



 本文介绍了一个使用Python进行新浪博客爬取的例子,包括单页和多页的爬取过程及遇到的问题,如多余数据和乱码输出等,并提供了相应的解决方案。
本文介绍了一个使用Python进行新浪博客爬取的例子,包括单页和多页的爬取过程及遇到的问题,如多余数据和乱码输出等,并提供了相应的解决方案。
博客地址:http://blog.sina.com.cn/s/articlelist_1191258123_0_1.html
爬第一页博文
1 #-*-coding:utf-8-*- 2 import re
#导入正则表达式模块 3 import urllib
#导入urllib库 4 5 url='http://blog.sina.com.cn/s/articlelist_1191258123_0_1.html'
#第一页博文地址
6 response = urllib.urlopen(url)
#通过urllib库中的urlopen()函数来访问这个url
#这里省略了构建request请求这一步
7 html = response.read()
#读取出来存在html这个变量当中,到这里也就完成了html的爬取
8 #print(html) 9 #这里可以将爬取到的html输出到终端 10 pattern = re.compile('<a title=.*?href=(.*?)>(.*?)</a>',re.S)
#通过正则表达式来匹配 11 blog_address = re.findall(pattern,html)
#通过findall函数从爬取到的html中找出所要的内容 12 for i in blog_address: 13 print(i[0])
#输出第一个分组的内容即博客博文地址 14 print(i[1])
#输出第二个分组的内容即博文标题
部分结果如下:
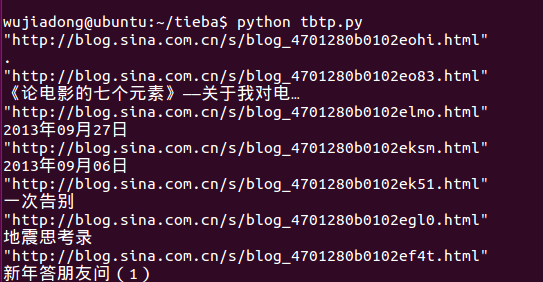
所遇到的问题:1爬取的结果多了两个,第一个和最后一个不是所要的内容?
2 输出结果的时候用print(i[0],i[1])出现乱码,这是为什么?
通过while循环来解决多页的问题
1 #-*-coding:utf-8-*- 2 import re 3 import urllib 4 page=1 5 while page<=7: 6 url='http://blog.sina.com.cn/s/articlelist_1191258123_0_'+str(page)+'.html' 7 #url='http://blog.sina.com.cn/s/articlelist_1191258123_0_1.html' 8 response = urllib.urlopen(url) 9 html = response.read().decode('utf-8') 10 #print(html) 11 pattern = re.compile('<a title=.*?target=.*?href=(.*?)>(.*?)</a>',re.S) 12 blog_address = re.findall(pattern,html) 13 for i in blog_address: 14 print(i[0]) 15 print(i[1]) 16 page = page + 1
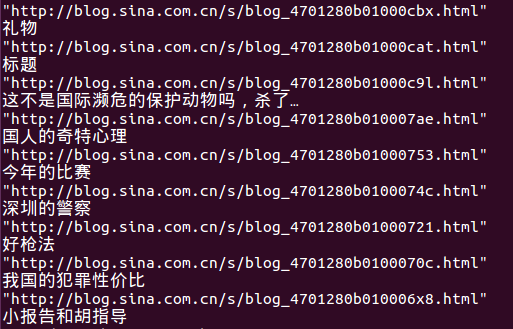
结果最后部分如下图:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









