






 本文介绍了Apache Spark的数据处理流程,包括数据如何从外部输入到Spark并转化为RDD,通过转换算子进行数据处理,最终输出结果到分布式存储或其他形式。重点讨论了Spark中的核心数据模型RDD及其子类。
本文介绍了Apache Spark的数据处理流程,包括数据如何从外部输入到Spark并转化为RDD,通过转换算子进行数据处理,最终输出结果到分布式存储或其他形式。重点讨论了Spark中的核心数据模型RDD及其子类。
下图 中描述了 Spark 的输入、运行转换、输出。
在运行转换中通过算子对 RDD进行转换。
算子是 RDD 中定义的函数,可以对 RDD 中的数据进行转换和操作。
输入:在 Spark 程序运行中,数据从外部数据空间(例如, HDFS、 Scala 集合或数据)输入到 Spark,数据就进入了 Spark 运行时数据空间,会转化为 Spark 中的数据块,通过 BlockManager 进行管理。
运行:在 Spark 数据输入形成 RDD 后,便可以通过变换算子 f liter 等,对数据操作并将 RDD 转化为新的 RDD,通过行动(Action)算子,触发 Spark 提交作业。如果数据需要复用,可以通过 Cache 算子,将数据缓存到内存。
输出:程序运行结束数据会输出 Spark 运行时空间,存储到分布式存储中(如saveAsTextFile 输出到 HDFS)或 Scala 数据或集合中( collect 输出到 Scala 集合,count 返回 Scala Int 型数据)。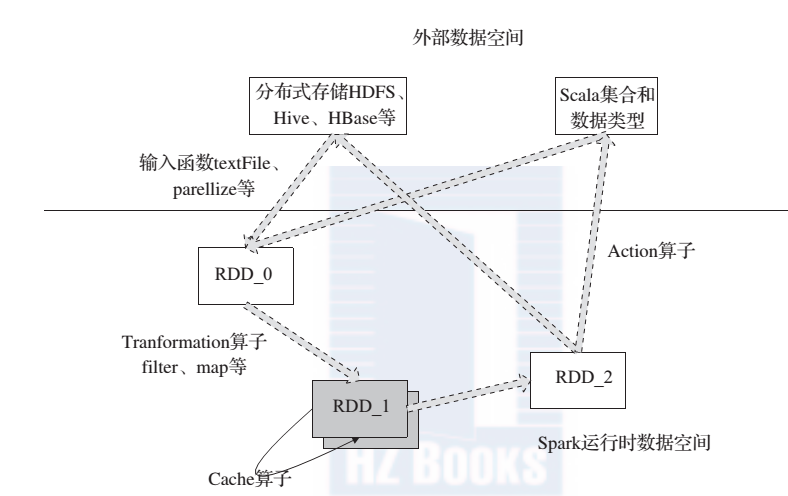
图 1 Spark 算子和数据空间
Spark的核心数据模型是RDD,但RDD是个抽象类,具体由各子类实现,如MappedRDD、Shuff ledRDD等子类。Spark将常用的大数据操作都转化成为RDD 的子类。
本文转自大数据躺过的坑博客园博客,原文链接:http://www.cnblogs.com/zlslch/p/5724027.html,如需转载请自行联系原作者

















 483
483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









