



实验任务一:
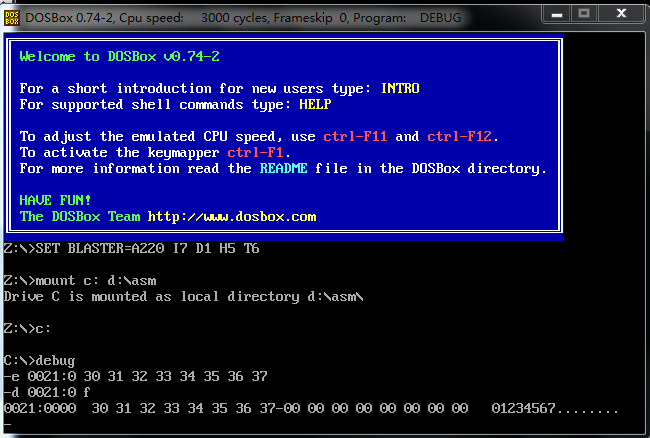
截图记录:使用 e 命令修改 0021:0~0021:f 数据,及修改后查看是否正确写入的操作
图片底行是最后改对的形式
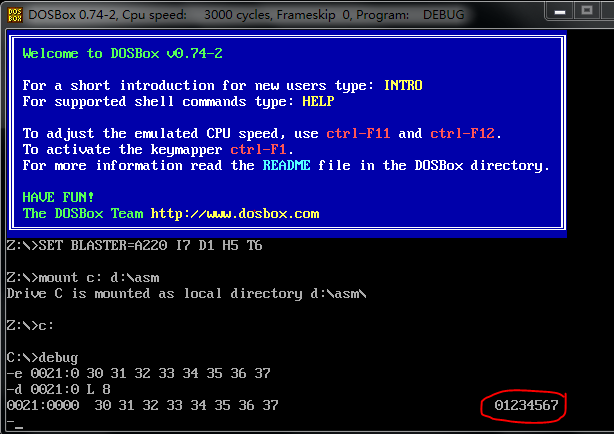
这里我只要求显示八个字节
------------------------------------------------分界线--------------------------------------------
以下是完全是一次错误的实验经历------也可直接跳过
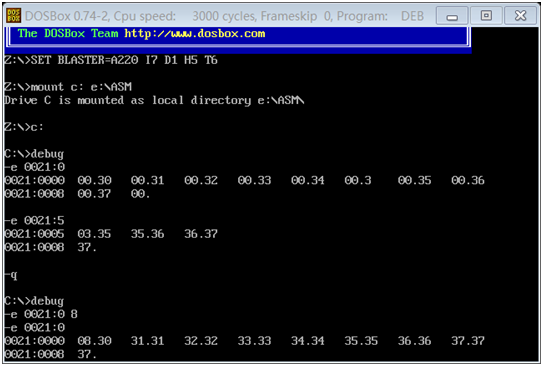
② 截图记录:使用 a 命令输入的 p74 指令③ 截图记录:每一行指令单步调试(如单步调试步骤多,可分屏截图,但不要有遗漏)
④ P74 中指令执行后各个寄存器填空结果,以在文档中手工标注或手机拍照截图方式 复制在文档中。 对于③单步调试的观察,与理论上分析的结果进行比较,检验是否一致
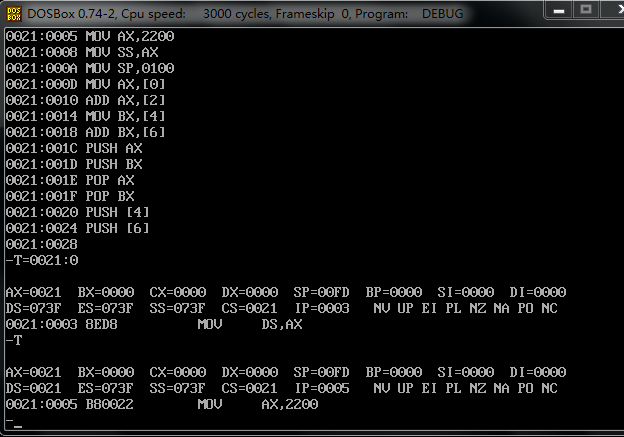
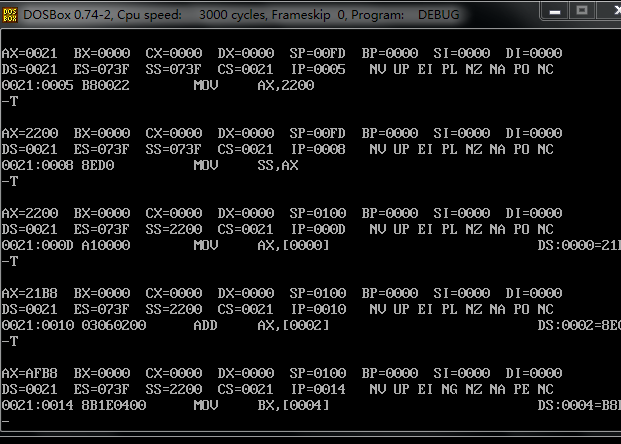
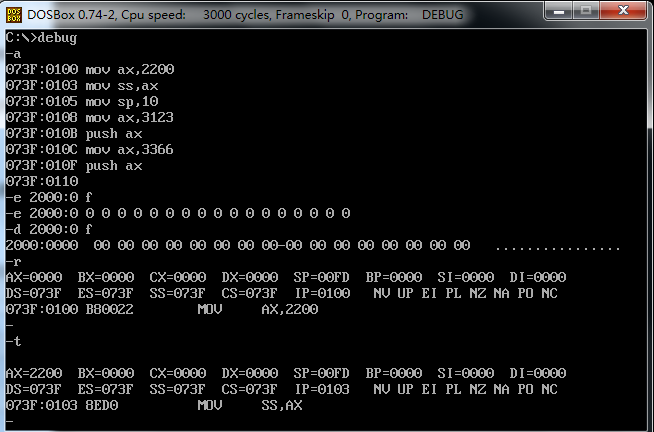
看了其他同学的博客之后才注意到,mov sp 0100 跳过了。这里其实是 和mov ss,ax 一起执行了
这是为什么呢?其他同学给的解释是:为了确保对SS寄存器和指针不进行修改做出的保护机制。
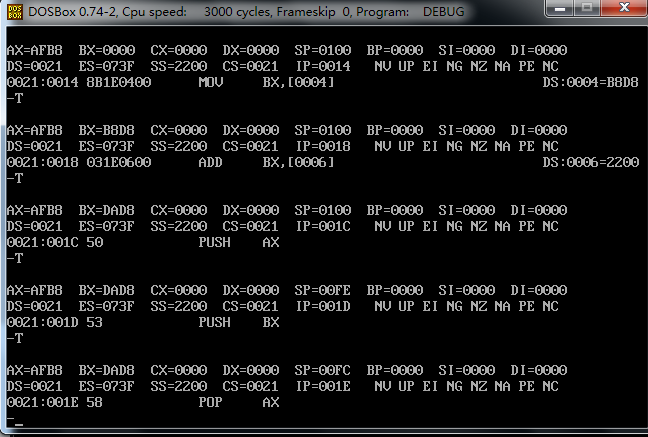
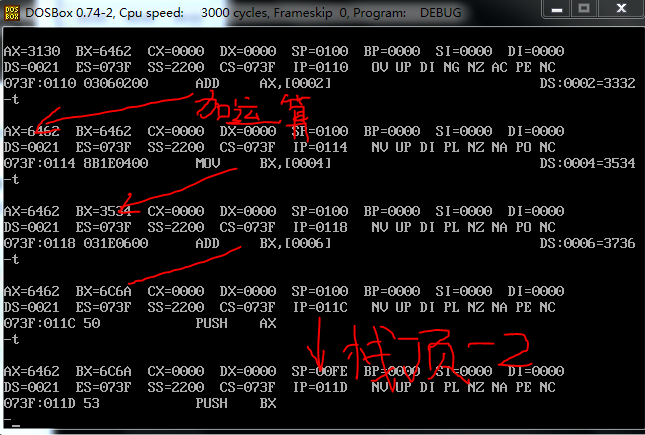
可以看到利用栈进行数值交换,只不过我无法理解 push 指令后面数据寄存器中存储的值是哪里来的?
貌似是AX 的地址。因为一开始栈底是通过AX给出的。
可是0021:4 的 内存单元上写的数据应该是3534吧
如上图所示的横线标记的位子,就是推入占中对应的内存地址单元和其中对应的值 书P105
————————————————————————正确的实验操实例分界线————————————————————
我想是我错了。所以我重新做了一遍。
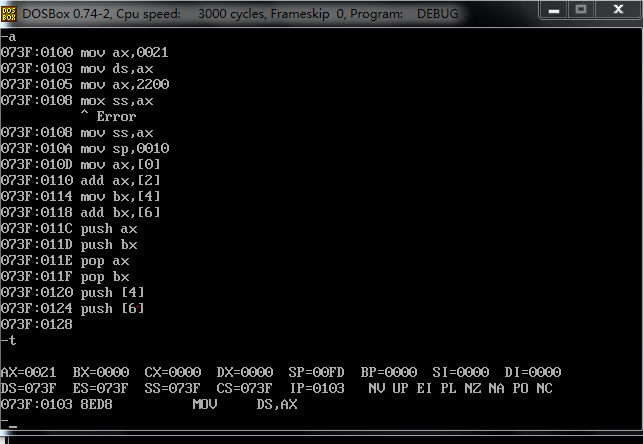
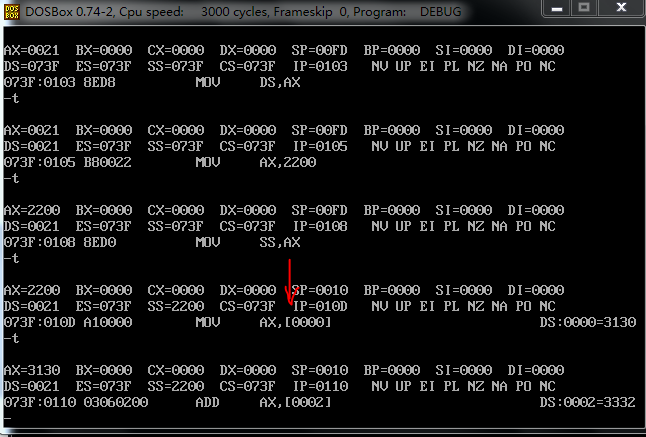
上图可以看到 将ds为0021的 偏移数据的段地址为 [0]的内存打单元给寄存器ax 采用小端法的化读入的是3130
将0021:4 地址上存储的数据 给寄存器bx
分析了一下,一开始我没有作对的原因。我一开始指定了 从0021:0 开始写入,我明明把00210:f 设置成了数据域 现在又对它进行指令操作,自然是不能得到预想结果的。
座椅上这个实验的时候,最困扰我的是匹配地址。我的源程序该放在哪里,以便我调用masm编译源程序文件的时候可以执行,也能进行编译。
如果我想编译文件和编译软件分开放呢?这里面要跳转多个文件,我不是很熟悉,但是我想只要是很多次最后是可以试出来的。只不过就是要花费更多的时间。(
实验任务二:
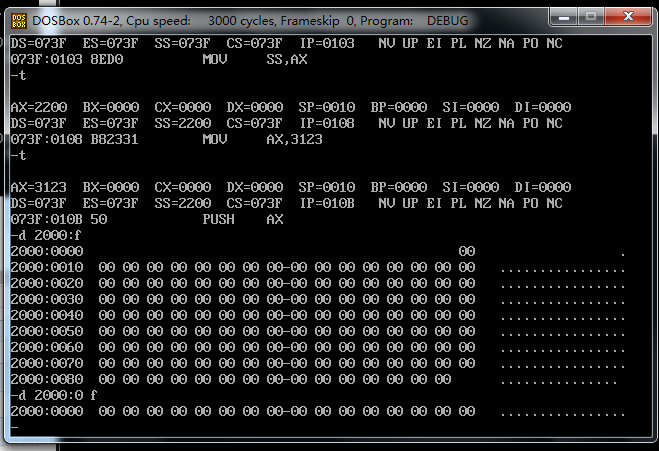
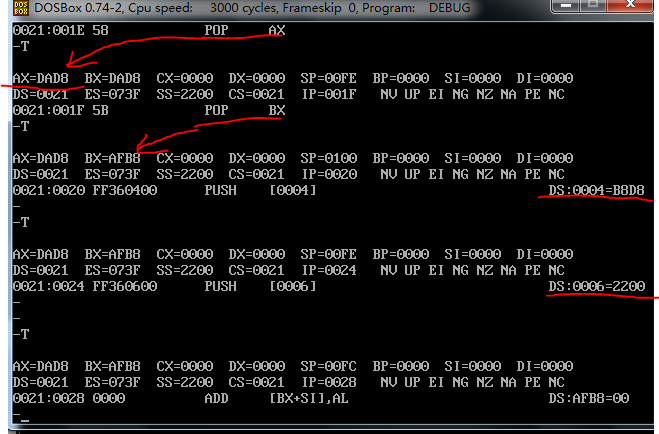
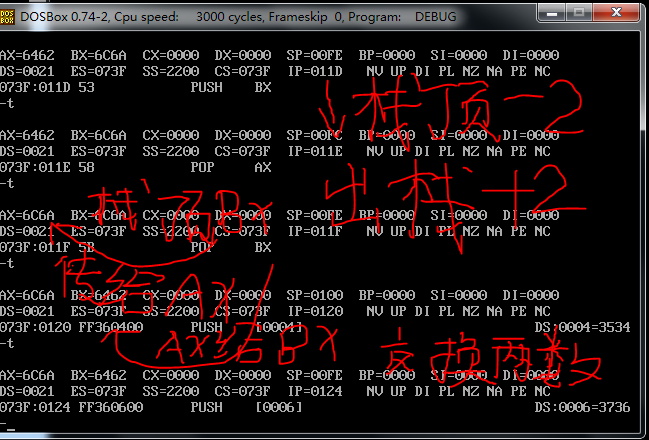
push 操作执行之后还是没有什么变化 ?仔细看是自己要求查看的地址书写问题
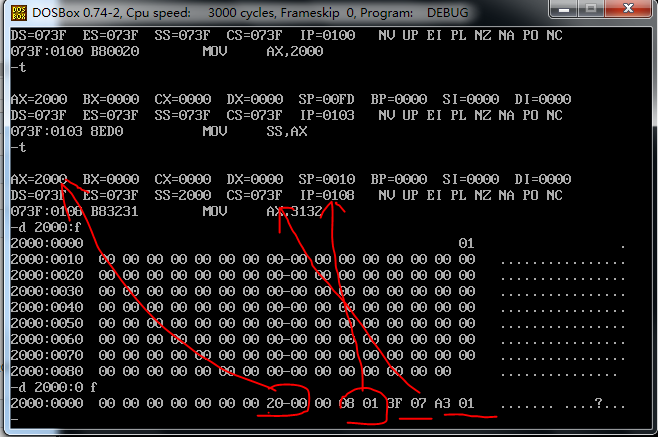
栈段中保存了,ax寄存器的值,CS:IP的值
不过最后一个字数据我实在不能在debug中找到对应的元素。

















 3799
3799

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









