 SQL排名函数详解
SQL排名函数详解




 本文深入探讨了SQLServer中不同版本的行号计算方法,包括ROW_NUMBER函数、基于集合的解决方案、基于游标的解决方案及基于IDENTITY的解决方案。通过实际案例对比了各种方法的性能表现。
本文深入探讨了SQLServer中不同版本的行号计算方法,包括ROW_NUMBER函数、基于集合的解决方案、基于游标的解决方案及基于IDENTITY的解决方案。通过实际案例对比了各种方法的性能表现。
示例中用的表和数据
if OBJECT_ID ('Sales') is not null
drop table Sales;
create table Sales
(
empid varchar(10) not null primary key,
mgrid varchar(10) not null,
qty int not null
)
insert into Sales (empid ,mgrid ,qty ) values ('A','Z',300);
insert into Sales (empid ,mgrid ,qty ) values ('E','Z',250);
insert into Sales (empid ,mgrid ,qty ) values ('F','Z',200);
insert into Sales (empid ,mgrid ,qty ) values ('G','Z',100);
insert into Sales (empid ,mgrid ,qty ) values ('I','Y',300);
insert into Sales (empid ,mgrid ,qty ) values ('D','Y',200);
insert into Sales (empid ,mgrid ,qty ) values ('J','Y',150);
insert into Sales (empid ,mgrid ,qty ) values ('B','X',100);
insert into Sales (empid ,mgrid ,qty ) values ('H','X',100);
insert into Sales (empid ,mgrid ,qty ) values ('C','X',200);
insert into Sales (empid ,mgrid ,qty ) values ('K','X',250);
create index idx_qty_empid on Sales(qty,empid)
create index idx_mgrid_qty_empid on Sales(mgrid,qty,empid)
ROW_NUMBER函数MSDN的解释:返回结果集分区内行的序列号,每个分区的第一行从 1 开始。也就是说ROW_NUMBER函数按指定的顺序为查询结果集中的行分配连续的整数,并可选择在每个分区内单独的分配。
语法:ROW_NUMBER ( ) OVER ( [ <partition_by_clause> ] <order_by_clause> )
参数:
1、<partition_by_clause> 将 FROM 子句生成的结果集划入应用了 ROW_NUMBER 函数的分区。
2、<order_by_clause> 确定将 ROW_NUMBER 值分配给分区中的行的顺序。当在排名函数中使用 <order_by_clause> 时,不能用整数表示列。
例如:下面的查询返回员工的销售数据,并按qty的顺序分配行号。
查询结果:
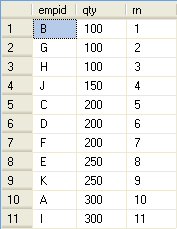

为了计算排名值,优化器会先按分区列和排序列对数据进行排序。Segment主要用于确定分区边界,是一个分区内的行返回“TRUE”,否则返回“FALES”。示例没有指定Partition字段,所以整个表就是一个分区。Compute Scalar用回答当前值是否不等于前一个值。对于ROW_NUMBER,排名值必须为每一行递增,不管排序值是否变化,所示例中Compute Scalar的值永远返回“TRUE”。
此查询计划和优化器计算排名值的方法可能还不太明显,但可以肯定的是数据保被扫描了一次。这比SQL Server 2000中计算排名值的方法要快的多。
分区排名:
所有排名值计算都可以由统计行数实现。要计算行号,你可以使用下面的基本方法,用子查询统计具有更小或相等排序值的行数,得到的行数就是期望的行号。例如下面的查询将成生基于empid排序的行号。
查询结果:
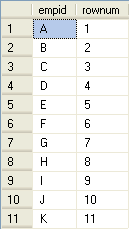
尽管这种方法计算行号的方法很简单,但是它执行非常慢。为什么呢?我们来查看一下它的执行计划。
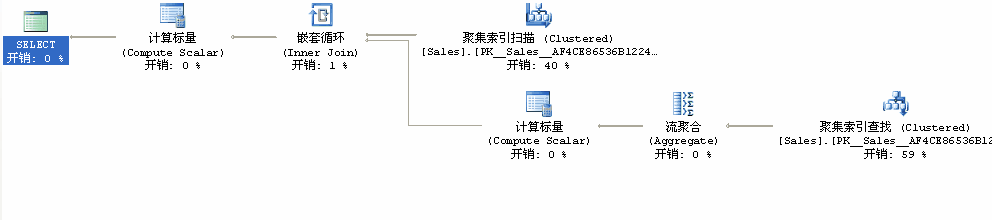
排序列的索引是Sales表的聚合索引,执行计划完整的扫描整个表(Clustered运算)返回所有行,对于扫描返回的每一行,嵌套循环运算将调用通过统计行数生成行号的操作。每次行号计算都要调用一次对聚合索引查找操作,然后再执行局部扫描操作,以完成统计。
大家可能都知道,影响查询性能的主要因素通常就是I/O操作。粗略地估计一下此计划所访问的行数就可以说明此查询为什么为如此的低效。要计算表的第一行的rownum,SQL Server要扫描索引表1行,对于第二行,则要扫描索引表2行,对于第三行,需要扫描索引表3行,等等。对于表的第N行,它需要扫描N行。对于包含N行且在排序列具有索引的表扫描总行数是:1+2+3+ …… +N。你可能没有马上意识到被扫描的行数有多庞大,对于一个包含100000行的表,总共会扫描5000050000行。当表没有索引时,情况就更加糟糕了。每计算一个号都要扫描整个表,查询扫描的总行数将会是N*N,同样的表,扫描的总行数为10000000000。
分区排名:
select mgrid,empid,qty ,(select COUNT (*) from Sales as S2 where S2.mgrid =S1.mgrid and (S2.qty <S1.qty or (S2.qty =S1.qty and S2.empid <=S1.empid ))) as rownum from Sales as S1 order by mgrid,qty,empid ;
三、基于游标的解决方案
你也可以用游标来计算行号,相对于上述方案,基于游标的解决方案就非常简单明了。创建一个快速向前的游标,它的查询按分区表,排序列和附加列排序。当你从游标提取行时递增计数器,并在检测到新分区时重置此计数器。你可以把结查列和行号存储到临时表或表变量。例如:使用游标按qyt和empid 的顺序计算行号。
declare @salesRN table (empid varchar (5),qty int ,rn int);
declare @empid as varchar(5) ,@qty as int ,@rn as int;
begin tran
declare rncursor Cursor FAST_FORWARD for select empid,qty from Sales order by qty,empid ;
open rncursor;
set @rn =0;
fetch next from rncursor into @empid,@qty;
while @@FETCH_STATUS =0
begin
set @rn=@rn+1;
insert into @salesRN (empid ,qty ,rn ) values (@empid ,@qty ,@rn);
fetch next from rncursor into @empid,@qty;
end
close rncursor;
deallocate rncursor;
commit tran
select * from @salesRN
执行结果:
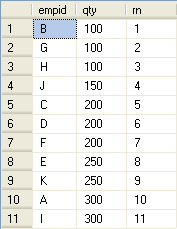
一般来说,应该尽量避免使用游标,因为游标包含许多的开销,会影响性能的。本示例中,除非分区非常小,否则基于游标的解决方案要比基于集合的解决方案的速度更快,因为它只扫描数据表一次。这主意味着随着表越来越大,游标方案呈线性下降,而集合方案是按N*N的速度下降。
四、基于IDENTITY的解决方案
在SQL Server 2005之前的版本中,你可以利用IDENTITY函数和IDENTITY列属性来计算行号。用IDENTITY来计算行号是一个非常有用的方法。IDENTITY函数和IDENTITY列属性唯一的区别是:IDENTITY函数无法保证IDENTITY值的分配顺序,但是IDENTITY列属性可以保证。
未分区 在 SELECT INTO 语句中使用IDENTITY函数是到目前为止在SQL Server 2005之前的版本中计算行号最快的方法。原因是因为它只扫描表一次,而且没有游标操作的开销。
例如下面代码演示了如何用IDENTITY函数创建临时表,并用没有任何特定顺序的行号来填充此表。
select * from #SalesRN;
drop table #SalesRN;
查询结果:
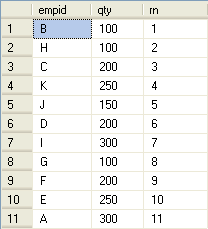
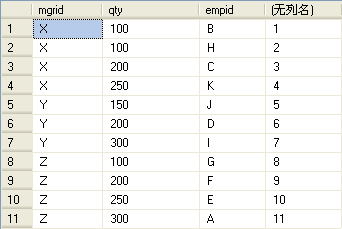
已分区 当你在乎IDENTITY值的分配顺序时---换句话说,当行号应该基于指定顺序时---先创建表,然后加载数据。这个方法没有SELECT TNTO方法快,因为INSERT SELECT总是被完整记录日志。不过它还是比SQL Server 2005之前的版本快得多。用IDENTITY来生成分区行号要求执行额外的一步:行号=分区内最小行号+1。下面是按qty和empid计算行号的示例:
create table #SalesRN (mgrid varchar(5),empid varchar(5),qty int,rownum int identity);
insert into #SalesRN (mgrid,empid ,qty ) select mgrid,empid,qty from Sales order by mgrid,qty ,empid ;
select mgrid,qty,empid,rownum-(select MIN(rownum) from #SalesRN as S2 where S2.mgrid =S2 .mgrid) +1 from #SalesRN as S1
drop table #SalesRN
查询结查:
五、
系统配置:CPU:Inter (R) Pentium(R) 4 CPU 3.40GHz 内存:1G 硬盘:WDC wd800jd-60lsa5
测试代码如下:
 set nocount on;goif OBJECT_ID ('RNBenchmark')is not null drop table RNBenchmark;if OBJECT_ID('RNTechniques')is not null drop table RNTechniques;if OBJECT_ID ('SalesBM') is not null drop table SalesBMif OBJECT_ID ('SalesBMIdentity') is not null drop table SalesBMIdentity;if OBJECT_ID ('SalesBMCursor') is not null drop table SalesBMCursor;if OBJECT_ID ('Nums') is not null drop table Nums;gocreate table Nums(n int not null primary key);godeclare @max int ,@rc int set @max =1000000set @rc =1;insert into Nums values (1)while @rc * 2<=@max begin insert into Nums select Nums.n +@rc from Nums ; set @rc =@rc * 2;endinsert into Nums select Nums.n+@rc from Nums where n+@rc<=@max;gocreate table RNTechniques(tid int not null primary key,technique varchar(25) not null);insert into RNTechniques(tid ,technique ) values (1,'Set_Based_2000');insert into RNTechniques(tid ,technique ) values (2,'IDENTITY');insert into RNTechniques(tid ,technique ) values (3,'CURSOR');insert into RNTechniques(tid ,technique ) values (4,'ROW_NUMBER_2005');gocreate table RNBenchmark( tid int not null references RNTechniques(tid), numrows int not null, runtimes bigint not null, primary key (tid,numrows));gocreate table SalesBM( empid int not null IDENTITY primary key, qty int not null);create index idx_qty_empid on SalesBM(qty,empid);gocreate table SalesBMIdentity(empid int ,qty int,rn int identity );gocreate table SalesBMCursor(empid int ,qty int,rn int );godeclare @maxnumrows as int,@steprows as int,@curnumrows as int,@dt as datetime;set @maxnumrows =100000;set @steprows =10000;set @curnumrows =10000;while @curnumrows <=@maxnumrows begin truncate table SalesBM; insert into SalesBM(qty ) select CAST (1+999.9999999999*RAND(CHECKSUM(NEWID())) as int) from Nums where n<@curnumrows ; ---Set-Based 2000 dbcc FREEPROCCACHE with NO_INFOMSGS; dbcc DROPCLEANBUFFERS with NO_INFOMSGS; set @dt =GETDATE (); select empid,qty ,(select COUNT (*) from SalesBM as S2 where S2.qty <S1.qty or (S2.qty =S1.qty and S2.empid <=S1.empid)) as rn from SalesBM as S1 order by qty,empid ; insert into RNBenchmark (tid,numrows ,runtimes ) values (1,@curnumrows ,DATEDIFF (MS,@dt,GETDATE())); ---IDENTITY truncate table SalesBMIdentity; dbcc FREEPROCCACHE with NO_INFOMSGS; dbcc DROPCLEANBUFFERS with NO_INFOMSGS; set @dt =GETDATE (); insert into SalesBMIdentity(empid ,qty ) select empid,qty from SalesBM order by qty ,empid ; select * from SalesBMIdentity; insert into RNBenchmark (tid,numrows ,runtimes ) values (2,@curnumrows ,DATEDIFF (MS,@dt,GETDATE())); ---Cursor truncate table SalesBMCursor; dbcc FREEPROCCACHE with NO_INFOMSGS; dbcc DROPCLEANBUFFERS with NO_INFOMSGS; set @dt =GETDATE (); declare @empid as int ,@qty as int ,@rn as int; begin tran declare rncursor Cursor FAST_FORWARD for select empid,qty from SalesBM order by qty,empid ; open rncursor; set @rn =0; fetch next from rncursor into @empid,@qty; while @@FETCH_STATUS =0 begin set @rn=@rn+1; insert into SalesBMCursor (empid ,qty ,rn ) values (@empid ,@qty ,@rn); fetch next from rncursor into @empid,@qty; end close rncursor; deallocate rncursor; commit tran insert into RNBenchmark (tid,numrows ,runtimes ) values (3,@curnumrows ,DATEDIFF (MS,@dt,GETDATE())); ----ROW_NUMBER 2005 dbcc FREEPROCCACHE with NO_INFOMSGS; dbcc DROPCLEANBUFFERS with NO_INFOMSGS; set @dt =GETDATE (); select empid ,qty,ROW_NUMBER () over(order by qty,empid ) as rn from SalesBM order by qty,empid ; insert into RNBenchmark (tid,numrows ,runtimes ) values (4,@curnumrows ,DATEDIFF (MS,@dt,GETDATE())); set @curnumrows =@curnumrows+@steprows;end;goselect numrows ,[Set_Based_2000],[IDENTITY],[CURSOR],[ROW_NUMBER_2005] from (select technique , numrows ,runtimes from RNBenchmark as B join RNTechniques as T on B.tid =T .tid ) as D pivot (max(runtimes) for technique in ([Set_Based_2000],[IDENTITY],[CURSOR],[ROW_NUMBER_2005])) as p order by numrows ;
set nocount on;goif OBJECT_ID ('RNBenchmark')is not null drop table RNBenchmark;if OBJECT_ID('RNTechniques')is not null drop table RNTechniques;if OBJECT_ID ('SalesBM') is not null drop table SalesBMif OBJECT_ID ('SalesBMIdentity') is not null drop table SalesBMIdentity;if OBJECT_ID ('SalesBMCursor') is not null drop table SalesBMCursor;if OBJECT_ID ('Nums') is not null drop table Nums;gocreate table Nums(n int not null primary key);godeclare @max int ,@rc int set @max =1000000set @rc =1;insert into Nums values (1)while @rc * 2<=@max begin insert into Nums select Nums.n +@rc from Nums ; set @rc =@rc * 2;endinsert into Nums select Nums.n+@rc from Nums where n+@rc<=@max;gocreate table RNTechniques(tid int not null primary key,technique varchar(25) not null);insert into RNTechniques(tid ,technique ) values (1,'Set_Based_2000');insert into RNTechniques(tid ,technique ) values (2,'IDENTITY');insert into RNTechniques(tid ,technique ) values (3,'CURSOR');insert into RNTechniques(tid ,technique ) values (4,'ROW_NUMBER_2005');gocreate table RNBenchmark( tid int not null references RNTechniques(tid), numrows int not null, runtimes bigint not null, primary key (tid,numrows));gocreate table SalesBM( empid int not null IDENTITY primary key, qty int not null);create index idx_qty_empid on SalesBM(qty,empid);gocreate table SalesBMIdentity(empid int ,qty int,rn int identity );gocreate table SalesBMCursor(empid int ,qty int,rn int );godeclare @maxnumrows as int,@steprows as int,@curnumrows as int,@dt as datetime;set @maxnumrows =100000;set @steprows =10000;set @curnumrows =10000;while @curnumrows <=@maxnumrows begin truncate table SalesBM; insert into SalesBM(qty ) select CAST (1+999.9999999999*RAND(CHECKSUM(NEWID())) as int) from Nums where n<@curnumrows ; ---Set-Based 2000 dbcc FREEPROCCACHE with NO_INFOMSGS; dbcc DROPCLEANBUFFERS with NO_INFOMSGS; set @dt =GETDATE (); select empid,qty ,(select COUNT (*) from SalesBM as S2 where S2.qty <S1.qty or (S2.qty =S1.qty and S2.empid <=S1.empid)) as rn from SalesBM as S1 order by qty,empid ; insert into RNBenchmark (tid,numrows ,runtimes ) values (1,@curnumrows ,DATEDIFF (MS,@dt,GETDATE())); ---IDENTITY truncate table SalesBMIdentity; dbcc FREEPROCCACHE with NO_INFOMSGS; dbcc DROPCLEANBUFFERS with NO_INFOMSGS; set @dt =GETDATE (); insert into SalesBMIdentity(empid ,qty ) select empid,qty from SalesBM order by qty ,empid ; select * from SalesBMIdentity; insert into RNBenchmark (tid,numrows ,runtimes ) values (2,@curnumrows ,DATEDIFF (MS,@dt,GETDATE())); ---Cursor truncate table SalesBMCursor; dbcc FREEPROCCACHE with NO_INFOMSGS; dbcc DROPCLEANBUFFERS with NO_INFOMSGS; set @dt =GETDATE (); declare @empid as int ,@qty as int ,@rn as int; begin tran declare rncursor Cursor FAST_FORWARD for select empid,qty from SalesBM order by qty,empid ; open rncursor; set @rn =0; fetch next from rncursor into @empid,@qty; while @@FETCH_STATUS =0 begin set @rn=@rn+1; insert into SalesBMCursor (empid ,qty ,rn ) values (@empid ,@qty ,@rn); fetch next from rncursor into @empid,@qty; end close rncursor; deallocate rncursor; commit tran insert into RNBenchmark (tid,numrows ,runtimes ) values (3,@curnumrows ,DATEDIFF (MS,@dt,GETDATE())); ----ROW_NUMBER 2005 dbcc FREEPROCCACHE with NO_INFOMSGS; dbcc DROPCLEANBUFFERS with NO_INFOMSGS; set @dt =GETDATE (); select empid ,qty,ROW_NUMBER () over(order by qty,empid ) as rn from SalesBM order by qty,empid ; insert into RNBenchmark (tid,numrows ,runtimes ) values (4,@curnumrows ,DATEDIFF (MS,@dt,GETDATE())); set @curnumrows =@curnumrows+@steprows;end;goselect numrows ,[Set_Based_2000],[IDENTITY],[CURSOR],[ROW_NUMBER_2005] from (select technique , numrows ,runtimes from RNBenchmark as B join RNTechniques as T on B.tid =T .tid ) as D pivot (max(runtimes) for technique in ([Set_Based_2000],[IDENTITY],[CURSOR],[ROW_NUMBER_2005])) as p order by numrows ;测试结果如下:
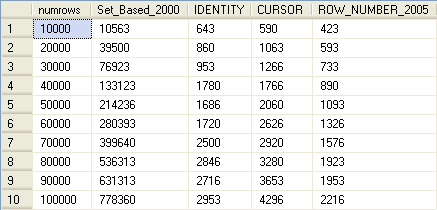
结论如下:
从上表可以轻易的看出那种方法的比较好,在SQL Server 2005中我们应该总是使用新的排名函数。而在SQL Server 2000中,如果基于集合的方案对你来说是很重要,则只有在分区中的行数很少时(数十行)才使用此方法。否则应该使用基于IDENTITY的方案---先创建表,然后加载数据。

















 895
895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









