



 PredNet是一种用于视频预测和无监督学习的深度预测编码网络。它通过局部预测与真实输入之间的误差来更新网络,展示了强大的无监督学习能力。该模型由一系列模块堆叠构成,每个模块包括输入卷积层、循环表示层、预测层和误差表示层。
PredNet是一种用于视频预测和无监督学习的深度预测编码网络。它通过局部预测与真实输入之间的误差来更新网络,展示了强大的无监督学习能力。该模型由一系列模块堆叠构成,每个模块包括输入卷积层、循环表示层、预测层和误差表示层。
PredNet --- Deep Predictive coding networks for video prediction and unsupervised learning ICLR 2017
2017.03.12
Code and video examples can be found at: https://coxlab.github.io/prednet/
摘要:基于监督训练的深度学习技术取得了非常大的成功,但是无监督问题仍然是一个未能解决的一大难题(从未标注的数据中学习到一个领域的结构)。本文探索了无监督学习中关于 video prediction 的问题。设计了一种 “PredNet”结构,实现了该项工程,并且得到了非常喜人的实验结果。实验结果表明:预测代表了一种非常强大的无监督学习框架,可以潜在的学习到物体或者场景结构。
网络设计:
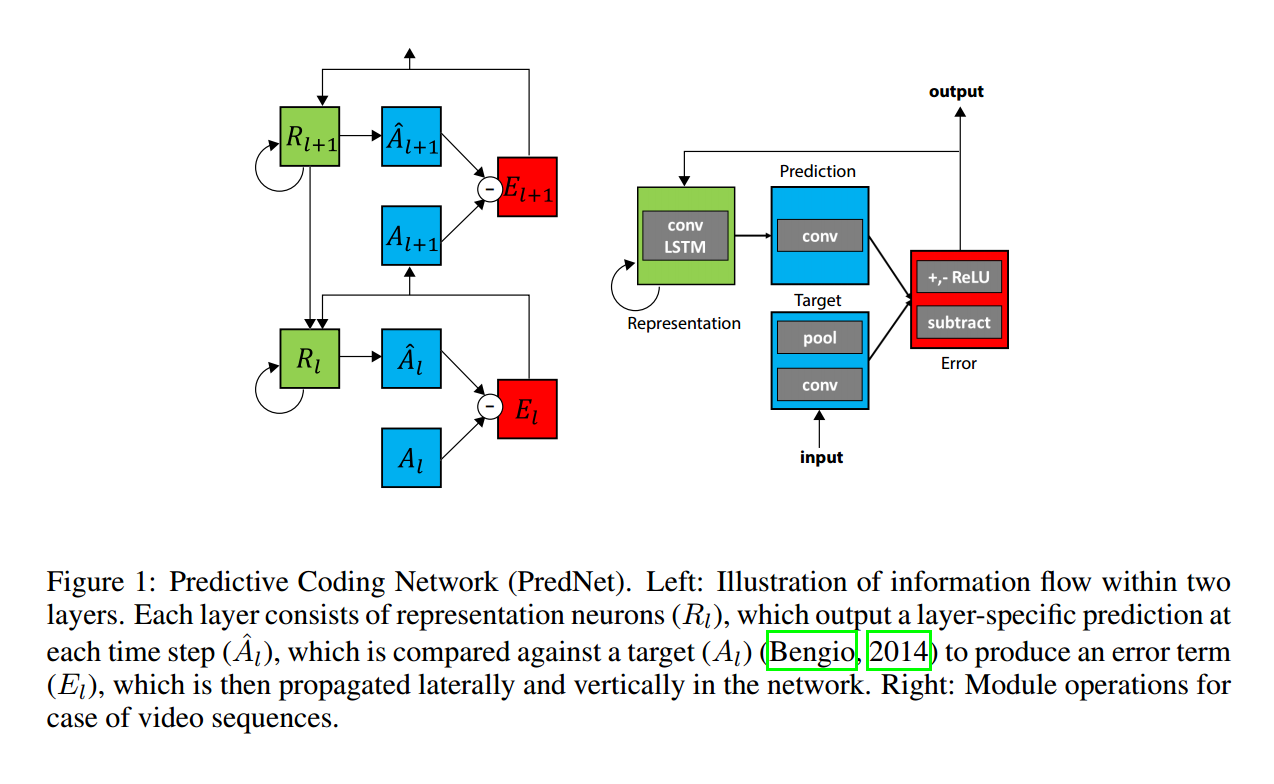
如上图所示的流程,是有一系列的模块堆叠在一起产生的。该网络首先进行局部预测,然后减去真实的输入,传到下一层。
简单的说,每个模块可以分为 4 个部分:
1. 一个输入卷积层 $A_l$
2. 循环表示层 $R_l$
3. 预测层 $\hat{A}_l $
4. 误差表示层 $E_l$
$R_l$ 是一个循环卷积网络产生一个预测 A^l,layer的输入是 Al。网络计算 Al 和 A^l 的不同,然后输出一个误差表示 El, 分为单独修正的 positive 和 negative error 传递。将该误差 El 传递给卷积层,作为下一层的输入 $A_{l+1}$。$R_l$ 模块有两个输入,分别来自于:直接拷贝过来的 El,以及 下一层 $R_{l+1}$ 的输入。
这个网络可以分为两个最重要的部分来看,左边 Rl 部分是循环产生式反卷积网络;右边 Al 和 El 是标准的深度卷积网络。
该模型训练的目标是:minimize the weighted sum of the firing rates of the error units. 此处的 error units 类似于 L1 error. 虽然此处没有尝试,但也可以尝试其他的 loss function。

总的算法框架如下:

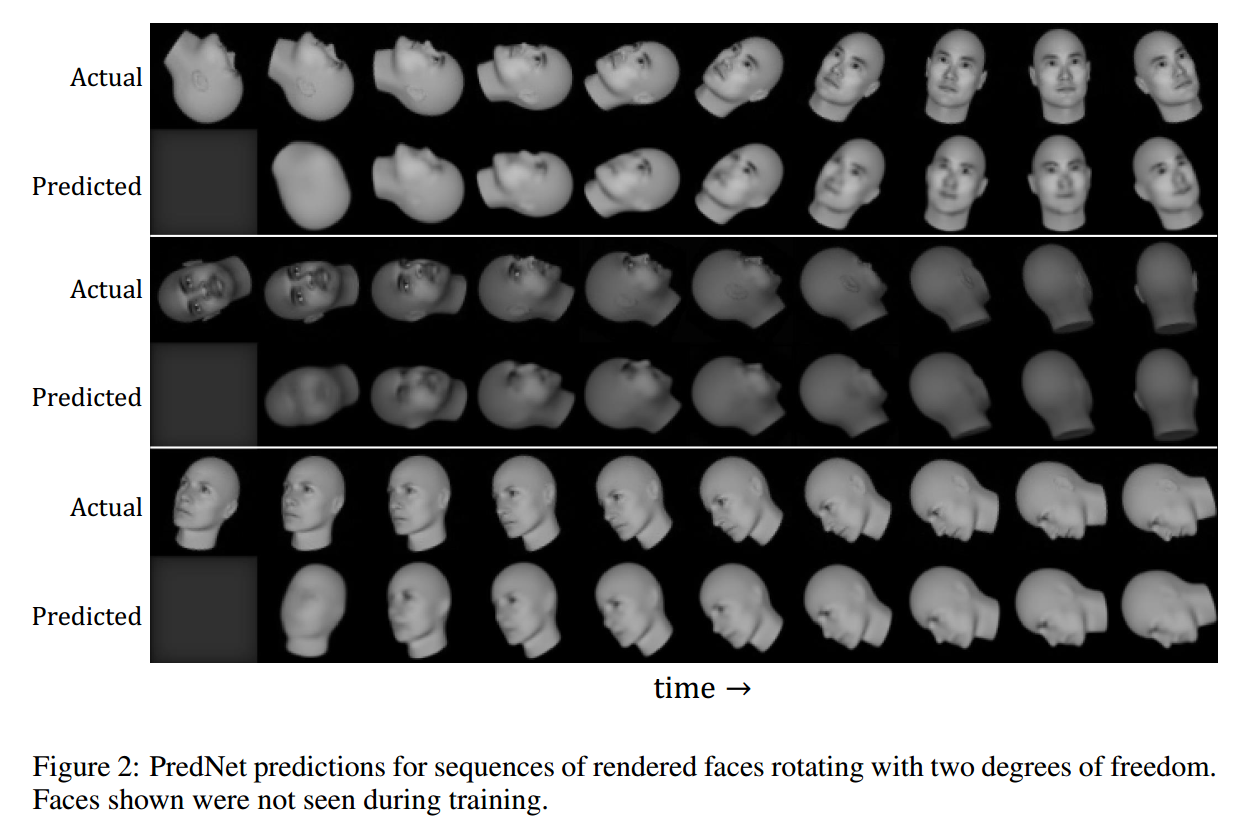
实验部分:



















 1821
1821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









