



 本文详细介绍了Hadoop集群的搭建步骤,包括分布式安装的过程及如何动态增删节点,并解析了Hadoop的安全模式及其操作命令。
本文详细介绍了Hadoop集群的搭建步骤,包括分布式安装的过程及如何动态增删节点,并解析了Hadoop的安全模式及其操作命令。
集群
- 计算机集群是一种计算机系统,他通过一组松散集成的计算机软件和硬件连接起来高度紧密地协同完成计算工作。
- 集群系统中的单个计算机通常称为节点,通常通过局域网连接。
- 集群技术的特点:
1、通过多台计算机完成同一个工作。达到更高的效率
2、两机或多机内容、工作过程等完全一样。如果一台死机,另一台可以起作用
hadoop集群的物理分布
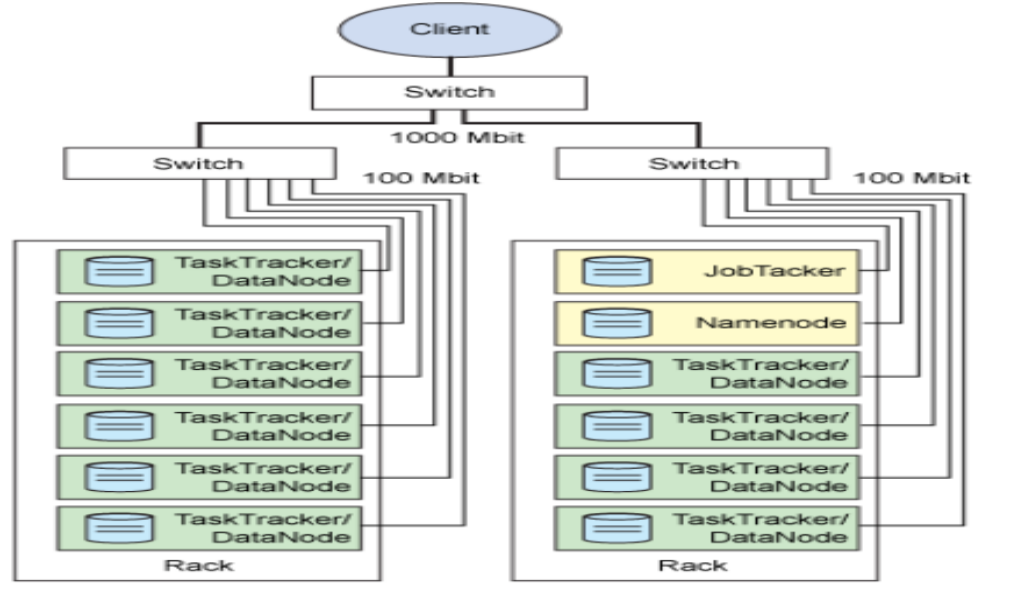
hadoop的分布式安装大致过程(在《伪分布式安装Hadoop》基础上安装)
1.1 分布结构 主节点(1个,是hadoop0):NameNode、JobTracker、SecondaryNameNode
从节点(2个,是hadoop1、hadoop2):DataNode、TaskTracker
1.2 各节点重新产生ssh加密文件
1.3 编辑各个节点的/etc/hosts,在该文件中含有所有节点的ip与hostname的映射信息
1.4 两两节点之间的SSH免密码登陆
ssh-copy-id -i hadoop1
scp /root/.ssh/authorized_keys hadoop1:/root/.ssh/
1.5 把hadoop0的hadoop目录下的logs和tmp删除
1.6 把hadoop0中的jdk、hadoop文件夹复制到hadoop1和hadoop2节点
scp -r /usr/local/jdk hadoop1:/usr/local/
1.7 把hadoop0的/etc/profile复制到hadoop1和hadoop2节点,在目标节点中执行source /etc/profile
1.8 编辑hadoop0的配置文件slaves,改为从节点的hostname,分别是hadoop1和hadoop2
1.9 格式化,在hadoop0节点执行hadoop namenode -format
1.10 启动,在hadoop0节点执行start-all.sh
****注意:对于配置文件core-site.xml和mapred-site.xml在所有节点中都是相同的内容。
2.动态的增加一个hadoop节点(将hadoop0变成hadoop0的一个从节点)
stop-all.sh
2.1 配置新节点的环境
2.2 把新节点的hostname配置到主节点的slaves文件中
2.3 在新节点,启动进程
hadoop-daemon.sh start datanode
hadoop-daemon.sh start tasktracker
2.4 在主节点执行脚本 hadoop dfsadmin -refreshNodes
3.动态的下架一个hadoop节点
kill -9 DataNode进程号
*****************************************************************
* 集群搭建实际操作步骤在《伪分布式安装Hadoop》基础上安装 *
*****************************************************************
这下面是自己实际搭建过程中的详细操作步骤:
1、Hadoop集群的搭建步骤(在《伪分布式安装Hadoop》基础上):
将之前搭建的伪分布式Hadoop的虚拟机,克隆多个。
VM--->虚拟机--->管理--->克隆--->完整克隆
2、配置克隆的两个虚拟机的ip和修改三个虚拟机的主机名
配置ip:
hadoop0 192.168.80.100
hadoop1 192.168.80.101
hadoop2 192.168.80.102
IP配置好了,重启网卡,看是否配置成功。service network restart
修改主机名:
vi /etc/sysconfig/network
修改完主机名后,重启虚拟机,reboot -h now
修改之前的虚拟机hadoop0主机名:
vi /etc/sysconfig/network ---修改主机名
vi /etc/hosts ---修改ip和主机名的映射文件
修改配置文件里的主机名:
cd /usr/local/hadoop/conf
vi core-site.xml
vi mapred-site.xml
修改完,重启reboot -h now
将克隆的虚拟机中的一些文件删除掉:
cd /root/.ssh/
ls
rm -rf *
cd /usr/local/
ls
rm -rf *
将hadoop1和hadoop2中的环境变量也删除掉:
vi /etc/profile
设置三个节点的免密码登录:
ssh-keygen -t rsa
cd /root/.ssh/
cat id_rsa.pub >> authorized_keys ---cat XXX >> YYY:向YYY文件中追加内容XXX
ssh localhost
exit
vi /etc/hosts ---先写好映射文件
ssh hadoop1 ---再免密码登录时才会成功
hadoop0的主机名修改了,所以也要重新设置免密码登录!
三个虚拟机之间也应该要互相ping通(互相能访问):所以每个虚拟机的/etc/hosts中要有三个虚拟机的ip和主机名映射!!
1、手动修改三个虚拟机中的/etc/hosts
vi /etc/hosts
192.168.80.100 hadoop0
192.168.80.101 hadoop1
192.168.80.102 hadoop2
2、然后需要将自己的公钥复制给对方,这样自己访问对方的时候才不会要密码登录(注意:要是hadoop1和hadoop2没有网络连接,需要关闭虚拟机,重新将mac地址生成一次!)
hadoop0:ssh-copy-id -i hadoop1
ssh hadoop1
hadoop1:可以查看到是否有hadoop0的公钥
more authorzied_keys
这样hadoop0访问hadoop1的时候,就可以直接访问,不需要输入hadoop1的密码了。
同理,在hadoop2中再操作一遍,也能免密码登录hadoop1。
这样在hadoop1中more authorized_keys中就会有三个主机的公钥。为了简化操作,可以将其复制给其他两个主机中:
scp /root/.ssh/authorized_keys hadoop0:/root/.ssh/
scp /root/.ssh/authorized_keys hadoop2:/root/.ssh/
将hadoop0中/usr/local/hadoop/下的logs和tmp删除掉:
cd /usr/local/hadoop/
rm -rf logs/
rm -rf tmp/
把hadoop0中的jdk、hadoop文件夹复制到其他两个节点:
scp -r /usr/local/jdk hadoop1:/usr/local/
scp -r /usr/local/jdk hadoop2:/usr/local/
scp -r /usr/local/hadoop hadoop1:/usr/local/
scp -r /usr/local/hadoop hadoop2:/usr/local/
将hadoop0中的环境变量复制到其他两个节点中:
scp /etc/profile hadoop1:/etc/
scp /etc/profile hadoop2:/etc/
复制完了以后,在hadoop1和hadoop2中分别都执行source /etc/profile
在主节点hadoop0中/usr/local/hadoop/conf/下,将slaves里面的localhost删除掉,修改为hadoop1和hadoop2这两个从节点的主机名
vi slaves
hadoop1
hadoop2
在hadoop0中执行格式化操作:hadoop namenode -format
再在hadoop0上执行start-all.sh就可以启动hadoop集群了
然后可以在各个节点上查看相关情况:jps
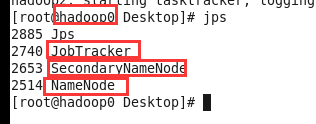
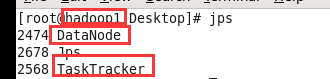
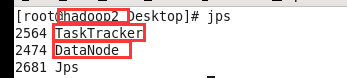
也可以通过浏览器查看:hadoop0:50070 (需要在Windows中的hosts修改ip和主机名的映射)
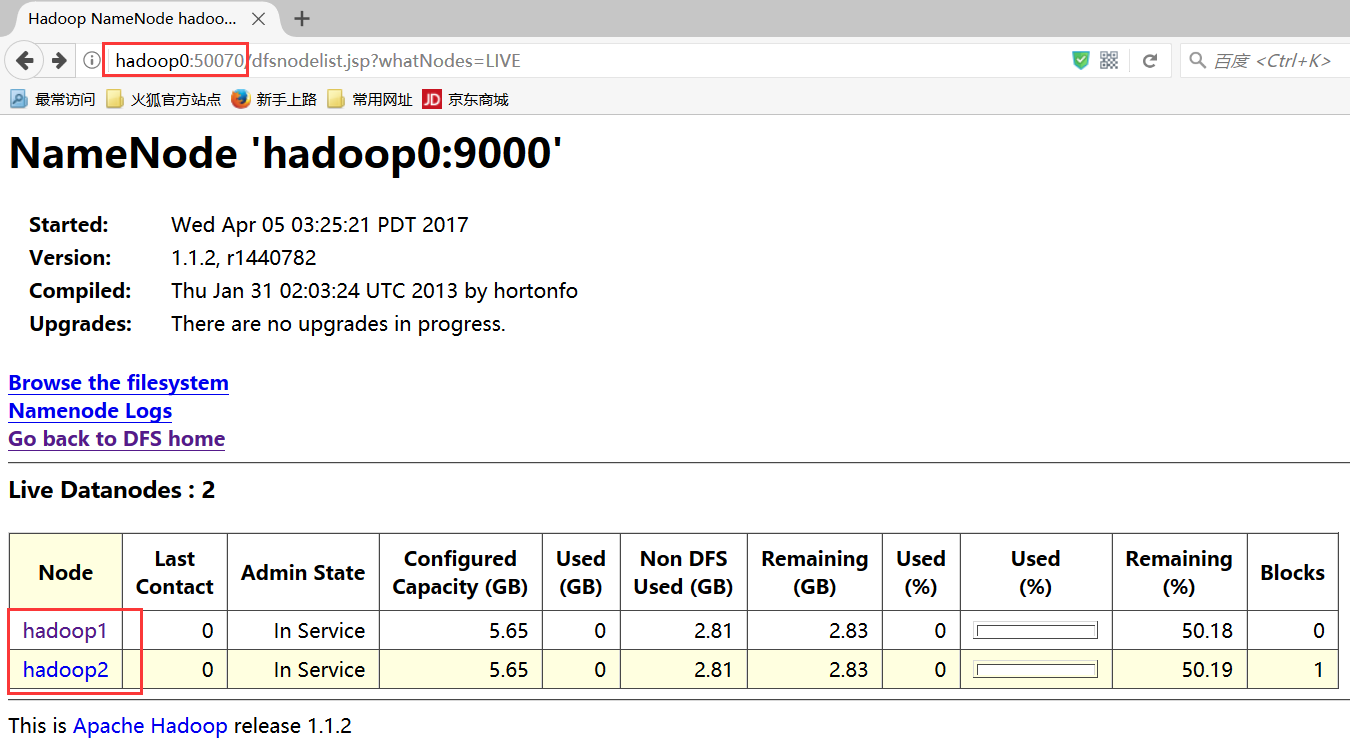
*可以将SecondaryNameNode改为其他的节点上,可以是一个独立的主机,这里将其改为hadoop1上:
vi masters
将里面的localhost改为hadoop1
安全模式
在分布式文件系统启动的时候,开始的时候会有安全模式,当分布式文件系统处于安全模式的情况下,文件系统中的内容不允许修改也不允许删除,
直到安全模式结 束。安全模式主要是为了系统启动的时候检查各个DataNode上数据块的有效性,同时根据策略必要的复制或者删除部分数据块。
运行期通过命令也可以进入 安全模式。在实践过程中,系统启动的时候去修改和删除文件也会有安全模式不允许修改的出错提示,只需要等待一会
儿即可。
NameNode在启动的时候首先进入安全模式,如果datanode丢失的block达到一定的比例(1- dfs.safemode.threshold.pct),则系统会一直处于安全
模式状态即只读状态。 dfs.safemode.threshold.pct(缺省值0.999f)表示HDFS启动的时候,如果DataNode上报的block个数达到了 元数据记录的
block个数的0.999倍才可以离开安全模式,否则一直是这种只读模式。如果设为1则HDFS永远是处于SafeMode。
hadoop dfsadmin -safemode enter ---进入安全模式
hadoop dfsadmin -safemode leave ---离开安全模式
hadoop dfsadmin -safemode get ---查看安全模式状态
hadoop dfsadmin -safemode wait

















 2213
2213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









