



python自动化运维之路~DAY3
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.函数
1.函数是什么?
函数一词来源于数学,但编程中的「函数」概念,与数学中的函数是有很大不同的,具体区别,我们后面会讲,编程中的函数在英文中也有很多不同的叫法。在BASIC中叫做subroutine(子过程或子程序),在Pascal中叫做procedure(过程)和function,在C中只有function,在Java里面叫做method
定义: 函数是指将一组语句的集合通过一个名字(函数名)封装起来,要想执行这个函数,只需调用其函数名即可
2.函数的特点:
- 减少重复代码
- 使程序变的可扩展
- 使程序变得易维护
3.返回值
要想获取函数的执行结果,就可以用return语句把结果返回
注意:
- 函数在执行过程中只要遇到return语句,就会停止执行并返回结果,so 也可以理解为 return 语句代表着函数的结束
- 如果未在函数中指定return,那这个函数的返回值为None
下面让我们一起看看函数吧:
#!/usr/bin/env python
#_*_coding:gbk _*_
#__author__ = "yinzhengjie"
import time
# #定义一个函数
# def fun():
# '''tesing'''
# print('in the func1')
# return 100
# #定义一个过程(没有返回值)
# def fun2():
# print('in the func2')
# #调用函数
# x=fun()
# y=fun2()
#
# print("from fun return is %s" % x) #如果是函数的话就会有返回值,此处会返回100
# print("from fun2 return is %s" % y) #如果是过程的话就没有返回值,python解释器会默认返回None
#
#打印日志的格式的函数
# def logger():
# time_format = '%Y-%m-%d %X' #定义时间的格式
# time_current = time.strftime(time_format) #利用time模块的strftime,将日期按照之前定义好的time_format形式打印出来!
# with open('a.txt','a+') as f:
# f.write('%s end action\n' %time_current)
# logger()
# #函数参数及调用
# def test(x,y): #x,y表示位置参数
# print(x) #此处的x表示形式参数
# print(y) #此处的y表示形式参数
# # test(100,200) #100,200这个参数表示实际参数【位置参数调用】
# # test(y=100,x=200) #【关键字调用】
# test(3,y=2) #关键字调用也可以这么写,需要一一对应的哟
# #
# def test2(x,y,z):
# print(x)
# print(y)
# print(z)
# test2(33,z=200,y=300) #位置参数和关键字调用可以这样用,但是要注意!位置参数要放在关键字参数的前面哟!换句话说就是关键字参数要放在位置参数的后面,然后后面的所有关键字参数可以无序的传参数。
#默认参数的用途:1.定义程序的安装路径;2.定义数据库连接时的端口等等。
# def test(x,y=2): #我们可以定义一个默认参数,调用这个函数的时候,默认参数非必须传递,如果传递参数就会打印传递的参数,如果不传递参数就打印默认的参数;
# print(x)
# print(y)
# test(100,3)
# test(100)
#
#以上定义的参数都存在bug,比如我们在传参的时候多传递或者少传递参数都会导致程序脚本报错!因此我们就可以定义一个参数组,用于传递参数不固定的时候!
# def test3(*args): #定义一个参数组,当调用该函数的时候传入的实际参数会自动将其变成一个tuple[接受N个位置参数,转换成元组的形式]
# print(args)
# test3(1,2,3,4,5,4,5)
# test3(*[100,200,300])
#
# def test4(x,*args): # 定义一个参数组还可以这么写哟
# print(x)
# print(args)
# test4(100,2,3,4,5)
# def test5(**kwargs): #接受N个关键字参数,转换成字典的方式,
# print(kwargs)
# test5(name="尹正杰",age=26,set="man") #传递的参数相当于key和value哟
#
# def test6(name,age=25,*args,**kwargs): #参数组要放在位置参数合默认参数之后,不然会报错的哟!
# print(name)
# print(age)
# print(args)
# print(kwargs)
# test6("尹正杰",18,hobby='basketball') #用位置参数传参
# test6(name="yinzhengjie",hobby="ping-pong",age=20) #用关键字参数传参
# test6("尹正杰",100,800,900,1000,sex="man") #注意我再次传的第二个参数"100"是上面"age"的位置参数所对应的值哟,而后面的"800,900,1000"是给位置参数组传递的哟,最后蚕食给字典参数组传参的
#注意,在函数里面定义的变量属于局部变量,也就是仅仅在函数里面定义的函数呢(我们这里说的对象是:字符串或者是数字)
# name = "尹正杰" #该变量属于全局变量
# print(name)
# def names_info():
# name = "yinzhengjie" #该变量数据局部变量
# print(name)
# names_info()
# print(name) #全局和局部变量都有相同的变量的时候,是全局的变量生效的哟~
#当然如果你必须要讲局部变量在全局变量生效的话也是可以的,需要用“global”声明一下:但是这种方法知道就好!不要用!不要用!不要用!重要的事情说三遍!,不要在函数里面改全局变量!(我们这里说的对象是:字符串或者是数字)
# age = 18
# print(age)
# def age_info():
# global age #声明这个变量,让其成为全局变量!如果没有这个变量,就会新建这个变量,使其成为全局变量,这种方法千万别用,如果你的代码有几千行,你每次都这么改的话,如果你在其他的函数用到这个变量的话会让你的拍错难度加大N倍!不管全局是否有这个变量,都尽量不要这么用,我们可以看明白别人这么用是怎么回事就好,哈哈!
# age = 200
# print(age)
# age_info()
# print(age)
#上面我们说了数字或者字符串定义了全局变量,如果局部变量没有使用global声明的话就不能修改全局变量,那么像比较复杂一点的对象就可以修改,比如字典,列表,集合,类等数据结构!.
# names = ["yin_zheng_jie","尹正杰","尹_正_杰"]
# print(names)
# def chage_name():
# names[0] = "灵魂摆渡"
# print("inside func",names)
# chage_name()
# print(names)
#递归函数:在函数内部,可以调用其他函数,如果一个函数在内部调自身本身,这个函数就是递归函数。
#递归特性:
#1.必须有一个明确的结束条件(最大的递归次数应该是999次)
#2.每次进入更深一层递归时,问题规模相比上次递归都应有所减少
#3.递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈[stack]这种数据结构实现的,每次进入一个函数调用,栈就会增加一层栈帧,每当还输返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以递归次数过多,会导致栈溢出的哟~)
# def calc(n):
# print(n)
# if int(n/2) > 0:
# return calc(int(n/2))
# print("--》",n)
# calc(10)
#有可能你听过函数式编程(学函数式编程建议用:lisp,hashshell,erlang),不建议用Python写函数式编程,尽管用python可以这么干,我们下面举个最简单的例子你就不想这么干了,哈哈
#比如我们先要计算:(30+40)*2-50
#传统的过程式编程,可能这样写:
# var a=30+40;
# var b=a*3;
# var c=b-4
#函数式编程要求使用函数,我们可以把运算过程定义为不同的函数,然后写成下面这样:
#var result=subtract(multiply(add1,2),3),4);
#高级函数:变量可以指向函数,函数的参数能接受变量,那么一个函数就可以接受另一个函数作为参数,这种函数称之为高阶函数
# def add(a,b,f):
# return f(a) + f(b)
# result=add(3,-7,abs)
# print(result)
#如何将字符串转换成字典"eval()"
#假设有一个字符串name_info,里面的数据格式跟字典如出一辙,如何实现转换呢?
#eval(name_info)
好了,大家学完了函数,让我们一起小试牛刀一下吧:
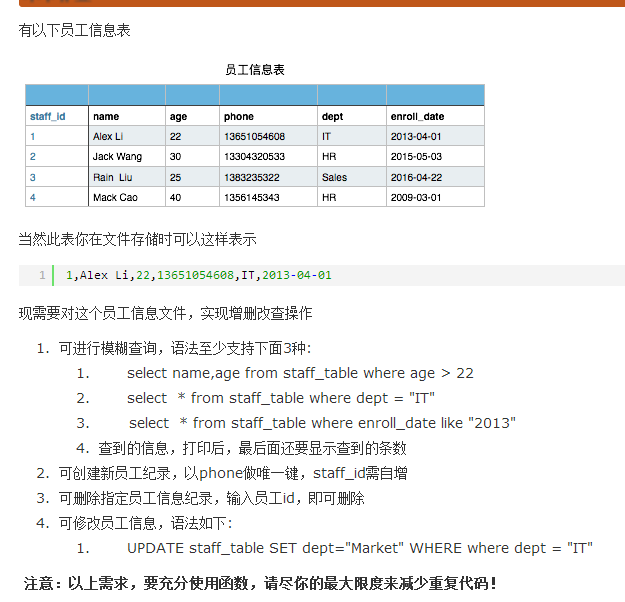
流程图如下:
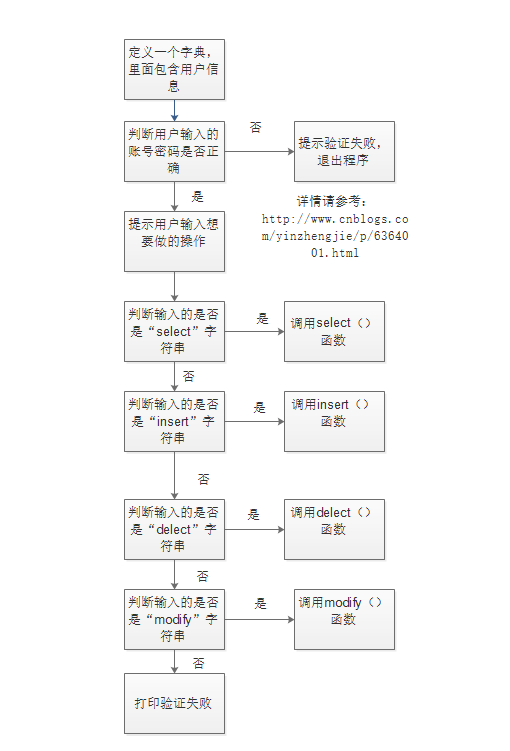
student_info表格信息如下:
staff_id name age phone dept enroll_date commany 1 尹正杰 25 jiubugaosuni IT 2016-7-7 睿智融科 2 灵魂摆渡 100 66666666666 运维 2017-2-3 地府 3 yinzhengjie 18 88888888888 python 2017-2-6 睿智融科 4 alex 38 99999999999 teacher 2017-2-8 老男孩 5 alex 38 99999999999 teacher 2017-2-8 老男孩 6 alex 38 99999999999 teacher 2017-2-8 老男孩
代码使用环境说明:
1 刚刚入门python,只了解简单的文件处理和字符类型,所以写出来的脚本难免会遇到bug,需要按照我给出的语法格式来进行操作哟! 2 说明几点: 3 1.用户和密码可以更改,需要修改我定义的login_info的这个字典; 4 2.删除的时候会新生成了一个文件”new_file“,如果不想要的话,可以用os模块将之前的这个文件os.remove掉,然后在用os,rename改名即可。 5 3.修改的时候我会生成一个modify.txt文件,如果想删除的话也可以用os模块来操作。 6 4.代码很low,大神还是不要看的好~辣眼睛 啊~ 7 5.运行环境是python3.6 8 9 语法格式如下: 10 11 查询: 12 select * from staff_table where phone = "jiubugaosuni" 13 14 15 插入: 16 insert into staff_table values('alex','38','99999999999','teacher','2017-2-8','老男孩') 17 18 19 删除: 20 21 delete from staff_table where id = '1' 22 23 修改: 24 25 UPDATE staff_table SET dept = "Market" where dept = "IT"
代码如下:


1 #!/usr/bin/env python 2 #_*_coding:utf-8_*_ 3 #@author :yinzhengjie 4 #blog:http://www.cnblogs.com/yinzhengjie/tag/python%E8%87%AA%E5%8A%A8%E5%8C%96%E8%BF%90%E7%BB%B4%E4%B9%8B%E8%B7%AF/ 5 #EMAIL:y1053419035@qq.com 6 import os 7 def select(): #我这个函数是用来查询的 8 student_info = [] 9 f = open("student_info", "r", encoding="utf-8") 10 for line in f.readlines(): 11 student_info.append(line.strip()) 12 f.close() 13 user_command = input("Please enter command >>> ").strip().replace("select ", "").replace("from staff_table","").replace("where", "").split() #最终成为了一个list。 14 length = len(user_command) #由于我将输入的字符串都replace(重命名)了,而且按照空格分成了一个list,我统计这个长度,方便下面比较。 15 def accurate_select(header_info): #这里我是单独针对“age”这个字符串做了一个函数,方便我调用。调用的时候需要传一个参数进去,内容很简单就不用说了,相信大家能看懂。 16 exact_match = 0 17 f = open("student_info", "r", encoding="utf-8") 18 for line in f.readlines(): 19 if line.split()[2] == "age": 20 continue 21 elif user_command[2] == ">": 22 if int(line.split()[2]) > int(user_command[3]): 23 print(line.split()[header_info], line.split()[2]) 24 exact_match += 1 25 elif user_command[2] == "<": 26 if int(line.split()[2]) < int(user_command[3]): 27 print(line.split()[header_info], line.split()[2]) 28 exact_match += 1 29 elif user_command[2] == "=": 30 if int(line.split()[2]) == int(user_command[3]): 31 print(line.split()[header_info], line.split()[2]) 32 exact_match += 1 33 f.close() 34 print("seach %s times" % exact_match) 35 def obscure_select(select_command): #这个是我定义了一个模糊查询。 36 student_info = {} 37 f = open("student_info", "r", encoding="utf-8") 38 for line in f.readlines(): 39 staff_id, name, age, phone, dept, enroll_date, commany = line.split() #这个是将每一行切片,并且切片后的值都分别赋值给前面这些变量。 40 student_info[staff_id] = [name, age, phone, dept, enroll_date, commany] #我将这些变量弄成一个字典,方便我后续操作 41 exact_match = 0 #定义一个计数器,请暂时运行我这么叫他,我知道他是个变量,但是他的功能就是给我计数的! 42 for k, v in student_info.items(): #循环这个字典 43 if k.find(select_command) != -1: #这个用到了字符串的find方法,在字典中的KEY中查找是否有这个变量,如果没有查找到的话就会返回“-1”,匹配到了就返回“0” 44 print(k, v) #如果匹配到了就打印key和value 45 exact_match += 1 46 else: 47 for i in v: #同理,我这里是在value中查找关键字 48 if i.find(select_command) != -1: 49 print(k, v) 50 exact_match += 1 51 f.close() 52 return exact_match #我将统计的次数返回 53 def header_judgment(test): #这个函数我是为了解决作业的第二条,精确匹配表头信息,可以精确匹配到第一行对应的所有value哟! 54 exact_match = 0 55 header_information = ["staff_id", "name", "age", "phone", "dept", "enroll_date", "commany"] 56 f = open("student_info", "r", encoding="utf-8") 57 for line in f.readlines(): 58 if user_command[2] == "=": 59 if line.split()[header_information.index(test)] in user_command[3]: #这里判断文件中的当前行是否在用户输入的字符串中存在,如果存在就打印 60 print(line.split()) 61 exact_match += 1 62 elif user_command[2] == "!=": 63 if line.split()[header_information.index(test)] not in user_command[3]: #这个和上面那个想法,打印出不包含用户输入的字符串。 64 if test in line.split(): 65 continue 66 else: 67 print(line.split()) 68 exact_match += 1 69 f.close() 70 return exact_match #返回计数器变量 71 exact_match = 0 72 if user_command[0] == "*" and length == 1: 73 for i in student_info: 74 print(i) 75 exact_match += 1 76 print("seach %s times" % exact_match) 77 elif user_command[0] == "*" and length == 4: 78 exact_match = header_judgment(user_command[1]) #这个地方我是调用了我上面定义的那个函数,我在这里被坑了半小时,不能直接调用,而是要将调用的结果赋值给一个变量,不然无法得到return的返回值。 79 if user_command[2] == "like": 80 obscure_match = user_command[3].strip("\"") 81 exact_match = obscure_select(obscure_match) 82 print("seach %s times" % exact_match) 83 elif user_command[0].replace(",", " ").split()[0] == "staff_id" and length == 4: 84 accurate_select(0) 85 elif user_command[0].replace(",", " ").split()[0] == "name" and length == 4: 86 accurate_select(1) 87 elif user_command[0].replace(",", " ").split()[0] == "phone" and length == 4: 88 accurate_select(3) 89 elif user_command[0].replace(",", " ").split()[0] == "dept" and length == 4: 90 accurate_select(4) 91 elif user_command[0].replace(",", " ").split()[0] == "enroll_date" and length == 4: 92 accurate_select(5) 93 else: 94 print("Sorry,the format you entered is a problem!!!") 95 def insert(): #这个函数我是插入一条数据 96 user_command = input("Please enter command >>> ").strip().replace("insert into staff_table values", "").strip("(')").replace("'", "").split(",") 97 f = open("student_info", "r+", encoding="utf-8") 98 def file_insert(): 99 for line in f.readlines(): 100 global student_id #这里我是声明一个全局变量 101 student_id = line.strip()[0] #这个是我将用户输入的每一行的第一列取出来 102 if student_id.isdigit(): #判断取出来的数据是否为数字,因为我的第一行不是数字,而是表头信息。 103 student_id = int(student_id) #如果是数字的话我就转换成int类型。 104 return student_id #返回这个数字 105 student_id = "\t" + str(file_insert() + 1) + "\t\t" #我调用上面定义的函数,并且将数字加1,为了就是自增的意思!然后再将他转换成字符串,然后两边根据情况打赢空格。 106 student_info = "\t\t".join(user_command) #这个是用到了字符串的一个方法,我将一个列表中的每个元素直接加上两个tab键,并将结果返回给一个变量。 107 f.write("\n") 108 f.write(student_id + student_info) #最终将自增的数字和用户输入的信息添加到表中。 109 def delect(): #这个是我定义删除字符串的方式,会将修改后的数据存入一个新的文件中 110 user_command = input("Please enter command >>> ").strip().replace("delete from staff_table where", "").replace("'", "").split(",") 111 user_command = " ".join(user_command).split() #这个是我将用户输入的字符串字符串的数据进行处理,将列表中的第一个元素又重新划分了一个新的元素 112 if user_command[2].isdigit(): 113 user_command[2] = int(user_command[2]) 114 f = open("student_info", "r+", encoding="utf-8") 115 f_new = open("new_file", "w+", encoding="utf-8") 116 def delete_str(): 117 for line in f.readlines(): 118 student_id = line.split()[0] 119 if student_id.isdigit(): 120 student_id = int(student_id) 121 if user_command[2] == student_id: 122 continue 123 f_new.write(line.strip()) 124 f_new.write("\n") 125 # for line in f_new.readlines(): #这段代码我是为了实现自动修改前面文件的ID,目前卡主了,暂时不动用 126 # sequence_id = line.split()[0] 127 # id_num = 1 128 # str_id = str(id_num) 129 # modify_str = line.replace(sequence_id,str_id) 130 # id_num += 1 131 # f_new.write(modify_str) 132 delete_str() 133 f.close() 134 f_new.close() 135 # os.remove("student_info") #这个步骤是删除源文件 136 # os.rename("new_file","student_info") #将修改后的文件成删除的文件 137 def modify(): #这个是我定义修给的函数,按照固定格式修改文件后, 138 user_command = input("Please enter command >>> ").strip().replace("UPDATE staff_table SET", "").strip("(')").replace("where", "").replace("'","").replace("=", "").split() 139 f = open("student_info", "r", encoding="utf-8") 140 f_new = open("modify.txt", "w+", encoding="utf-8") 141 for line in f.readlines(): 142 if user_command[0] == "dept" and user_command[2] == "dept": 143 a = user_command[3].strip("\"") 144 b = user_command[1].strip("\"") 145 if a in line.strip(): 146 line = line.replace(a, b).strip() 147 f_new.write(line.strip()) 148 f_new.write("\n") 149 f_new.flush() 150 f.close() 151 f_new.close() 152 # os.rename("modify.txt","student_info") 153 Prompt = [ 154 ("select"), 155 ("insert"), 156 ("delete"), 157 ("modify") 158 ] 159 login_info = {"yinzhengjie":"123"} #定义一个用户登录信息。 160 username = str(login_info.keys()).replace("dict_keys(['","").replace("'])","") #将字典中的key取出来。 161 password = login_info.get("yinzhengjie") 162 login_DB_username = input("Please enter login information,please enter username:") 163 login_DB_password = input("Please enter lonin infor mation please enter password:") 164 if login_DB_username == username and login_DB_password == password: #如果验证成功就执行代码。 165 while True: 166 for index, item in enumerate(Prompt): 167 index = index + 1 168 print(index, item) 169 choose = input("what do you want to do?").strip() 170 if choose == "select" or choose == "1": 171 select() 172 elif choose == "insert" or choose == "2": 173 insert() 174 elif choose == "delete" or choose == "3": 175 delect() 176 elif choose == "modify" or choose == "4": 177 modify() 178 else: 179 print("您输入的字符串有问题哟!请输入:‘select’,'insert','add','modify'或者输入与其对应的数字") 180 else: 181 print("Sorry,login failed ,exit program!")
测试结果如下:
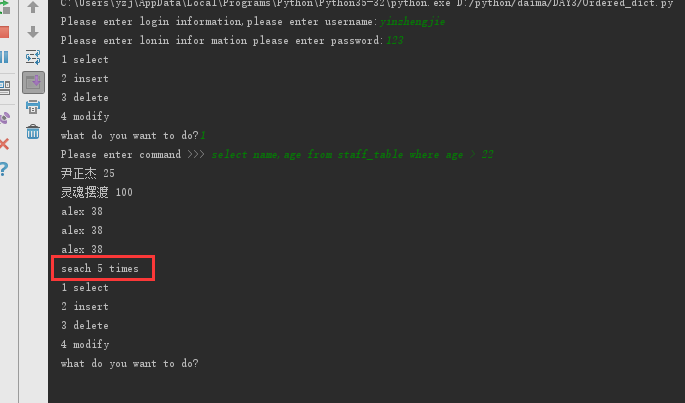
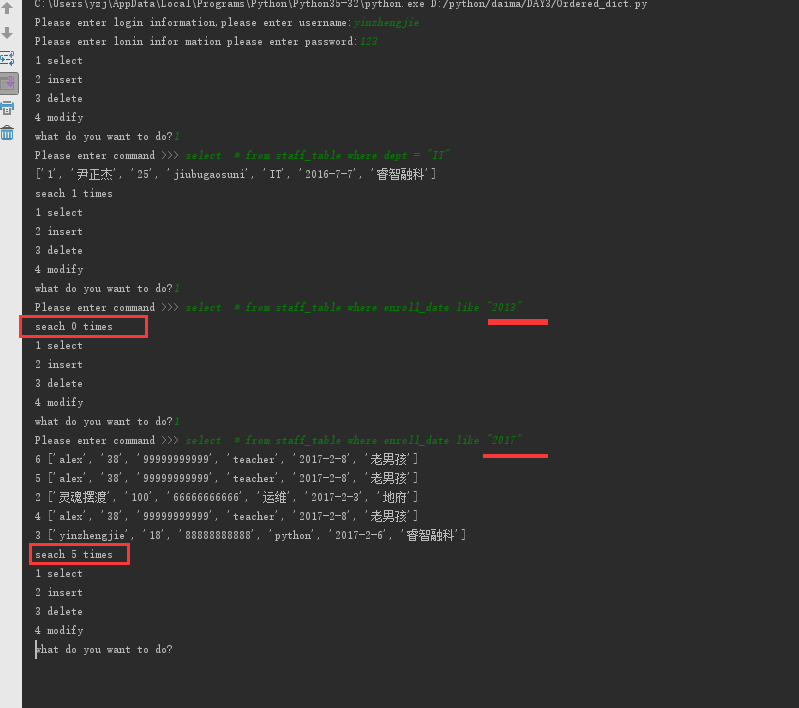
查:
select name,age from staff_table where age > 22
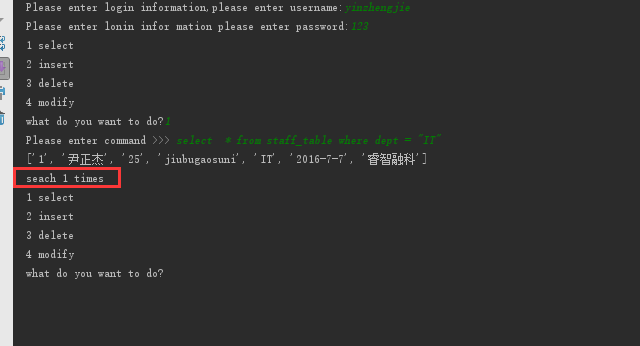
select * from staff_table where dept = "IT"
select * from staff_table where enroll_date like "2013"
select * from staff_table where enroll_date like "2017"
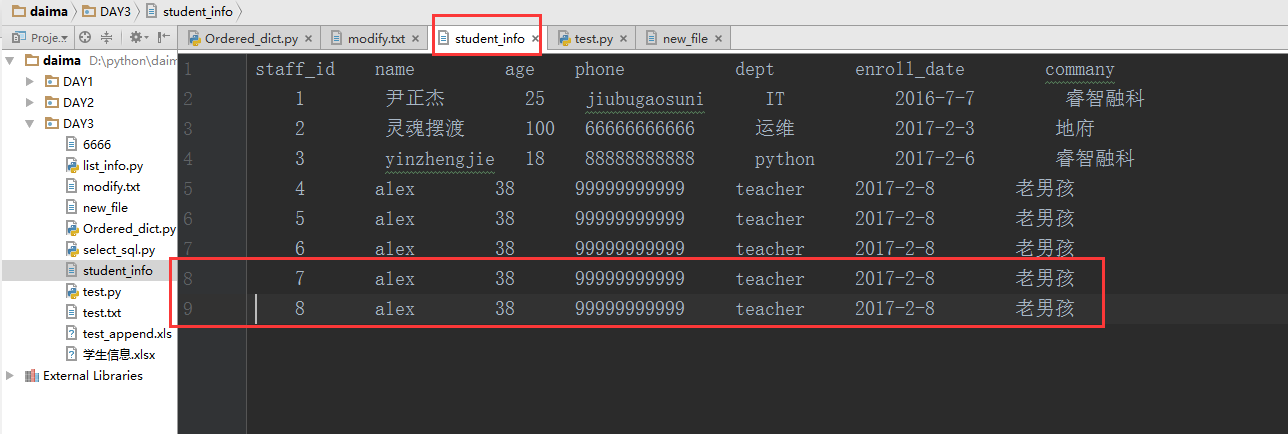
插入:
insert into staff_table values('alex','38','99999999999','teacher','2017-2-8','老男孩')
insert into staff_table values('alex','38','99999999999','teacher','2017-2-8','老男孩')
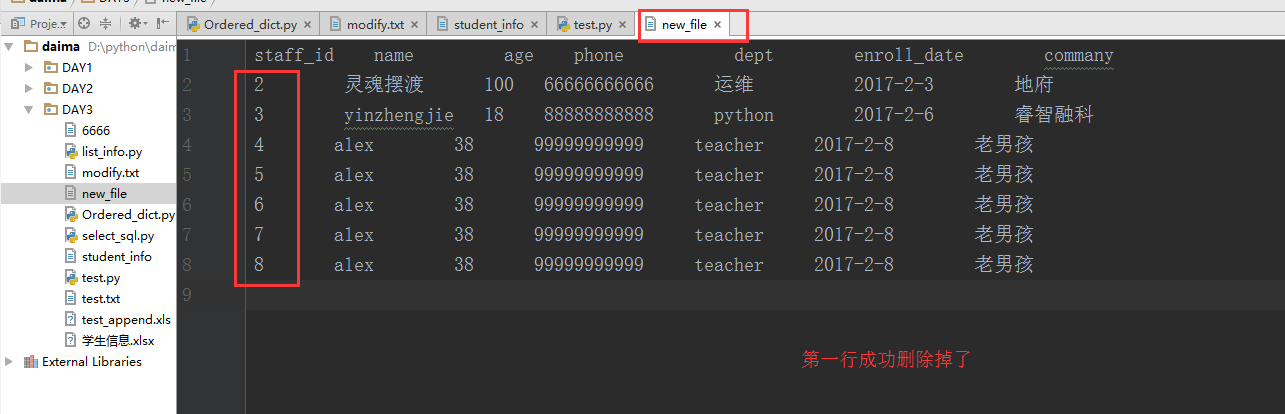
删除:
delete from staff_table where id = '1'
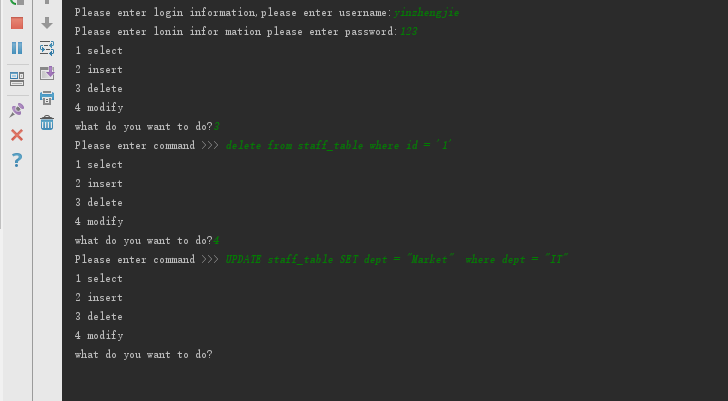
修改:
UPDATE staff_table SET dept = "Market" where dept = "IT"
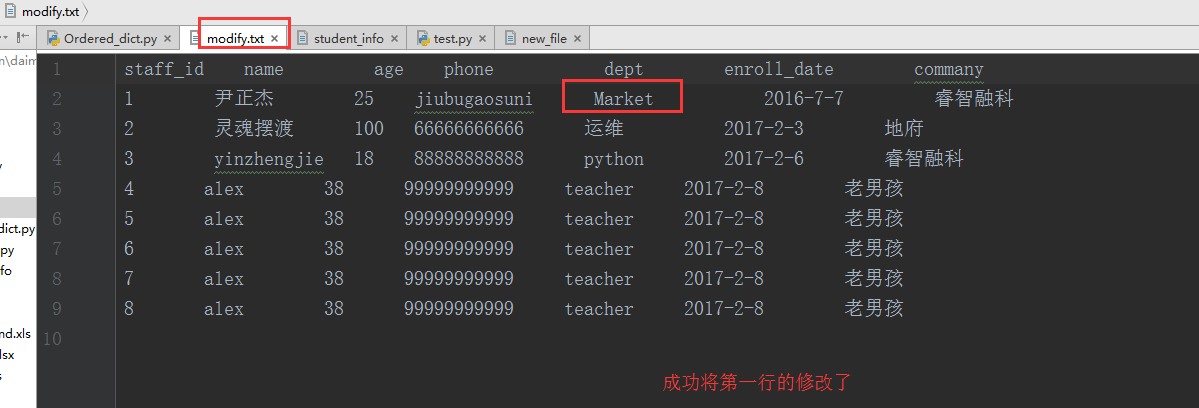


















 1148
1148

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









