






 本文介绍了TensorFlow的发展历程及核心功能,展示了如何通过Pip安装TensorFlow,并使用梯度下降法构建线性学习模型。此外,还详细阐述了分布式TensorFlow的应用架构,包括其在数百台机器上的并行训练能力。
本文介绍了TensorFlow的发展历程及核心功能,展示了如何通过Pip安装TensorFlow,并使用梯度下降法构建线性学习模型。此外,还详细阐述了分布式TensorFlow的应用架构,包括其在数百台机器上的并行训练能力。
TensorFlow发展及使用简介
\\2015年11月9日谷歌开源了人工智能系统TensorFlow,同时成为2015年最受关注的开源项目之一。TensorFlow的开源大大降低了深度学习在各个行业中的应用难度。TensorFlow的近期里程碑事件主要有:
\\2016年11月09日:TensorFlow开源一周年。
\\2016年09月27日:TensorFlow支持机器翻译模型。
\\2016年08月30日:TensorFlow支持使用TF-Slim接口定义复杂模型。
\\2016年08月24日:TensorFlow支持自动学习生成文章摘要模型。
\\2016年06月29日:TensorFlow支持Wide \u0026amp; Deep Learning。
\\2016年06月27日:TensorFlow v0.9发布,改进了移动设备的支持。
\\2016年05月12日:发布SyntaxNet,最精确的自然语言处理模型。
\\2016年04月29日:DeepMind模型迁移到TensorFlow。
\\2016年04月14日:发布了分布式TensorFlow。
\\TensorFlow是一种基于图计算的开源软件库,图中节点表示数学运算,图中的边表示多维数组(Tensor)。TensorFlow是跨平台的深度学习框架,支持CPU和GPU的运算,支持台式机、服务器、移动平台的计算,并从r0.12版本开始支持Windows平台。Tensorflow提供了各种安装方式,包括Pip安装,Virtualenv安装,Anaconda安装,docker安装,源代码安装。 本文主要介绍Pip的安装方式,Pip是一个Python的包安装及管理工具。Linux系统下,使用Pip的安装流程如下:
\\yum install python-pip python-dev
\\export TF_BINARY_URL=https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-0.12.0rc0-cp27-none-linux_x86_64.whl
\\pip install --upgrade $TF_BINARY_URL
\\安装完毕后,TensorFlow会安装到/usr/lib/python2.7/site-packages/tensorflow目录下。使用TensorFlow之前,我们需要先熟悉下常用API。
\\tf.random_uniform([1], -1.0, 1.0):构建一个tensor, 该tensor的shape为[1],该值符合[-1, 1)的均匀分布。其中[1]表示一维数组,里面包含1个元素。
\\tf.Variable(initial_value=None):构建一个新变量,该变量会加入到TensorFlow框架中的图集合中。
\\tf.zeros([1]):构建一个tensor, 该tensor的shape为[1], 里面所有元素为0。
\\tf.square(x, name=None):计算tensor的平方值。
\\tf.reduce_mean(input_tensor):计算input_tensor中所有元素的均值。
\\tf.train.GradientDescentOptimizer(0.5):构建一个梯度下降优化器,0.5为学习速率。学习率决定我们迈向(局部)最小值时每一步的步长,设置的太小,那么下降速度会很慢,设的太大可能出现直接越过最小值的现象。所以一般调到目标函数的值在减小而且速度适中的情况。
\\optimizer.minimize(loss):构建一个优化算子操作。使用梯度下降法计算损失方程的最小值。loss为需要被优化的损失方程。
\\tf.initialize_all_variables():初始化所有TensorFlow的变量。
\\tf.Session():创建一个TensorFlow的session,在该session种会运行TensorFlow的图计算模型。
\\sess.run():在session中执行图模型的运算操作。如果参数为tensor时,可以用来求tensor的值。
\\下面为使用TensorFlow中的梯度下降法构建线性学习模型的使用示例:
\\\#导入TensorFlow python API库\\import tensorflow as tf\\import numpy as np\\\\#随机生成100点(x,y)\\x_data = np.random.rand(100).astype(np.float32)\\y_data = x_data * 0.1 + 0.3\\\\#构建线性模型的tensor变量W, b\\W = tf.Variable(tf.random_uniform([1], -1.0, 1.0))\\b = tf.Variable(tf.zeros([1]))\\y = W * x_data + b\\\\#构建损失方程,优化器及训练模型操作train\\loss = tf.reduce_mean(tf.square(y - y_data))\\optimizer = tf.train.GradientDescentOptimizer(0.5)\\train = optimizer.minimize(loss)\\\\#构建变量初始化操作init\\init = tf.initialize_all_variables()\\\\#构建TensorFlow session\\sess = tf.Session()\\\\#初始化所有TensorFlow变量\\sess.run(init)\\\\#训练该线性模型,每隔20次迭代,输出模型参数\\for step in range(201):\\ sess.run(train)\\ if step % 20 == 0:\\ print(step, sess.run(W), sess.run(b))\\\\分布式TensorFlow应用架构
\\2016年4月14日,Google发布了分布式TensorFlow,能够支持在几百台机器上并行训练。分布式的TensorFlow由高性能的gRPC库作为底层技术支持。TensorFlow集群由一系列的任务组成,这些任务执行TensorFlow的图计算。每个任务会关联到TensorFlow的一个服务,该服务用于创建TensorFlow会话及执行图计算。TensorFlow集群也可以划分为一个或多个作业,每个作业可以包含一个或多个任务。在一个TensorFlow集群中,通常一个任务运行在一个机器上。如果该机器支持多GPU设备,可以在该机器上运行多个任务,由应用程序控制任务在哪个GPU设备上运行。
\\常用的深度学习训练模型为数据并行化,即TensorFlow任务采用相同的训练模型在不同的小批量数据集上进行训练,然后在参数服务器上更新模型的共享参数。TensorFlow支持同步训练和异步训练两种模型训练方式。
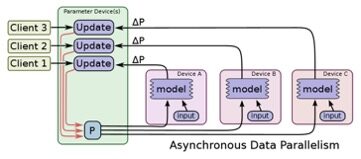
\\异步训练即TensorFlow上每个节点上的任务为独立训练方式,不需要执行协调操作,如下图所示:
\\
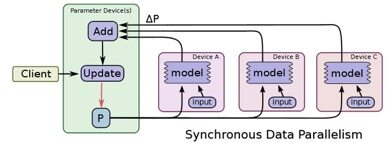
同步训练为TensorFlow上每个节点上的任务需要读入共享参数,执行并行化的梯度计算,然后将所有共享参数进行合并,如下图所示:
\\
分布式TensorFlow 应用开发API主要包括:
\\tf.train.ClusterSpec({\"ps\": ps_hosts, \"worker\": worker_hosts}): 创建TensorFlow集群描述信息,其中ps,worker为作业名称,ps_hosts,worker_hosts为该作业的任务所在节点的地址信息。示例如下:
\\\cluster = tf.train.ClusterSpec({\"worker\": [\"worker0.example.com:2222\

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









