






 本文介绍如何搭建CentOS7集群环境,并详细记录了配置步骤,包括虚拟机准备、IP地址与主机名修改、防火墙管理、YUM源配置、免密登录设置等。此外还介绍了JDK的安装过程。
本文介绍如何搭建CentOS7集群环境,并详细记录了配置步骤,包括虚拟机准备、IP地址与主机名修改、防火墙管理、YUM源配置、免密登录设置等。此外还介绍了JDK的安装过程。
一、CentOS7集群搭建
1.1 准备3台centos7的虚拟机
IP及主机名规划如下:
192.168.123.110 spark1
192.168.123.111 spark2
192.168.123.112 spark3
1.2 修改IP地址
[root@bigdata ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33
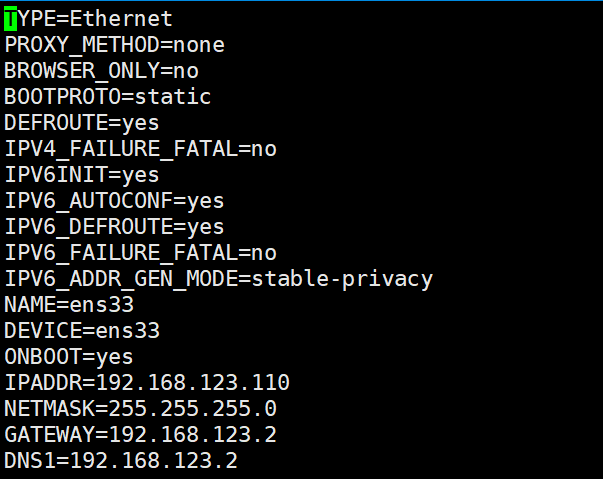
1.3 修改主机映射
[root@bigdata ~]# vi /etc/hosts

1.4 修改主机名
三台机器分别把主机名修改为spark1、spark2、spark3
[root@bigdata ~]# vi /etc/hostname

1.5 关闭防火墙
//临时关闭 systemctl stop firewalld //禁止开机启动 systemctl disable firewalld

1.6 修改repo
[root@bigdata ~]# cd /etc/yum.repos.d/ [root@bigdata yum.repos.d]# wget http://mirrors.163.com/.help/CentOS7-Base-163.repo

如果还有其他源,可以暂且把他们重命名成其他扩展名,比如 CentOS-Base.repo.bak
[root@bigdata yum.repos.d]# mv CentOS-Base.repo CentOS-Base.repo.bak
[root@bigdata yum.repos.d]# mv CentOS7-Base-163.repo CentOS7-Base.repo [root@bigdata yum.repos.d]# yum clean all [root@bigdata yum.repos.d]# yum makecache
安装 epel 源
[root@bigdata yum.repos.d]# yum install epel-release [root@bigdata yum.repos.d]# yum makecache
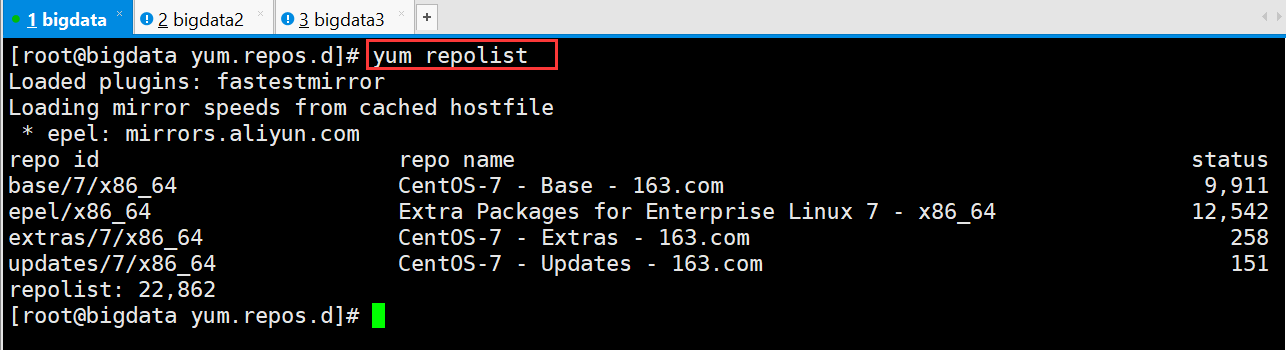
检查是否安装成功
[root@bigdata yum.repos.d]# yum repolist
1.7 配置免密登录
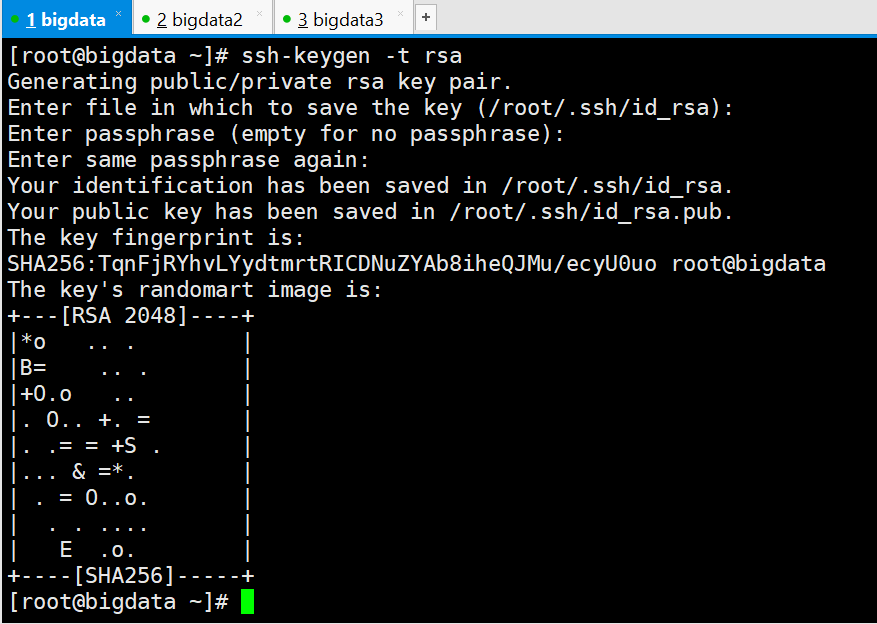
[root@bigdata ~]# ssh-keygen -t rsa
三次回车
将spark1上的公钥复制到文件authorized_keys中
[root@spark1 ~]# cd .ssh [root@spark1 .ssh]# cat id_rsa.pub > authorized_keys
将spark2、和spark3机器上的公钥发送到spark1上
[root@spark2 .ssh]# scp -r id_rsa.pub root@192.168.123.110:~/spark2.pub [root@spark3 .ssh]# scp -r id_rsa.pub root@192.168.123.110:~/spark3.pub
在spark1上将spark2、和spark3的公钥追加到authorized_keys中
[root@bigdata ~]# cat spark2.pub > .ssh/authorized_keys [root@bigdata ~]# cat spark3.pub > .ssh/authorized_keys
在spark1上验证ssh免密登录是否设置成功
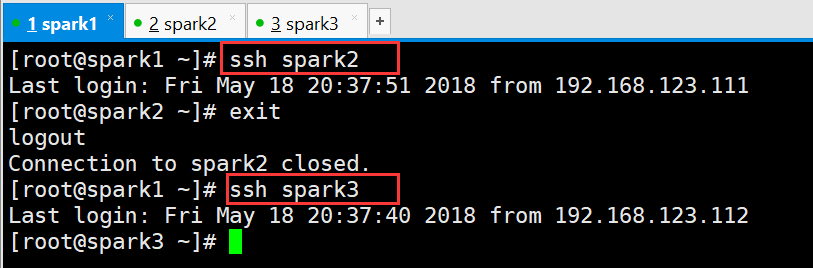
二、软件的安装
2.1 JDK的安装
上传并解压
[root@spark1 ~]# tar -zxvf jdk-8u73-linux-x64.tar.gz -C apps/
修改环境变量
[root@spark1 apps]# vi /etc/profile
#JAVA export JAVA_HOME=/root/apps/jdk1.8.0_73 export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH:$HOME/bin
保存并使其生效
[root@spark1 apps]# source /etc/profile
检查



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









