







简介:本文详细介绍了在Java中使用反射机制实现深度拷贝的方法和注意事项。深度拷贝能创建一个包含所有引用对象的新对象,避免了修改副本影响原始对象的问题。文章解释了浅拷贝与深度拷贝的区别,以及如何利用Java的反射机制来实现深度拷贝,并阐述了其优缺点。同时,也提到了通过序列化反序列化和第三方库实现深度拷贝的其他方法。 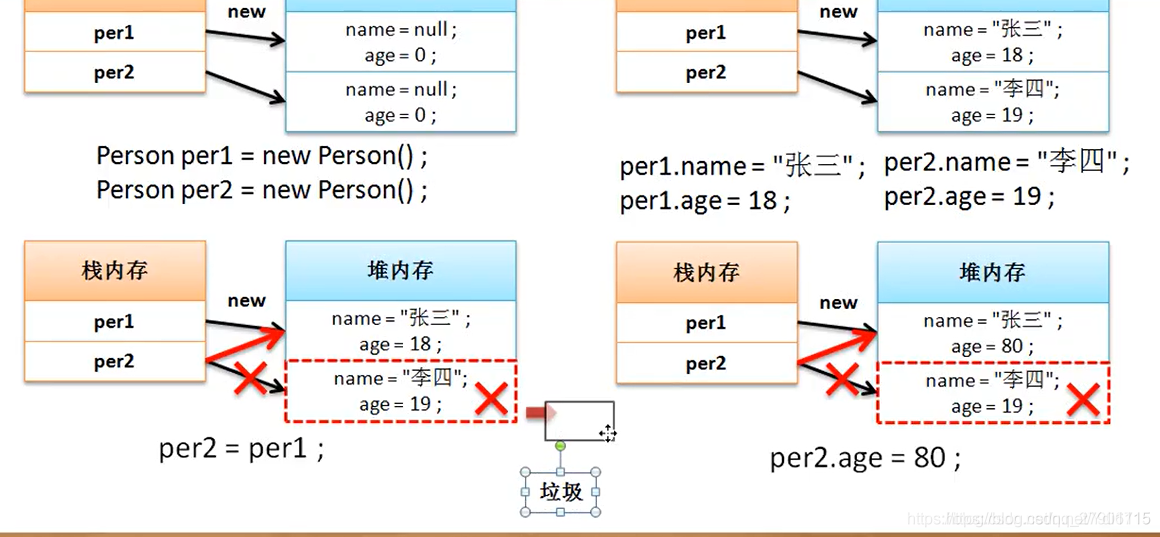
1. Java深度拷贝与浅拷贝概念
1.1 Java中拷贝类型简介
在Java中,对象拷贝分为两种类型:浅拷贝(Shallow Copy)和深度拷贝(Deep Copy)。浅拷贝仅复制对象的引用,而深度拷贝则复制对象本身及其所有的子对象。理解这两者的区别对于掌握对象的复制行为至关重要。
1.2 浅拷贝的影响与适用场景
浅拷贝在需要节约内存且对象结构简单的情况下比较适用。例如,对象中只包含基本类型和不可变对象(如String),那么浅拷贝就足够使用,无需复杂的复制操作。然而,如果对象中包含可变引用类型,浅拷贝将导致原始对象和克隆对象间互相影响。
1.3 深度拷贝的必要性
在复杂对象的处理中,深度拷贝显得尤为重要。它能够确保对象间的独立性,避免一个对象的改变影响到另一个对象。例如,在图形界面设计、数据备份或某些算法中,为了保证数据的一致性和独立性,深度拷贝是必须的。尽管它需要更多的资源和处理时间,但为了系统的稳定性和可预测性,这种开销是值得的。
通过以上章节内容,我们可以为接下来探讨如何利用Java的反射机制、序列化和第三方库实现深度拷贝奠定基础,并且为读者提供一个清晰的框架,以理解深度拷贝的重要性和实现方法。
2. 反射机制在深度拷贝中的应用
2.1 反射机制基本原理
2.1.1 反射的概念与作用
在Java中,反射(Reflection)是一个强大的工具,它允许程序在运行时访问和修改类的行为。通过反射,可以在运行时创建对象、访问和调用对象的方法、获取和设置字段的值,甚至是修改类文件本身。反射在深度拷贝中的作用至关重要,因为它允许我们动态地访问和操作对象的内部状态,这对于实现深度拷贝是必不可少的。
反射提供了一种机制,可以检查、修改和创建类的内部属性,这些功能在没有反射的情况下是不可能的,或者至少会非常不方便。在深度拷贝的上下文中,反射能够帮助我们遍历对象的属性,包括私有属性,并且能够复制对象的所有层级结构。
2.1.2 Java中的反射API
Java中的反射API是实现反射功能的核心,它包含在 java.lang.reflect 包中。主要的类和接口包括:
-
Class: 表示类的类型信息。 -
Field: 表示类的字段(成员变量)。 -
Method: 表示类的方法。 -
Constructor: 表示类的构造器。 -
Array: 提供动态创建和访问Java数组的方法。
使用这些API,我们可以编写程序代码来动态地访问类的私有字段和方法,而无需事先知道这些字段和方法的具体信息。在实现深度拷贝时,这一点尤为重要,因为它允许复制器访问那些通常无法直接访问的私有字段,实现对象图的完整复制。
2.2 反射在对象复制中的角色
2.2.1 对象状态的动态访问
在深度拷贝的过程中,对象的状态需要被完整地复制,这包括对象的公开字段、受保护字段以及私有字段。通过反射,我们可以绕过访问控制,直接读取和修改这些字段的值,这对于复制那些不可变对象或者包含大量私有字段的复杂对象尤其重要。
2.2.2 字段值的读取和设置
使用Java反射API中的 Field 类,我们可以实现字段值的读取和设置。这一过程分为几个步骤:
- 获取字段对象:通过
Class类的getField或getDeclaredField方法,我们可以获取到想要访问的字段对象。 - 获取和设置字段值:通过
Field对象的get(Object obj)和set(Object obj, Object value)方法,我们可以获取和设置字段的值。
通过这样的机制,即使对象的字段被声明为私有,我们也可以动态地复制它们的值,实现深度拷贝。
反射实现深度拷贝的代码实践
3.2.1 创建拷贝方法的步骤
要使用反射实现一个通用的深度拷贝方法,我们通常需要以下步骤:
- 获得待复制对象的类类型信息,通过调用对象的
getClass()方法。 - 遍历对象的所有字段,包括私有字段,使用
getDeclaredFields()方法。 - 为每个字段创建一个新的对象实例,如果字段是对象类型,则递归地进行深度复制。
- 将源对象的字段值复制到新对象中,使用
setAccessible(true)使得私有字段可访问,并用set(Object obj, Object value)方法进行赋值。 - 返回复制后的新对象。
3.2.2 代码示例与解析
import java.lang.reflect.Field;
import java.lang.reflect.InvocationTargetException;
public class DeepCopyUtil {
public static <T> T deepCopy(T obj) {
T copyObj = null;
try {
Class<?> clazz = obj.getClass();
copyObj = (T) clazz.newInstance(); // 创建实例
Field[] fields = clazz.getDeclaredFields();
for (Field field : fields) {
field.setAccessible(true); // 忽略访问权限,直接访问
Field copyField = clazz.getDeclaredField(field.getName());
copyField.setAccessible(true);
Object value = field.get(obj); // 获取原对象字段值
if (value != null) {
copyField.set(copyObj, value); // 设置复制对象字段值
}
}
} catch (InstantiationException | IllegalAccessException | NoSuchFieldException | SecurityException | IllegalArgumentException | InvocationTargetException e) {
e.printStackTrace();
}
return copyObj;
}
}
代码逻辑分析
-
Class<?> clazz = obj.getClass();:获取待复制对象的类类型。 -
copyObj = (T) clazz.newInstance();:创建一个新的实例,用于存放复制的数据。 -
Field[] fields = clazz.getDeclaredFields();:获取目标对象的所有字段,包括私有字段。 -
field.setAccessible(true);:忽略Java的访问权限控制,允许访问私有字段。 -
field.get(obj);:读取当前字段的值。 -
copyField.set(copyObj, value);:将读取到的值设置到复制的对象字段中。
以上代码展示了如何使用反射API实现对象的深度复制。这种方法在复杂的对象图中尤其有用,因为它可以处理任意结构的对象,而不需要为每种类型的对象编写特定的复制代码。然而,需要注意的是,反射操作可能会降低性能,并且增加了出错的可能性,因为任何在运行时发生的异常都可能导致程序崩溃。因此,在使用反射时,必须要小心处理可能出现的 NoSuchFieldException 、 IllegalAccessException 等异常。
3. 利用反射实现深度拷贝的步骤
3.1 深度拷贝的流程概述
3.1.1 检测对象属性类型
在执行深度拷贝前,首先要理解对象的结构,包括它的属性和这些属性的数据类型。在Java中,反射机制使得我们可以动态地检测一个对象的属性类型,包括它持有的类的字段信息。通过 java.lang.reflect 包下的类,如 Field ,我们可以访问这些属性,无论它们是公共的、受保护的还是私有的。
对于包含复杂数据结构的对象,比如有对象属性的对象,我们需要递归地检测这些属性的类型,以确保深度拷贝的准确性。
Field[] fields = obj.getClass().getDeclaredFields();
for (Field field : fields) {
field.setAccessible(true); // 允许访问私有字段
Class<?> fieldType = field.getType();
// 处理不同类型的字段
// ...
}
3.1.2 遍历对象图并复制
深度拷贝的关键在于递归遍历对象图,复制每一个对象以及它包含的所有子对象。这个过程涉及到识别对象类型并调用相应类型的拷贝构造器或实现拷贝逻辑。对于基本数据类型和不可变对象(如String),可以直接赋值,对于可变对象,则需要使用反射API来复制。
递归拷贝的一个简单实现如下:
public static Object deepCopy(Object obj) throws Exception {
if (obj == null) {
return null;
}
Class<?> clazz = obj.getClass();
if (clazz.isPrimitive() || clazz == String.class) {
return obj;
} else if (clazz.isArray()) {
// 处理数组类型
// ...
} else if (Collection.class.isAssignableFrom(clazz)) {
// 处理集合类型
// ...
} else {
// 处理自定义对象类型
Object copyObj = clazz.newInstance();
Field[] fields = clazz.getDeclaredFields();
for (Field field : fields) {
field.setAccessible(true);
Object value = field.get(obj);
if (field.getType().isPrimitive() || field.getType() == String.class) {
field.set(copyObj, value);
} else {
field.set(copyObj, deepCopy(value));
}
}
return copyObj;
}
return null;
}
3.2 反射实现深度拷贝的代码实践
3.2.1 创建拷贝方法的步骤
实现深度拷贝的方法主要包含以下几个步骤:
- 检查传入对象是否为null,如果是,则直接返回null。
- 获取对象的类对象,并检查是否为基本数据类型、字符串或不可变对象,对于这些类型直接返回原对象。
- 对于数组和集合类型,需要单独处理,复制其中的元素。
- 对于自定义对象类型,通过反射遍历其字段,并递归调用
deepCopy方法来复制字段值。 - 最后,返回新构建的对象。
3.2.2 代码示例与解析
下面是一个使用Java反射机制实现深度拷贝的完整示例代码:
public class DeepCopyUtil {
public static Object deepCopy(Object obj) throws Exception {
if (obj == null) {
return null;
}
Class<?> clazz = obj.getClass();
if (clazz.isPrimitive() || clazz == String.class) {
return obj;
} else if (clazz.isArray()) {
Class<?> componentType = clazz.getComponentType();
int length = Array.getLength(obj);
Object copyArray = Array.newInstance(componentType, length);
for (int i = 0; i < length; i++) {
Object item = Array.get(obj, i);
Array.set(copyArray, i, deepCopy(item));
}
return copyArray;
} else if (Collection.class.isAssignableFrom(clazz)) {
Collection<?> collection = (Collection<?>) obj;
Collection<Object> copyCollection = (Collection<Object>) clazz.newInstance();
for (Object item : collection) {
copyCollection.add(deepCopy(item));
}
return copyCollection;
} else {
Object copyObj = clazz.newInstance();
Field[] fields = clazz.getDeclaredFields();
for (Field field : fields) {
field.setAccessible(true);
Object value = field.get(obj);
if (field.getType().isPrimitive() || field.getType() == String.class) {
field.set(copyObj, value);
} else {
field.set(copyObj, deepCopy(value));
}
}
return copyObj;
}
}
}
对于上述代码中的每个步骤,都有相应的逻辑来处理不同类型的数据。对于数组和集合类型,需要特别注意在复制时同样需要深度拷贝数组或集合内部的元素。对于自定义对象类型,通过获取字段值,然后递归调用 deepCopy 方法实现深度拷贝。
这种方法的优点是通用性强,能够处理任意类型的Java对象。然而,使用反射可能会略微降低性能,并且需要处理异常。此外,对于循环引用的处理,需要在具体实现中额外注意,以避免造成无限递归。
在实际使用中,应当根据对象的具体类型和结构,适当调整深度拷贝的实现策略,以获得最优的性能。
4. 深度拷贝的优势与性能考量
4.1 深度拷贝与浅拷贝的比较
4.1.1 场景应用对比
深度拷贝和浅拷贝在实际应用中各有其适用场景。浅拷贝通常适用于对象的属性为基本数据类型,或者开发者确定只需要复制对象引用时。例如,在一些配置对象或临时对象的复制中,浅拷贝可以快速完成复制任务,且不影响程序性能。
相对地,深度拷贝适用于对象包含复杂的引用结构,如对象中还包含其他对象或者集合等情况。在需要完全独立复制一个对象,保证原对象和复制对象之间相互不影响时,深度拷贝显得尤为重要。例如,在图形界面的复制粘贴功能,或是在业务逻辑中需要复制复杂数据结构进行处理时。
在应用深度拷贝时,必须确保所有相关的对象都被正确复制,否则可能会导致引用循环等问题,尤其是在包含双向引用的对象图中。开发者需要仔细设计对象的复制逻辑,确保复制过程的准确性和完整性。
4.1.2 内存使用分析
从内存使用的角度来看,浅拷贝由于仅复制对象的引用,因此在内存使用上比较节省。对于简单的对象或者属性数量较少的对象,浅拷贝通常是一种高效的选择。
而深度拷贝由于需要复制对象的所有属性,包括嵌套的对象,因此在内存消耗上相对较大。特别是当对象图非常复杂或者对象数量庞大时,深度拷贝可能会消耗大量的内存资源。然而,深度拷贝的优势在于复制后的对象是完全独立的,这为对象状态的管理提供了很大的便利。
在某些情况下,如果对象图中存在大量重复对象,深度拷贝可能会导致不必要的内存浪费。因此,在处理这类问题时,开发者需要权衡利弊,考虑使用对象池或者克隆库等其他策略来优化内存使用。
4.2 深度拷贝的性能影响
4.2.1 执行效率考量
深度拷贝的执行效率与其复制的对象结构复杂度成正比。对于简单的对象,深度拷贝可能仅需几微秒到几毫秒的时间。但是,对于具有复杂嵌套结构和大量对象的对象图,深度拷贝的执行时间可能会上升到几十甚至几百毫秒。
在实际的性能优化中,开发者可以利用并行处理、缓存和池化等技术来提高深度拷贝的执行效率。例如,对于已经复制过一次的对象,可以通过缓存来避免重复的复制工作,而并行处理可以针对对象图的不同部分同时进行复制操作,以提高整体效率。
4.2.2 优化策略探讨
深度拷贝的优化策略可以从多个角度进行考量。一种常见的优化方式是使用原型模式,将对象的复制操作封装在一个原型接口中,这样可以将复制的细节隐藏起来,使得外部调用者无需关心具体的复制逻辑。
针对序列化的深度拷贝实现,可以优化序列化和反序列化过程中的性能瓶颈。例如,通过自定义序列化过程来排除不需要序列化的字段,或者使用高效的序列化框架如Kryo来提升性能。
此外,深度拷贝的性能优化也可以从JVM层面上进行,比如通过调整垃圾回收策略来减少因深度拷贝导致的内存分配和回收开销。在某些极端情况下,如果深度拷贝是性能瓶颈,可能需要对对象图结构进行重构,以简化复制过程。
为了详细说明深度拷贝的性能优化策略,以下是一个使用Java中的 clone() 方法实现深度拷贝并进行性能优化的示例代码,其中包含了详细的逻辑分析和参数说明。
public class DeepCloneable implements Cloneable {
private List<DeepCloneable> childList;
// Default constructor
public DeepCloneable() {
this.childList = new ArrayList<>();
}
// Getter and setter for childList
@Override
protected DeepCloneable clone() throws CloneNotSupportedException {
DeepCloneable clone = (DeepCloneable) super.clone();
clone.childList = new ArrayList<>();
for (DeepCloneable child : this.childList) {
// Deep copy each element of the list
clone.childList.add(child.clone());
}
return clone;
}
}
public class PerformanceTest {
public static void main(String[] args) throws Exception {
List<DeepCloneable> originalList = generateBigList(1000); // Generates a list with 1000 items
long startTime = System.nanoTime();
for (int i = 0; i < 1000; i++) {
DeepCloneable clonedList = originalList.get(0).clone();
}
long endTime = System.nanoTime();
System.out.println("Time taken for 1000 deep clones: " + (endTime - startTime) + " ns");
}
private static List<DeepCloneable> generateBigList(int size) {
List<DeepCloneable> list = new ArrayList<>();
for (int i = 0; i < size; i++) {
DeepCloneable item = new DeepCloneable();
item.getChildList().add(new DeepCloneable()); // Adding one child to each item
list.add(item);
}
return list;
}
}
在上述代码中,我们定义了一个 DeepCloneable 类,该类可以被克隆并执行深度拷贝。在克隆方法中,我们对列表中的每个子项进行了深拷贝。 PerformanceTest 类中我们生成了一个包含大量对象的列表,并计时执行1000次深度拷贝操作,从而得到深度拷贝的性能指标。
为了进一步提升性能,我们可以考虑以下优化策略: 1. 使用 CopyOnWriteArrayList 来代替普通的 ArrayList ,它可以减少同步开销,适合于读多写少的场景。 2. 在深度拷贝过程中,如果是可变对象,则考虑对象的不可变性,这样可以避免不必要的深度拷贝。 3. 对于序列化深度拷贝实现,可以通过使用更高效的序列化工具或者自定义序列化逻辑来提升性能。
最后,优化深度拷贝的性能不应以牺牲代码的可维护性和清晰性为代价。开发者应当通过测试和监控来确保优化措施有效,并且对整个系统的影响最小。
5. 序列化反序列化方法实现深度拷贝
序列化是Java中将对象状态信息转换为可以保存或传输的形式的过程,在这个过程中,对象被转换成了一系列的字节,这些字节可以被写入文件、存储到数据库或者通过网络传输到另一个网络节点。反序列化则是序列化的逆过程,它将这些字节重新构造成原始对象。利用序列化与反序列化技术,我们可以实现对象的深度拷贝,即复制一个对象的同时复制其内部所有成员对象。
5.1 Java序列化技术介绍
5.1.1 序列化的基本概念
序列化机制允许Java对象在需要的时候被转换成字节流,这个过程通常称为对象的序列化。当这些字节流被存储后,它们可以在需要的时候重新转换成原始对象,这个过程称为反序列化。在Java中,只要类实现了 java.io.Serializable 接口,该类的对象就可以被序列化。
5.1.2 序列化的API使用
序列化和反序列化主要涉及到 ObjectOutputStream 和 ObjectInputStream 两个类。 ObjectOutputStream 用于将对象序列化到输出流中,而 ObjectInputStream 用于从输入流中反序列化出对象。在使用时,需要注意的是,如果对象图中包含了未实现 Serializable 接口的对象,那么在序列化过程中会抛出 NotSerializableException 异常。
import java.io.*;
public class SerializationUtil {
public static void serialize(Object obj, String filePath) throws IOException {
try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(filePath))) {
oos.writeObject(obj);
}
}
public static Object deserialize(String filePath) throws IOException, ClassNotFoundException {
try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream(filePath))) {
return ois.readObject();
}
}
}
5.2 利用序列化实现深度拷贝
5.2.1 序列化拷贝的实现步骤
要通过序列化实现深度拷贝,可以按照以下步骤进行:
- 确保需要拷贝的对象所属的类实现了
Serializable接口。 - 使用
ObjectOutputStream将对象序列化到一个ByteArrayOutputStream中。 - 从
ByteArrayOutputStream中获取序列化后的字节数据。 - 使用
ByteArrayInputStream将字节数据反序列化成原始对象的副本。
5.2.2 示例代码与分析
import java.io.*;
public class DeepCopySerializable {
public static <T> T deepCopy(T object) {
try {
// 序列化对象到字节数组
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(object);
oos.flush();
// 反序列化字节数组到新的对象
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bis);
return (T) ois.readObject();
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
return null;
}
}
public static void main(String[] args) {
// 示例对象序列化和反序列化
SomeClass original = new SomeClass("Original value");
SomeClass copied = deepCopy(original);
System.out.println(copied); // 输出: SomeClass{value='Original value'}
}
}
class SomeClass implements Serializable {
private String value;
public SomeClass(String value) {
this.value = value;
}
// 省略getter和setter方法
}
通过上述代码,我们实现了一个通用的深度拷贝方法 deepCopy ,它接受一个实现了 Serializable 接口的对象,返回该对象的一个深拷贝副本。这个方法的关键在于字节流的使用,它允许我们绕过直接访问对象内部成员的方式,通过流的方式进行对象的完整复制。
简介:本文详细介绍了在Java中使用反射机制实现深度拷贝的方法和注意事项。深度拷贝能创建一个包含所有引用对象的新对象,避免了修改副本影响原始对象的问题。文章解释了浅拷贝与深度拷贝的区别,以及如何利用Java的反射机制来实现深度拷贝,并阐述了其优缺点。同时,也提到了通过序列化反序列化和第三方库实现深度拷贝的其他方法。

















 4110
4110

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









