



 本文介绍了 Elasticsearch 的核心概念及其与传统数据库的对比,包括分布式存储引擎、搜索引擎、索引、文档、类型等,并解释了其在近实时搜索、集群管理、横向扩展等方面的特点。
本文介绍了 Elasticsearch 的核心概念及其与传统数据库的对比,包括分布式存储引擎、搜索引擎、索引、文档、类型等,并解释了其在近实时搜索、集群管理、横向扩展等方面的特点。

1.elasticsearch,基于lucene,隐藏复杂性,提供简单易用的restful api接口、java api接口(还有其他语言的api接口)
1.1 分布式的文档存储引擎
1.2 分布式的搜索引擎和分析引擎
1.3 分布式,支持PB级数据
2.elasticsearch的核心概念
2.1 Near Realtime(NRT):近实时,两个意思,从写入数据到数据可以被搜索到有一个小延迟(大概1秒);基于es执行搜索和分析可以达到秒级
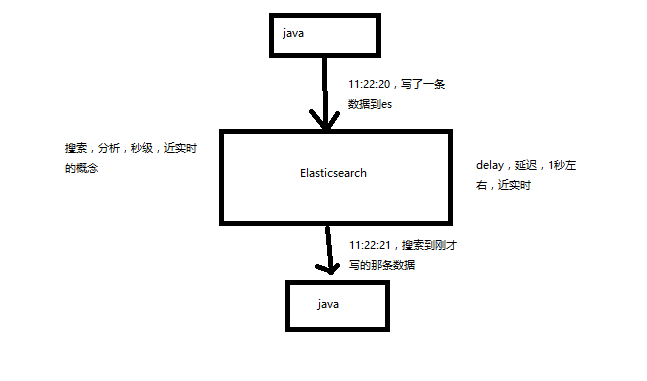
2.2 Cluster:集群,包含多个节点,每个节点属于哪个集群是通过一个配置(集群名称,默认是elasticsearch)来决定的,对于中小型应用来说,刚开始一个集群就一个节点很正常
2.3 Node:节点,集群中的一个节点,节点也有一个名称(默认是随机分配的),节点名称很重要(在执行运维管理操作的时候),默认节点会去加入一个名称为“elasticsearch”的集群,如果直接启动一堆节点,那么它们会自动组成一个elasticsearch集群,当然一个节点也可以组成一个elasticsearch集群
2.4 Document&field:(document相当于我们mysql数据库中的一行数据,field相当于一个字段)文档,es中的最小数据单元,一个document可以是一条客户数据,一条商品分类数据,一条订单数据,通常用JSON数据结构表示,每个index下的type(type相当于mysql数据库中一张表)中,都可以去存储多个document。一个document里面有多个field,每个field就是一个数据字段。
2.5 Index:索引(相当于mysql的一个数据库,database),包含一堆有相似结构的文档数据,比如可以有一个客户索引,商品分类索引,订单索引,索引有一个名称。一个index包含很多document,一个index就代表了一类类似的或者相同的document。比如说建立一个product index,商品索引,里面可能就存放了所有的商品数据,所有的商品document。
2.6 Type:类型(相当于mysql数据库中的一张表),每个索引里都可以有一个或多个type,type是index中的一个逻辑数据分类,一个type下的document,都有相同的field,比如博客系统,有一个索引,可以定义用户数据type,博客数据type,评论数据type。
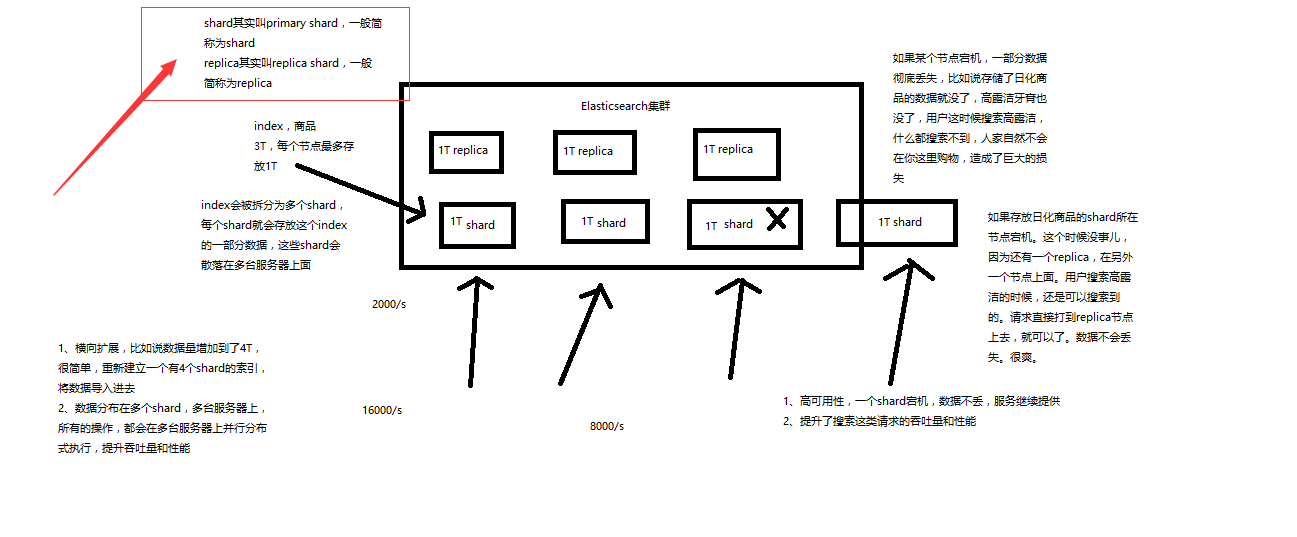
2.7 shard:(一个shard可以理解为一个数据库,多个shard就是配置多个数据库)单台机器无法存储大量数据,es可以将一个索引中的数据切分为多个shard,分布在多台服务器上存储。有了shard就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。每个shard都是一个lucene index。
2.8 replica:(说白了就是把shard的数据复制一遍到这个数据库,防止shard坏掉数据缺失,由于功能不一样,所以叫replica)任何一个服务器随时可能故障或宕机,此时shard可能就会丢失,因此可以为每个shard创建多个replica副本。replica可以在shard故障时提供备用服务,保证数据不丢失,多个replica还可以提升搜索操作的吞吐量和性能。primary shard(建立索引时一次设置,不能修改,默认5个),replica shard(随时修改数量,默认1个),默认每个索引10个shard,5个primary shard,5个replica shard,最小的高可用配置,是2台服务器。
3.elasticsearch核心概念 vs. 数据库核心概念
Elasticsearch 数据库
Document 行
Type 表
Index 库

















 95
95

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









