





https://www.letslearnai.com/2018/03/10/what-are-l1-and-l2-loss-functions.html
http://rishy.github.io/ml/2015/07/28/l1-vs-l2-loss/
L1-loss
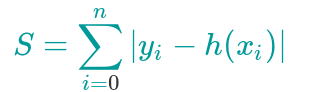
L2-loss
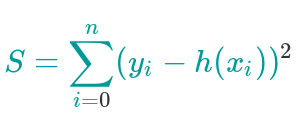
L1 loss感觉和L1范式差不多,L2 loss相较于L2范式没有开根号,或者说L2 loss就是两个值相减开平方

 本文介绍了机器学习中常用的两种损失函数:L1-loss 和 L2-loss 的概念及区别。L1-loss 类似于 L1 范式,而 L2-loss 与 L2 范式有关但不完全相同,它涉及到了两值相减后的平方运算。
本文介绍了机器学习中常用的两种损失函数:L1-loss 和 L2-loss 的概念及区别。L1-loss 类似于 L1 范式,而 L2-loss 与 L2 范式有关但不完全相同,它涉及到了两值相减后的平方运算。
https://www.letslearnai.com/2018/03/10/what-are-l1-and-l2-loss-functions.html
http://rishy.github.io/ml/2015/07/28/l1-vs-l2-loss/
L1-loss
L2-loss
L1 loss感觉和L1范式差不多,L2 loss相较于L2范式没有开根号,或者说L2 loss就是两个值相减开平方
 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言



























