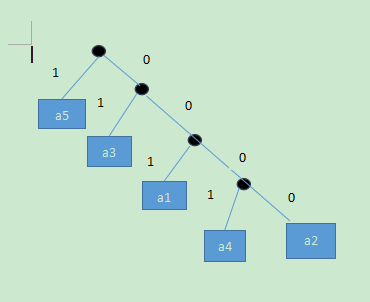
a1的霍夫曼编码为001
a2的霍夫曼编码为0000
a3的霍夫曼编码为01
a4的霍夫曼编码为0001
a5的霍夫曼编码为1
(c)平均码长为L
L=P(a1)*l(a1)+P(a2)*l(a2)+P(a3)*l(a3)+P(a4)*l(a4)+P(a5)*l(a5)
=0.15*3+0.04*4+0.26*2+0.05*4+0.5*1
=1.83比特/符号
冗余度:
H-L=2.368-1.83=0.538
3.为什么压缩领域中的编码方法总和二叉树联系在一起呢?
答:为了使用不固定的码长表示单个字符,编码必须符合“前缀编码”的要求,即较短的编码决不能是较长编码的前缀。要构造符合这一要求的二进制编码体系,二叉树是最理想的选择。

















 1348
1348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









