






 本文介绍了一种基于卷积神经网络的图像字幕生成方法,该方法避免了使用LSTM,通过1-D卷积处理句子编码,结合CNN提取图像特征,实现了更快速的训练过程。模型使用了残差链接和注意力机制,以提高图像和文本的匹配度。
本文介绍了一种基于卷积神经网络的图像字幕生成方法,该方法避免了使用LSTM,通过1-D卷积处理句子编码,结合CNN提取图像特征,实现了更快速的训练过程。模型使用了残差链接和注意力机制,以提高图像和文本的匹配度。
Convolutional Image Captioning
2018-11-04 20:42:07
Code: https://github.com/aditya12agd5/convcap
Related Papers:
1. Convolutional Sequence to Sequence Learning Paper Code
常规的 image caption 的任务都是基于 CNN-LSTM 框架来实现的。因为其中有关于 language 的东西,一般采用 RNN 网络模型来处理句子。虽然在很多benchmark 上取得了惊人的效果,但是 LSTM 的训练是一个令人头大的问题。因为他的训练速度特别的慢。所以就有人考虑用 cnn 来处理句子编码的问题,首次提出这种思想的是 Facebook 组的工作。
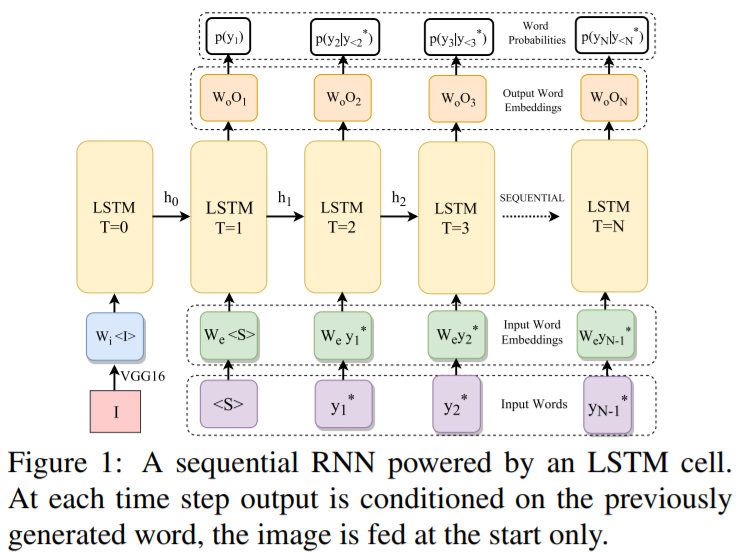
本文将这种思路引入到 image caption 中,利用 卷积的思路来做这个 task,网络结构如下所示:
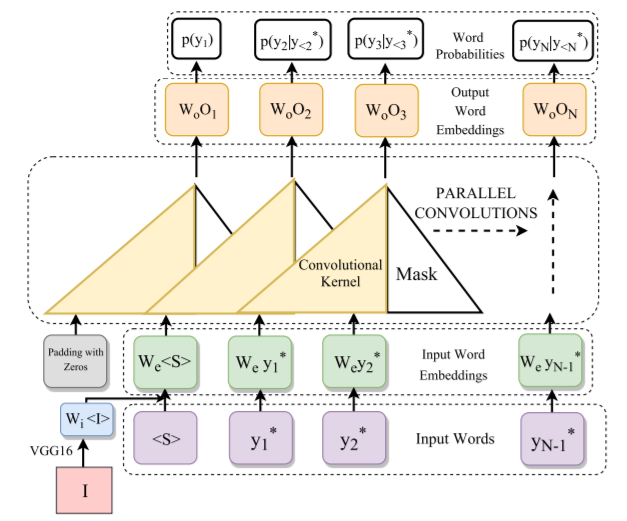
在次基础之上,提出了如下的 model:
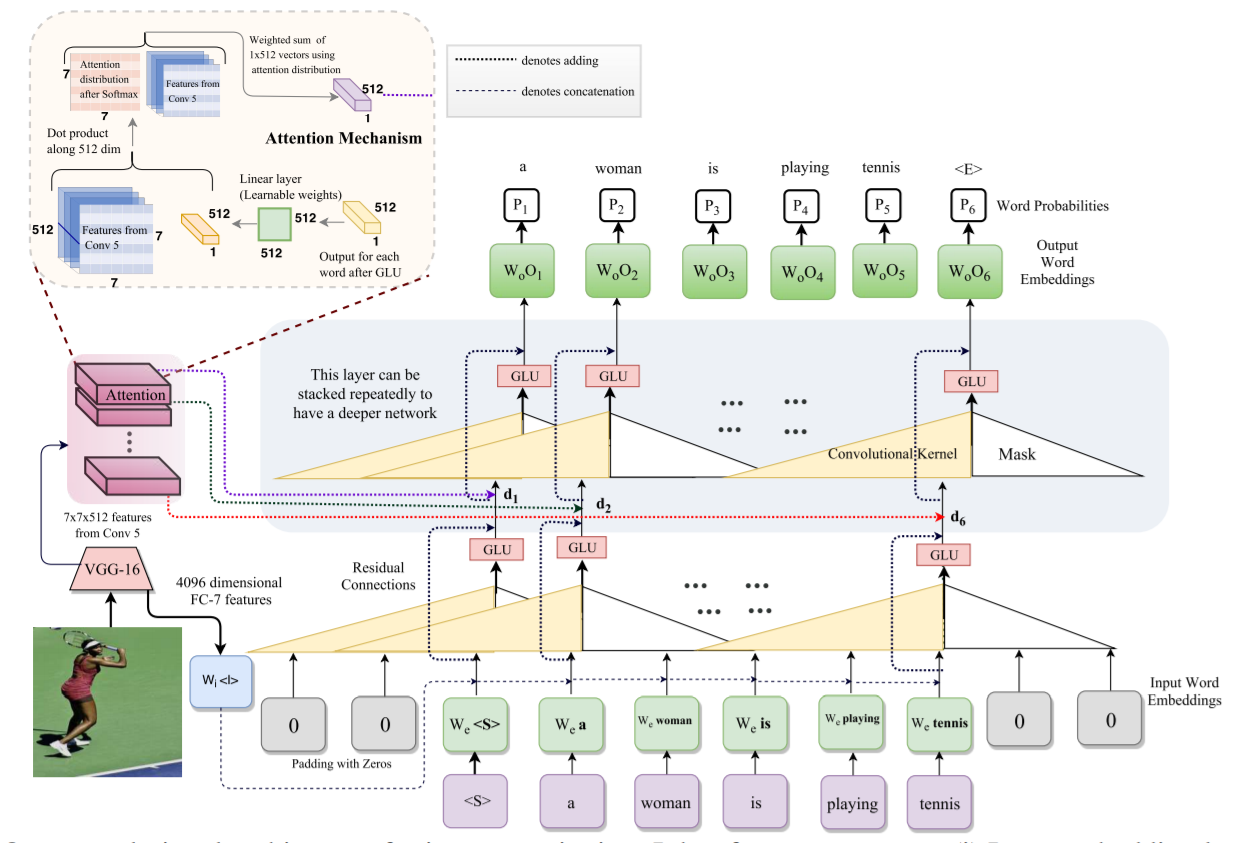
大致思路如下:
1. 首先对给定的句子进行填充(最大句子长度为 15,不足的就补 0),进行 embedding,得到对应的向量表示;
2. 然后用 1-D 的卷积,处理这些一维信号,得到 hidden state,然后输入到 GLU 激活函数当中,然后得到了 embedding 之后的向量;这里的 cnn layer 可以堆叠成多个 layer,以达到 deeper 的效果;
本文模型用了三层该网络;并且用了残差链接,以得到更好的效果;
3. 与此同时,作者用 CNN 提取图像的特征,将图像的特征与文本进行 attention 的计算,得到加权之后的 feature;以得到更好地效果;
4. 然后利用最大化后验概率的方式,给定当前输入,来预测下一个单词是什么。训练采用 Binary Cross-Entropy Loss 来进行。
其中的细节:
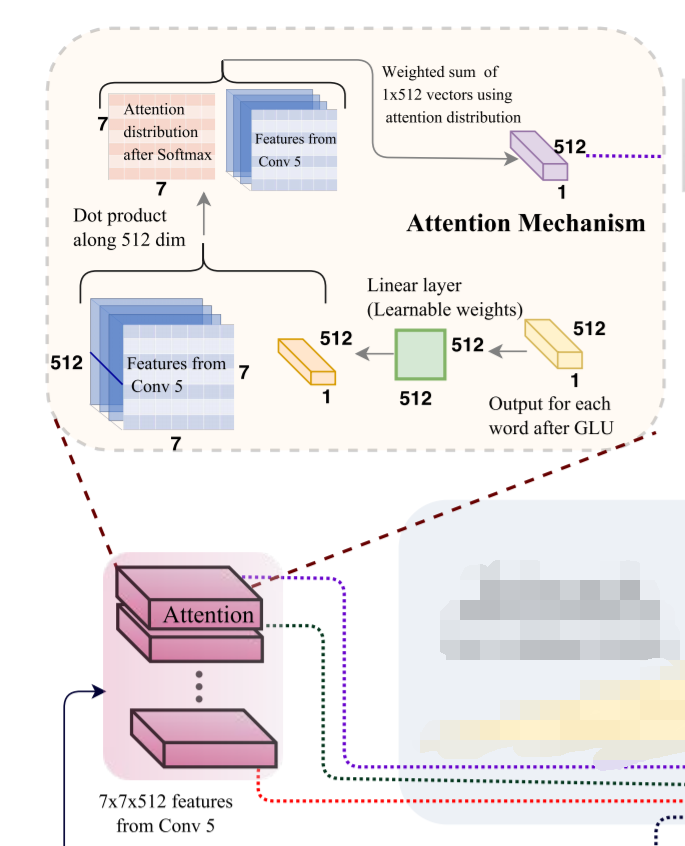
1. Attention 的计算(利用 Word embedding 对 visual feature map 进行 attention 计算):
作者提取 VGG 中 Conv-5 的特征,此时 feature map 的大小为:7*7*512,而 language 中 Word 进行 embedding 后,每一个单词的大小为:512-D。
于是,利用 show,attend and tell 那篇 image caption 文章的 soft-attention 思想,作者也将 text 和 visual feature 进行对齐操作,即:
首先将 512*1 的 vector 的转置,与可学习的权重 512*512 的 weight W,进行相乘,得到 512-D 的向量,然后将该向量与 feature map 上每一个位置上的 channel feature (1*512 D feature)进行点乘,得到一个 512-D 的 feature,于是,w*h 那么大的 feature map,就可以得到一个 w*h 的 权重分布图,即本文中的 7*7 的 attention distribution。用这个权重 和 每一个 channel 的 feature 进行点乘,相加,得到 512*1-D 的特征。
==


















 1972
1972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









