



 本文详细阐述了如何通过Python优化网站URL,简化路径以实现更短的连接。包括分析现有规则、创建新表存储转换后的路径、规划并生成新文件名等步骤,最终实现自动化处理。
本文详细阐述了如何通过Python优化网站URL,简化路径以实现更短的连接。包括分析现有规则、创建新表存储转换后的路径、规划并生成新文件名等步骤,最终实现自动化处理。

起因是公司想对现有网站做SEO优化,在优化URL这一块,思路是简化路径,是连接更短!
第一步: 分析规则
原始表
SELECT id , uri,www_uri from `article` LIMIT 100分析一条连接:
/detail/0ztm/161011/1476154039.html
真实存储路径是:
/_/boss/0/zt/m/16/10/11/1476154039.html我们要做的就是把1476154039.html 替换成从2000开始计数的文件名,例如 2000.html
第二步:分析表中所有连接,转化成真实路径,方便后边python直接调用
考虑把不在原始表上做修改,新建表
create table article_pathzsq
(
zsid BIGINT not null AUTO_INCREMENT PRIMARY KEY,
id BIGINT ,
uri VARCHAR(255),
www_uri varchar(255),
uri_path varchar(512),
uri_htm varchar(255),
www_uri_path varchar(512),
www_uri_htm varchar(512),
inum varchar(128),
isflag int not null DEFAULT 0
)
insert into article_pathzsq (id,uri,www_uri,uri_path,uri_htm,www_uri_path,www_uri_htm)
SELECT a.id , a.uri , a.www_uri ,
CONCAT(
(case when substring_index(a.uri,'/',3) = '/detail/0nsm' then
REPLACE(substring_index(a.uri,'/',3), '/detail/0nsm', '/_/boss/0/ns/m')
when substring_index(a.uri,'/',3) = '/detail/0ztm' then
REPLACE(substring_index(a.uri,'/',3), '/detail/0ztm', '/_/boss/0/zt/m')
when substring_index(a.uri,'/',3) = '/detail/3nsm' then
REPLACE(substring_index(a.uri,'/',3), '/detail/3nsm', '/_/boss/3/ns/m')
when substring_index(a.uri,'/',3) = '/detail/3ztm' then
REPLACE(substring_index(a.uri,'/',3), '/detail/3ztm', '/_/boss/3/zt/m')
END) ,'/',
SUBSTR(substring_index(a.uri,'/',-2),1,2) ,'/' ,SUBSTR(substring_index(a.uri,'/',-2),3,2),'/',SUBSTR(substring_index(a.uri,'/',-2),5,2),'/'
) as uri_path , SUBSTR(substring_index(a.uri,'/',-2),8,1000) as uri_htm ,
CONCAT(
(case when substring_index(a.www_uri,'/',3) = '/detail/0nswww' then
REPLACE(substring_index(a.www_uri,'/',3), '/detail/0nswww', '/_/boss/0/ns/www')
when substring_index(a.www_uri,'/',3) = '/detail/0ztwww' then
REPLACE(substring_index(a.www_uri,'/',3), '/detail/0ztwww', '/_/boss/0/zt/www')
when substring_index(a.www_uri,'/',3) = '/detail/3nswww' then
REPLACE(substring_index(a.www_uri,'/',3), '/detail/3nswww', '/_/boss/3/ns/www')
when substring_index(a.www_uri,'/',3) = '/detail/3ztwww' then
REPLACE(substring_index(a.www_uri,'/',3), '/detail/3ztwww', '/_/boss/3/zt/www')
END) ,'/',
SUBSTR(substring_index(a.www_uri,'/',-2),1,2) ,'/' ,SUBSTR(substring_index(a.www_uri,'/',-2),3,2),'/',SUBSTR(substring_index(a.www_uri,'/',-2),5,2),'/'
) as www_uri_path , SUBSTR(substring_index(a.www_uri,'/',-2),8,1000) as www_uri_htm
from `article` a
where uri not REGEXP '/_/boss'
LIMIT 10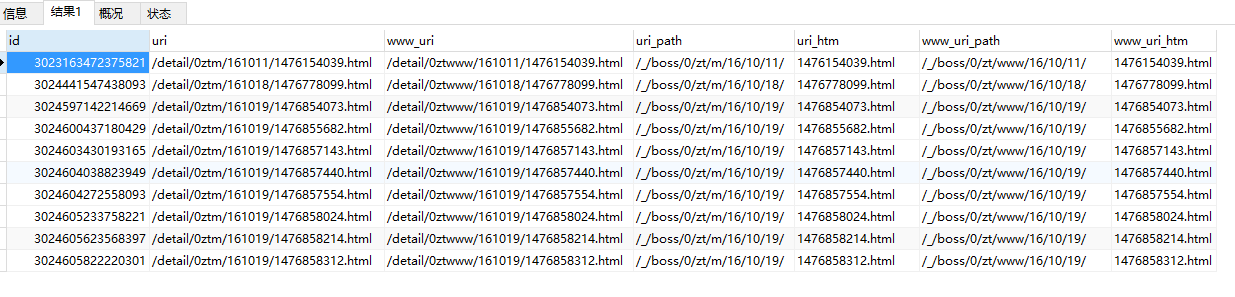
第三步:在article_pathzsq,规划新建文件名称,按照规则,从2000计数递增
UPDATE article_pathzsq SET inum = CONCAT( (zsid + 2000) , '.html')
where inum is null 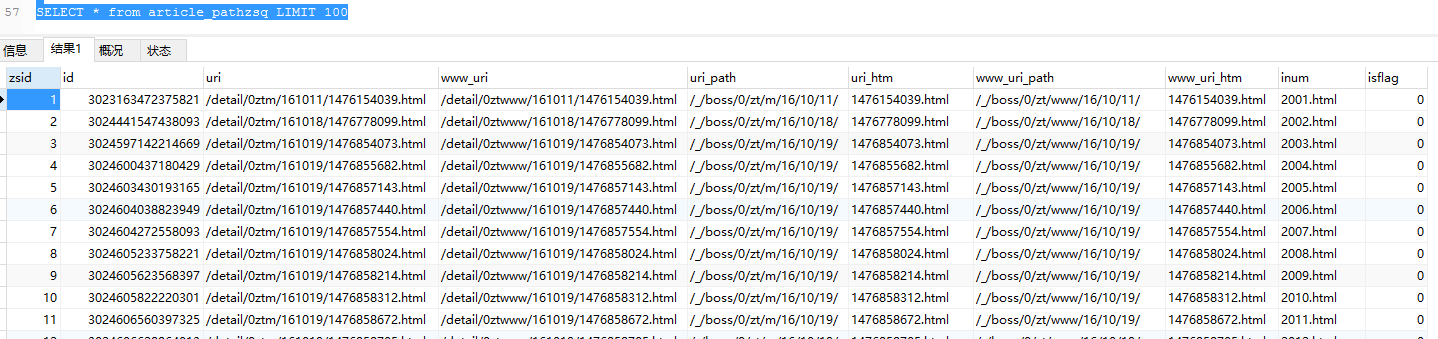
然后用python(我这里使用的是python2.6,系统自带的),读取数据库,结果集;按照结果集,复制之前的文件,生成新的文件:
#!python
# -*- coding: UTF-8 -*-
import MySQLdb
import os
dbip = "192.168.0.0"
dbuser = "mysql"
dbpwd = r"000000"
dbdata = "zt"
# 打开数据库连接
db = MySQLdb.connect(dbip,dbuser,dbpwd,dbdata )
# 使用cursor()方法获取操作游标
cursor = db.cursor()
try:
# 执行sql语句
sqls="SELECT a.zsid , a.uri_path , a.uri_htm , a.www_uri_path, a.www_uri_htm , a.inum from article_pathzsq a where a.isflag=0 LIMIT 10;"
cursor.execute(sqls)
results = cursor.fetchall()
except:
print("读取失败")
# 关闭数据库连接
db.close()
for row in results:
zsid = row[0]
uri_path = row[1]
uri_htm = row[2]
www_uri_path = row[3]
www_uri_htm = row[4]
inum = row[5]
# 打印结果
"""
print(" zsid= %d , uri_path= %s , uri_htm= %s ,www_uri_path= %s , www_uri_htm= %s ,inum= %s " % \
(zsid, uri_path, uri_htm, www_uri_path, www_uri_htm, inum))
"""
uri_ps = 'cp ' + uri_path + uri_htm + ' ' + uri_path + inum
print(uri_ps)
#os.system(uri_ps)
wwwuri_ps = 'cp ' + www_uri_path + www_uri_htm + ' ' + www_uri_path + inum
print(wwwuri_ps)
#os.system(wwwuri_ps)

















 661
661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









