







 本文介绍了如何使用Python爬虫爬取企查查网站的企业信息,包括设置编程环境、分析网页结构、处理登录问题、构造请求头、使用BeautifulSoup和lxml解析HTML,以及将数据存储为Excel格式。通过循环调用爬取函数,实现了爬取十页数据的功能。
本文介绍了如何使用Python爬虫爬取企查查网站的企业信息,包括设置编程环境、分析网页结构、处理登录问题、构造请求头、使用BeautifulSoup和lxml解析HTML,以及将数据存储为Excel格式。通过循环调用爬取函数,实现了爬取十页数据的功能。

今天这个小爬虫是应朋友,帮忙写的一个简单的爬虫,目的是爬取企查查这个网站的企业信息。
编程最终要的就是搭建编程环境,这里我们的编程环境是:
- python3.6
- BeautifulSoup模块
- lxml模块
- requests模块
- xlwt模块
- geany
首先分析需求网页的信息:
http://www.qichacha.com/search?key=婚庆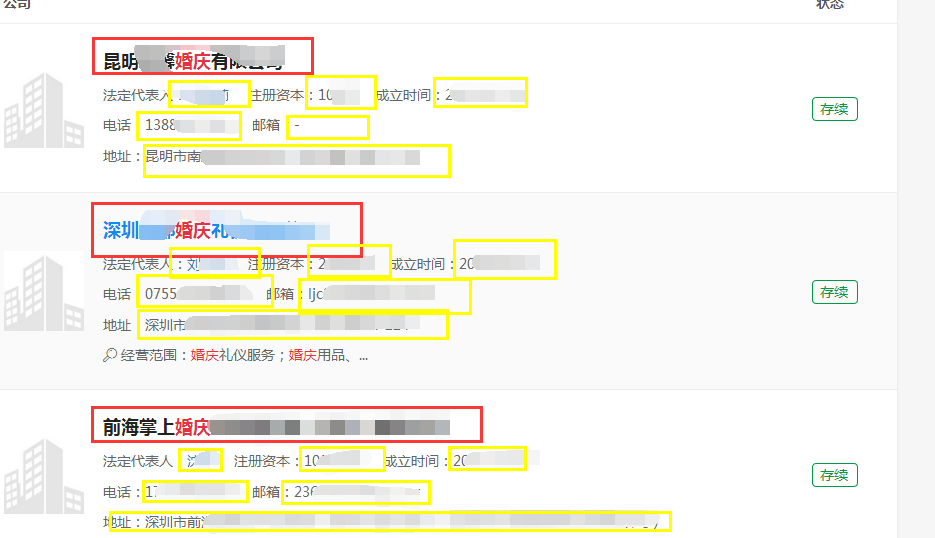
可以看到我们想要提取的消息内容有公司的名字,法定代表人,注册资本,成立时间,电话,邮箱,地址。好的,接下来我们打开firebug,查看各个内容在网页中的具体位置:
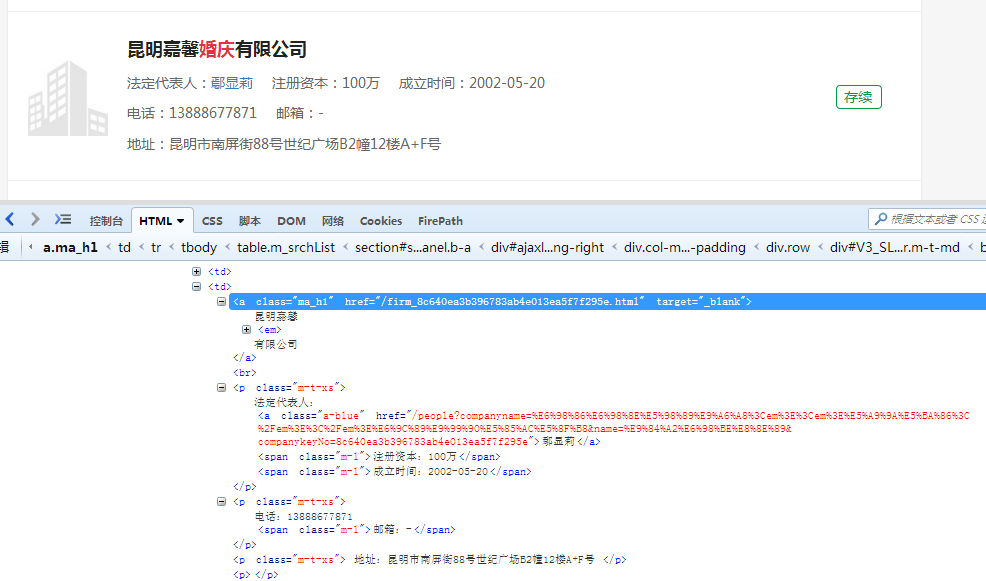
可以看到这些消息分别位于:
#公司名字------<a class="ma_h1" href="/firm_8c640ea3b396783ab4e013ea5f7f295e.html" target="_blank">
# 昆明嘉馨
# <em>
# 有限公司
# </a>
#法定代表人----<p class="m-t-xs">
# 法定代表人:
# <a class="a-blue" href="********">鄢显莉</a>
#注册资本---- <span class="m-l">注册资本:100万</span>
#成立时间---- <span class="m-l">成立时间:2002-05-20</span>
# </p>
# <p class="m-t-xs">
#联系方式---- 电话:13888677871
#公司邮箱---- <span class="m-l">邮箱:-</span>
# </p>
#公司地址---- <p class="m-t-xs"> 地址:昆明市南屏街88号世纪广场B2幢12楼A+F号 </p>
# <p></p>
但是有一个巨大的问题摆在我们面前,企查查在点击搜索按钮后,虽然也能呈现部分资料,但是首当其冲的是一个登录页面,在没有登录前,我们实际上通过爬虫访问到的是仅有前五个公司信息+登录窗口的网页
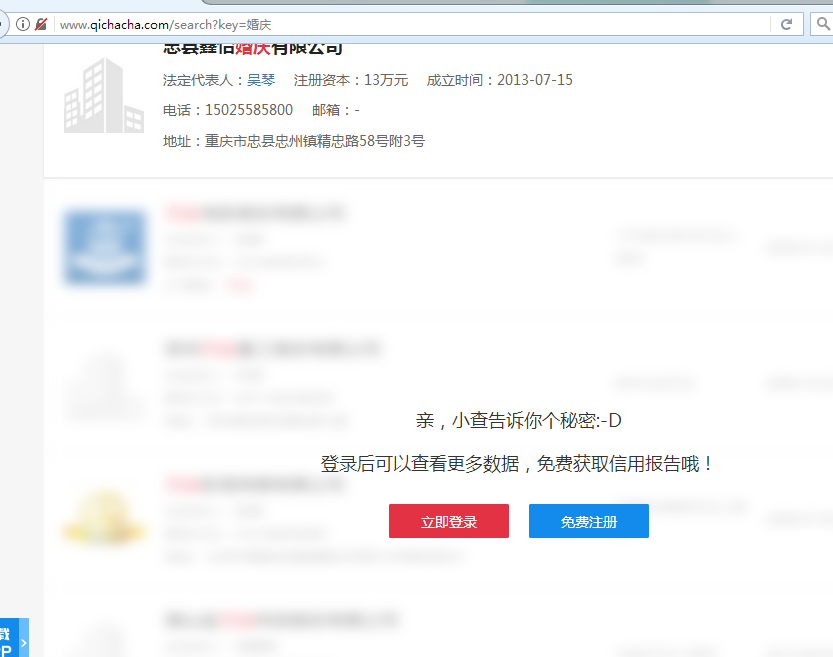
如果我们不处理这个登录页面,那么很抱歉,这次爬取到此结束了。
所以我们必须处理这个问题,首先需要在企查查上注册一个帐号,注册步骤略,一般可以通过
- 构造请求头,配置cookies
- 使用selenium
- requests.post去递交用户名密码等
selenium模拟真实的浏览器去访问页面,但是其访问速度又慢,还要等加载完成,容易报错,直接放弃。
requests.post方法,这个可能可以,没仔细研究,因为企查查登录涉及三个选项,第一个是手机号,第二个是您的密码,第三个是一个滑块,滑块估计需要构造一个True或者什么东西吧。
第一先想肯定是构造请求头,配置一个cookies。在这里我要说明自己犯的一个错误,User-Agent写成了User_agent,导致我的请求头是错误的,访问得到的是一个被防火墙拦截的网页页面,如下:
#-*- coding-8 -*-
import requests
import lxml
from bs4 import BeautifulSoup
def craw(url):
user_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:55.0) Gecko/20100101 Firefox/55.0'
headers = {'User-Agent':user_agent,
}
response = requests.get(url,headers = headers)
if response.status_code != 200:
response.encoding = 'utf-8'
print(response.status_code)
print('ERROR')
soup = BeautifulSoup(response.text,'lxml')
print(soup)
if __name__ == '__main__':
url = r'http://www.qichacha.com/search?key=%E5%A9%9A%E5%BA%86'
s1 = craw(url)代码仅仅是输出soup,方便调试,请求状态是一个405错误,得到的页面如下:
<!DOCTYPE html>
<html lang="zh-cn">
<head>
<meta ch 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









