






 本文分享了两个实用技巧:一是利用RFormula进行特征选择,它能自动处理字符串特征的一热编码;二是解决sparklyR读取嵌套数据的问题,通过调用Spark的select和col方法实现数据扁平化。
本文分享了两个实用技巧:一是利用RFormula进行特征选择,它能自动处理字符串特征的一热编码;二是解决sparklyR读取嵌套数据的问题,通过调用Spark的select和col方法实现数据扁平化。
Intro
In an earlier post I talked about Spark and sparklyR and did some experiments. At my work here at RTL Nederland we have a Spark cluster on Amazon EMR to do some serious heavy lifting on click and video-on-demand data. For an R user it makes perfectly sense to use Spark through the sparklyR interface. However, using Spark through the pySpark interface certainly has its benefits. It exposes much more of the Spark functionality and I find the concept of ML Pipelinesin Spark very elegant.
In using Spark I like to share two little tricks described below with you.
The RFormula feature selector
As an R user you have to get used to using Spark through pySpark, moreover, I had to brush up some of my rusty Python knowledge. For training machine learning models there is some help though by using an RFormula
R users know the concept of model formulae in R, it can be handy way to formulate predictive models in a concise way. In Spark you can also use this concept, only a limited set of R operators are available (+, – , . and :) , but it is enough to be useful. The two figures below show a simple example.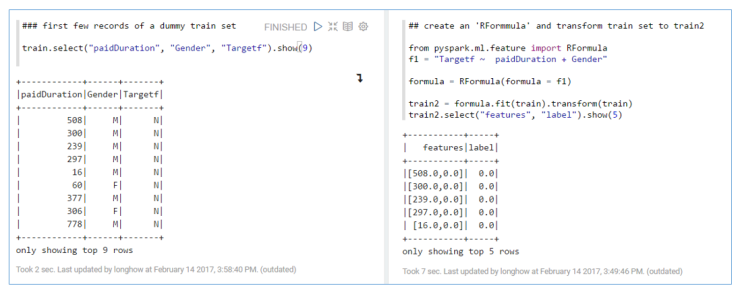
|
1
2
3
4
|
from
pyspark.ml.feature
import
RFormula
f1
=
"Targetf ~ paidDuration + Gender "
formula
=
RFormula(formula
=
f1)
train2
=
formula.fit(train).transform(train)
|
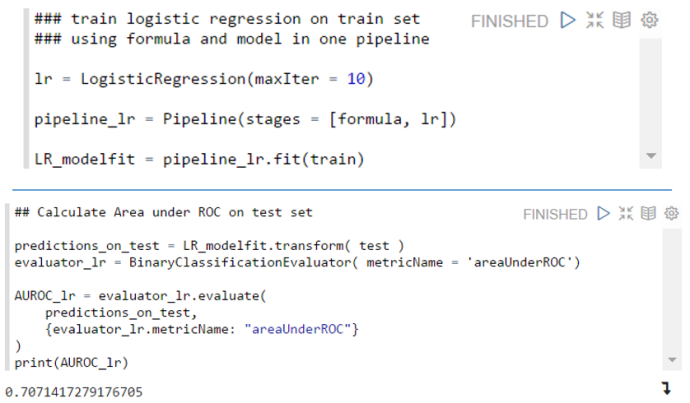
A handy thing about an RFormula in Spark is (just like using a formula in R in lm and some other modeling functions) that string features used in an RFormula will be automatically onehot encoded, so that they can be used directly in the Spark machine learning algorithms.
Nested (hierarchical) data in sparklyR
Sometimes you may find your self with nested hierarchical data. In pySpark you can flatten this hierarchy if needed. A simple example, suppose you read in a parquet file and it has the following structure: Then to flatten the data you could use:
Then to flatten the data you could use: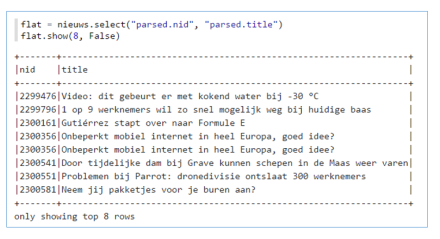 In SparklyR however, reading the same parquet file results in something that isn’t useful to work with at first sight. If you open the table viewer to see the data, you will see rows with: <environment>.
In SparklyR however, reading the same parquet file results in something that isn’t useful to work with at first sight. If you open the table viewer to see the data, you will see rows with: <environment>.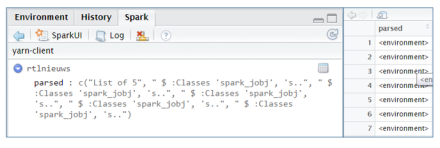 Fortunately, the facilities used internally by sparklyR to call Spark are available to the end user. You can invoke more methods in Spark if needed. So we can invoke the select and col method our self to flatten the hierarchy.
Fortunately, the facilities used internally by sparklyR to call Spark are available to the end user. You can invoke more methods in Spark if needed. So we can invoke the select and col method our self to flatten the hierarchy.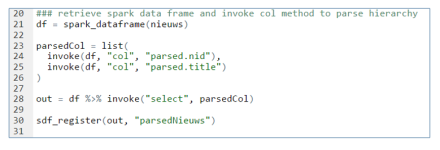 After registering the output object, it is visible in the Spark interface and you can view the content.
After registering the output object, it is visible in the Spark interface and you can view the content.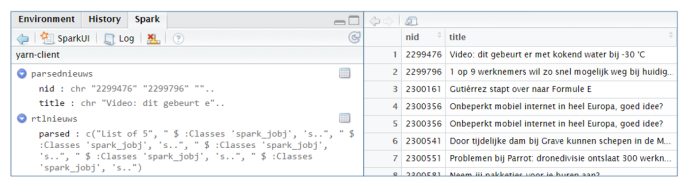
Thanks for reading my two tricks. Cheers, Longhow.
转自:https://longhowlam.wordpress.com/2017/02/15/r-formulas-in-spark-and-un-nesting-data-in-sparklyr-nice-and-handy/


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









