



 本文深入探讨 Spark Streaming 的核心概念、应用场景及其实现细节。文章通过四个实战案例,包括基本使用、单词计数、窗口操作及从 Kafka 中读取数据,详细展示了 Spark Streaming 在实时数据处理中的强大功能。
本文深入探讨 Spark Streaming 的核心概念、应用场景及其实现细节。文章通过四个实战案例,包括基本使用、单词计数、窗口操作及从 Kafka 中读取数据,详细展示了 Spark Streaming 在实时数据处理中的强大功能。

一、spark的野心:
1、取代mapreduce--->Batch Processing
2、spark Sql --->hive
3、stream processing --->strom
吞吐量比storm大,处理速度是storm的2到5倍,但是延迟是秒级别的
sparkstream 是微批处理
sparkstream 是以时间进行分割的,的核心还是批处理,有任务的启停,最小批次是不能小于500毫秒(太小了反应不过来),一般是500---2000毫秒
二、Spark streaming基本概念
离散流(discretized stream)或DStream:这是Spark Streaming对内部持续的实时数据流的抽象描述,即我们处理的一个实时数据流,在Spark Streaming中对应于一个DStream实例。
批数据(batch data):这是化整为零的第一步,将实时流数据以时间片为单位进行分批,将流处理转化为时间片数据的批处理。随着持续时间的推移,这些处理结果就形成了对应的结果数据流了。
时间片或批处理时间间隔(batch interval):这是人为地对流数据进行定量的标准,以时间片作为我们拆分流数据的依据。一个时间片的数据对应一个RDD实例。
窗口长度(window length):一个窗口覆盖的流数据的时间长度。必须是批处理时间间隔的倍数,
滑动时间间隔:前一个窗口到后一个窗口所经过的时间长度。必须是批处理时间间隔的倍数
Input DStream:一个input DStream是一个特殊的DStream,将Spark Streaming连接到一个外部数据源来读取数据
Spark Streaming是将流式计算分解成一系列短小的批处理作业。这里的批处理引擎是Spark Core,也就是把Spark Streaming的输入数据按照batch size(如1秒)分成一段一段的数据(Discretized Stream),每一段数据都转换成Spark中的RDD(Resilient Distributed Dataset),然后将Spark Streaming中对DStream的Transformation操作变为针对Spark中对RDD的Transformation操作,将RDD经过操作变成中间结果保存在内存中。整个流式计算根据业务的需求可以对中间的结果进行叠加或者存储到外部设备。
三、性能
实时性:对于实时性的讨论,会牵涉到流式处理框架的应用场景。Spark Streaming将流式计算分解成多个Spark Job,对于每一段数据的处理都会经过Spark DAG图分解以及Spark的任务集的调度过程。对于目前版本的Spark Streaming而言,其最小的Batch Size的选取在0.5~2秒钟之间(Storm目前最小的延迟是100ms左右),所以Spark Streaming能够满足除对实时性要求非常高(如高频实时交易)之外的所有流式准实时计算场景。
扩展性与吞吐量:Spark目前在EC2上已能够线性扩展到100个节点(每个节点4Core),可以以数秒的延迟处理6GB/s的数据量(60M(60M条记录) records/s),其吞吐量也比流行的Storm高2~5倍,图4是Berkeley利用WordCount和Grep两个用例所做的测试,在Grep这个测试中,Spark Streaming中的每个节点的吞吐量是670k records/s,而Storm是115k records/s
四、实战:
=======================================================================================================================
1、第一个sparkstreaming 小程序(不能实现累加)
导入必要的jar包
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Created by root on 2016/7/24.
*/
object sparkstream {
def main(args: Array[String]) {
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
var conf = new SparkConf().setAppName("mysparkStream").setMaster("local[2]")
var ssc = new StreamingContext(conf ,Seconds(5))
var input = ssc.socketTextStream("node11",9999,StorageLevel.MEMORY_AND_DISK)
input.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).print()
ssc.start()
ssc.awaitTermination()
}
}
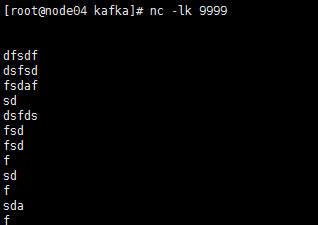
在node12 上安装nc服务
yum -y install nc启动服务 端口9999
nc -lk 9999然后输入数据上面的程序就可以计算了
截屏:
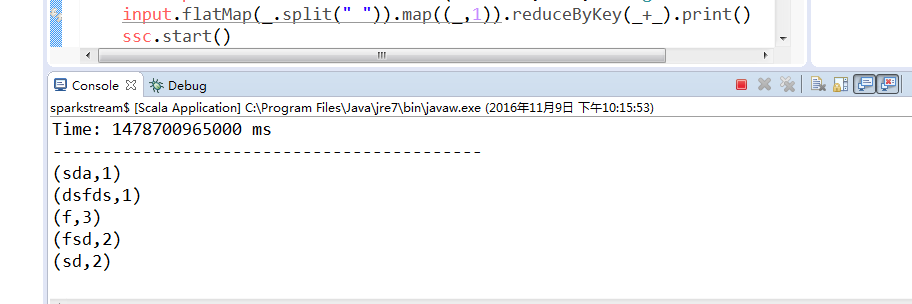
============================================================================================================================
Spark Streaming 是Spark核心API的一个扩展,可以实现高吞吐量的、具备容错机制的实时流数据的处理。支持从多种数据源获取数据,包括Kafka、Flume、Twitter、ZeroMQ、Kinesis 以及TCP sockets
spark中的算子:
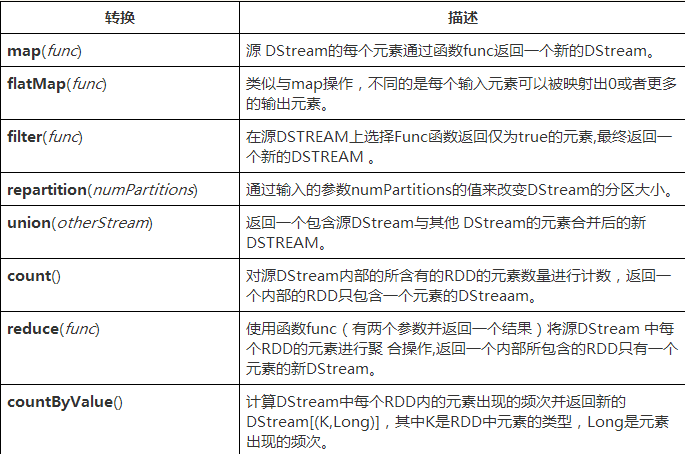

transform函数:
sparkstreaming 中的数据类型都是DStream类型的,当DStream类型的数据的操作算子不能满足需求时 transform函数可以将DStream转化为rdd类型进行操作,操作完成之后再转化为DStream类型返回;
updateStateByKey:记录之前数据的状态,和现在的数据进行计算
=======================================================================================================================
例子2、wordcount实例 (updateStateByKey函数的使用)
package com.kafka.test
import org.apache.log4j.{Level, Logger}
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Seconds
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.dstream.DStream
object WordCount {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
var conf = new SparkConf().setAppName("mysparkStream").setMaster("local[2]")
var ssc = new StreamingContext(conf ,Seconds(5))
ssc.checkpoint("E:/wordcount");
val updateFunc = (values :Seq[Int],state:Option[Int])=> {
val currentCount = values.sum;
val previousCount = state.getOrElse(0);
Some(currentCount+previousCount);
}
var lines: ReceiverInputDStream[String] = ssc.socketTextStream("node04",9999,StorageLevel.MEMORY_AND_DISK)
var words: DStream[(String, Int)] =lines.flatMap { x => x.split(" ") }.map { x => (x,1) };
val stateDstream = words.updateStateByKey[Int](updateFunc);
stateDstream.print();
ssc.start();
ssc.awaitTermination()
}
}同样要启动 nc -lk 9999 端口 ,然后向其中添加数据
=======================================================================================================================
窗口理解:

Spark Streaming还提供了窗口的计算,它允许你通过滑动窗口对数据进行转换,窗口转换操作如下:
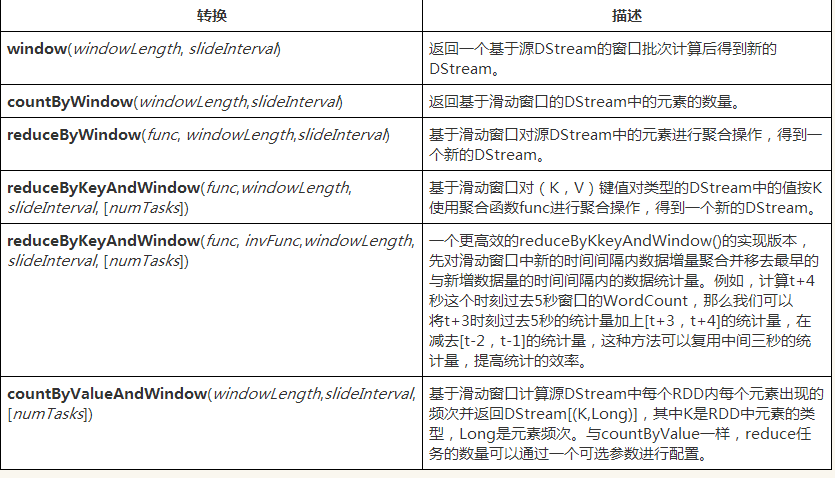
==================================================================================================================
例子3、窗口
package com.kafka.test
import org.apache.log4j.{Level, Logger}
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Seconds
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.storage.StorageLevel
import org.netlib.util.Second
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.Durations
import org.apache.spark.streaming.Durations
object WindowBaseTopWord {
def main(args: Array[String]) {
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
val conf = new SparkConf().setAppName("WindowBasedTopWord").setMaster("local[2]")
val ssc = new StreamingContext(conf,Durations.seconds(5)) //这里的5秒是指切分RDD的间隔
ssc.checkpoint("E:/wordcount_checkpoint") //设置docheckpoint目录,没有会自动创建
val words: ReceiverInputDStream[String] = ssc.socketTextStream("node04",9999)
val pairs = words.flatMap(_.split(" ")).map(x => (x,1))
pairs.foreachRDD(rdd => {
println("--------------split RDD begin--------------")
rdd.foreach(println)
println("--------------split RDD end--------------")
})
/*
reduceByKeyAndWindow(reduceFunc,invReduceFunc,windowDuration,slideDuration)
reduceFunc:用于计算window框住的RDDS
invReduceFunc:用于优化的函数,减少window滑动中去计算重复的数据,通过“_-_”即可优化
windowDuration:表示window框住的时间长度,如本例5秒切分一次RDD,框20秒,就会保留最近4次切分的RDD
slideDuration:表示window滑动的时间长度,即每隔多久执行本计算
本例5秒切分一次RDD,每次滑动10秒,window框住20秒的RDDS,即:每10秒计算最近20秒切分的RDDS,中间有10秒重复,
通过invReduceFunc参数进行去重优化
*/
val pairsWindow = pairs.reduceByKeyAndWindow(_+_,_-_,Durations.seconds(20),Durations.seconds(10))
val sortDstream = pairsWindow.transform(rdd => {
val sortRdd = rdd.map(t => (t._2,t._1)).sortByKey(false).map(t => (t._2,t._1)) //降序排序
val more = sortRdd.take(3) //取前3个输出
println("--------------print top 3 begin--------------")
more.foreach(println)
println("--------------print top 3 end--------------")
sortRdd
})
sortDstream.print()
ssc.start()
ssc.awaitTermination()
}
}nc -lk 9999
=======================================================================================================
例子4、SparkStreaming 从kafka中读取数据计算单词数(不是总数)
package com.kafka.test;
import java.util.HashMap;
import java.util.Map;
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Duration;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaPairReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka.KafkaUtils;
import scala.Tuple2;
import scala.actors.threadpool.Arrays;
public class KafkaStreamingWordCount {
public static void main(String[] args) {
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR);
//接收数据的地址和端口
String zkQuorum = "192.168.47.11:2181,192.168.47.12:2181,192.168.47.13:2181";
//话题所在的组
String group = "1";
//话题名称以“,”分隔
String topics = "test3,test2";
//每个话题的分片数
int numThreads = 2;
SparkConf sparkConf = new SparkConf().setAppName("KafkaWordCount").setMaster("local[2]");
JavaStreamingContext jssc = new JavaStreamingContext(sparkConf, new Duration(10000));
// jssc.checkpoint("checkpoint"); //设置检查点
//存放话题跟分片的映射关系
Map<String, Integer> topicmap = new HashMap<>();
String[] topicsArr = topics.split(",");
int n = topicsArr.length;
for(int i=0;i<n;i++){
topicmap.put(topicsArr[i], numThreads);
}
//从Kafka中获取数据转换成RDD
JavaPairReceiverInputDStream<String, String> lines = KafkaUtils.createStream(jssc, zkQuorum, group, topicmap);
//从话题中过滤所需数据
JavaDStream<String> words = lines.flatMap(new FlatMapFunction<Tuple2<String, String>, String>() {
@Override
public Iterable<String> call(Tuple2<String, String> arg0)
throws Exception {
return Arrays.asList(arg0._2.split(" "));
}
});
//对其中的单词进行统计
JavaPairDStream<String, Integer> wordCounts = words.mapToPair(
new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) {
return new Tuple2<String, Integer>(s, 1);
}
}).reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2) {
return i1 + i2;
}
});
//打印结果
wordCounts.print();
jssc.start();
jssc.awaitTermination();
}
}这里需要启动kafka集群,并向其topic中实时注入数据

















 459
459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









