



 Netflix分享了提高系统可用性的实战经验,包括区域部署、红黑部署策略、使用部署窗口等最佳实践。这些技巧不仅适用于Spinnaker用户,也适用于任何希望提升系统可用性的人。
Netflix分享了提高系统可用性的实战经验,包括区域部署、红黑部署策略、使用部署窗口等最佳实践。这些技巧不仅适用于Spinnaker用户,也适用于任何希望提升系统可用性的人。
在过去四年中,Netflix已从不到5000万用户增加到1.25亿用户。这种增长给我们带来了伸缩性方面的挑战,但实际上,我们已经设法在这段时间内提高了服务的整体可用性。在这个过程中,我们学到了很多东西,我们也更加明白该如何提升系统的可用性。但天下没有免费的午餐,这些经验来之不易:在出现问题时我们忙成一团,有时候还要处理用户事件。尽管我们还没有完全扫清所有的问题,我们的系统仍然还有很多可以改进的地方,但我们分享的这些经验都是从实战中总结出来的。希望你们能够从中收获点什么,以免在凌晨三点钟收到要你起床处理用户事件的电话。
\\在Netflix,我们使用Spinnaker作为持续集成和交付的平台。这里讨论的很多最佳实践都已纳入到Spinnaker中,这些技巧和最佳实践具有通用性,将帮到任何想要提升系统可用性的人。
\\优先考虑区域部署而不是全球部署
\\我们的目标是尽可能提供最佳的客户体验。因此,我们要限制系统变更的影响范围,对变更进行验证,然后将变更推给客户。更具体地说,我们一次只部署一个AWS区域,这为我们的生产部署提供了额外的安全保障。我们能够快速地转移受影响的客户流量,这也是我们最重要的四大补救手段之一。
\\我们还建议在每个区域部署之间对应用程序功能进行验证,并避免在目标区域的高峰时段进行部署。
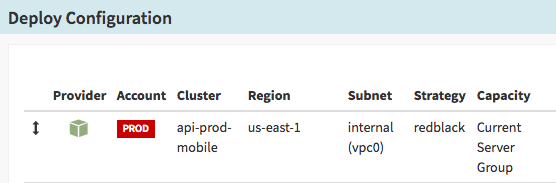
\\在Spinnaker中,指定部署的目标区域非常简单。
\\
使用红黑部署策略进行生产部署
\\在红黑(也称为蓝绿)部署中,新版本的应用程序(红色)在通过健康检查之后立即开始接收流量。在确定红色版本的健康状态之后,之前的(黑色)版本将被禁用,并且不会收到任何流量。如果要回滚,只需要启用以前的版本即可,非常简单。这种模型加快了我们的部署流程,并可以在出现问题时回滚到之前的状态。
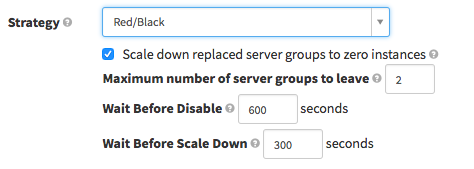
\\要使用Spinnaker完成红黑部署,只需要在管道中指定策略(并可选择性地在策略中设置参数),Spinnaker将负责完成部署。
\\
使用部署窗口
\\每当你在部署新版本应用时,都要记住以下两点:首先,你(或你的同事)是否有监控部署,并在必要时进行补救?第二,如果出现了问题,你是否能够尽可能减小影响范围?
\\我们的流媒体流量遵循相对可预测的模式,大多数人会在晚上打开视频流。因此,我们建议选择工作时段和非高峰时段的部署窗口。
\\Spinnaker为此提供了一个界面,让我们可以轻松地指定运行部署管道的日期和时间。
\\
确保不要在非工作时段或周末自动触发部署
\\部署窗口也适用于自动触发的事件。在Spinnaker中,可以使用cron表达式作为管道触发器,这也可能是一个冒险的策略:有些cron表达式可能会在非工作时段或周末执行管道,但这不是我们所期望的。无论你使用哪一种自动化机制,都要确保任何自动触发的管道都可以在无人值守的模式下运行。
\\
启用Chaos Monkey
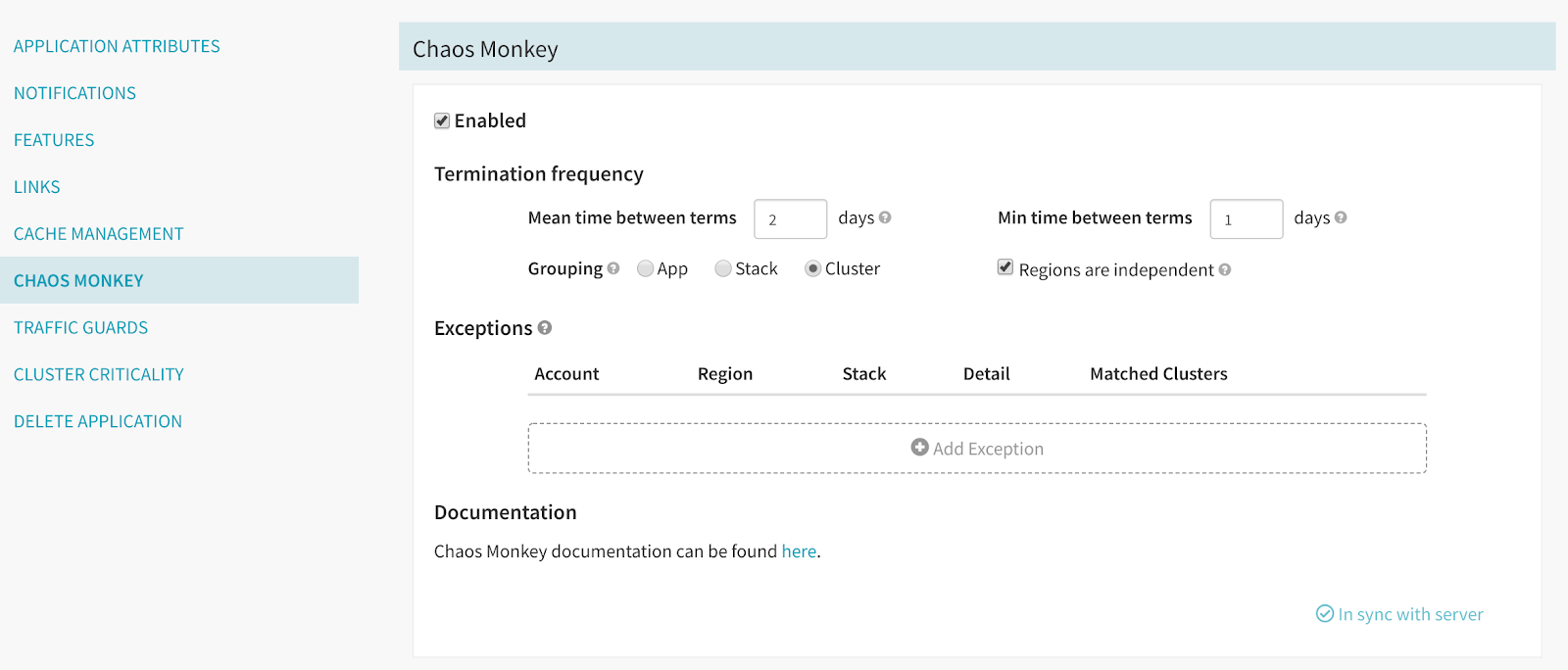
\\Chaos Monkey由Netflix创建并开源,是我们混沌工程工具套件的一部分。Chaos Monkey以不可预测的方式随机终止生产环境中的实例,以此来增强服务,让服务具备应对单实例故障的弹性能力。如果某些服务不具备弹性能力,Chaos Monkey将会暴露出它们的漏洞,服务所有者就可以在这些漏洞演变成影响用户的事故之前修复它们。在Netflix,生产环境中的所有服务都应该启用Chaos Monkey,在Chaos Monkey终止应用程序实例时,服务所有者不应该检测到任何问题。
\\
在将代码推送到生产环境之前使用各种测试和金丝雀分析来验证代码
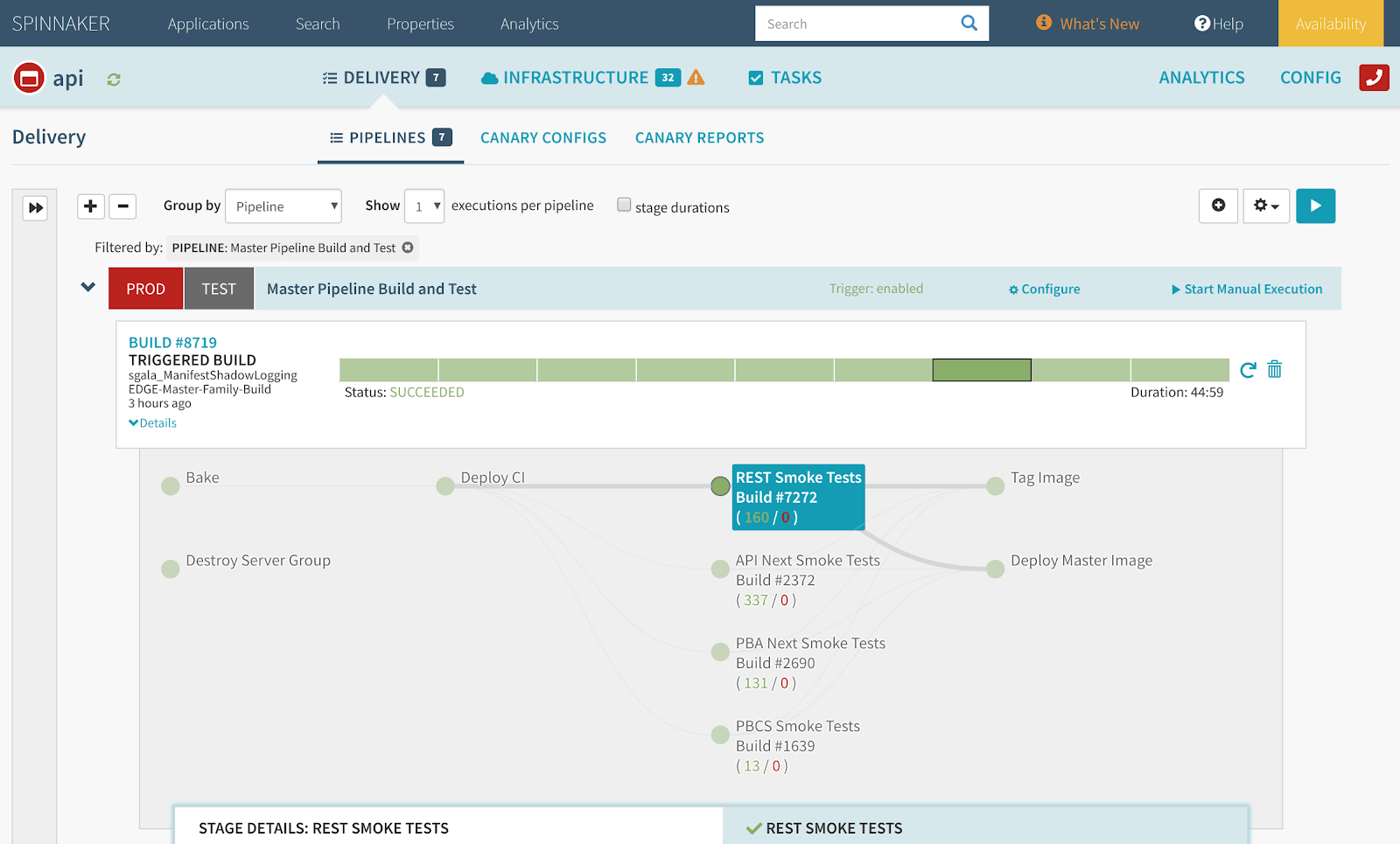
\\实现快速部署的关键是在部署之前自动验证新版本的软件。理想情况下,所有必要的测试套件都应该在没有人工干预的情况下运行。
\\
此外,我们建议使用金丝雀分析。金丝雀分析是一种通过实时流量来验证服务变更的有效方法。最近我们开源了内部工具Kayenta,它可以轻松集成到Spinnaker中,并结合人工判断,成为放开所有生产流量之前的最后一道门槛。
\\
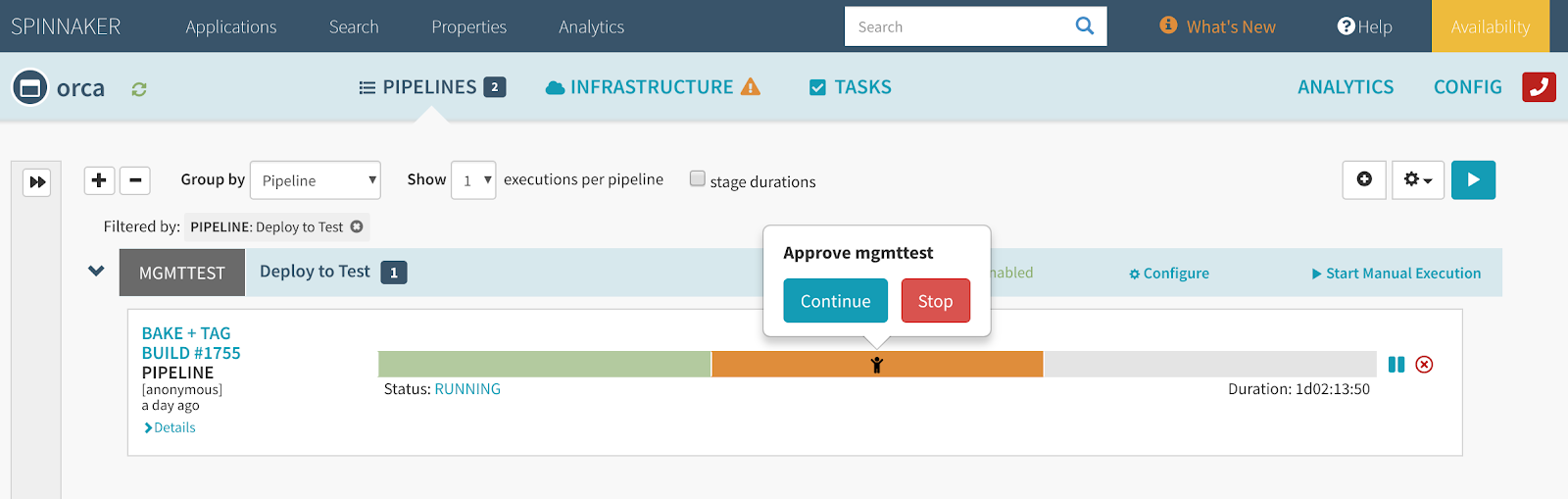
必要的人工干预
\\尽可能使用自动化,但在必要的时候也需要人工干预。例如,在将新版本推向生产环境之前需要检查金丝雀运行的结果。
\\
在部署时尽可能只用已经测试过的东西
\\既然你已经对新版本进行了大量的测试和验证,我们强烈建议你在进行生产环境部署时只用测试过的东西。对于我们来说,我们更倾向于从测试环境中复制经过验证的镜像,而不是重新构建新的镜像。
\\定期检查联系人设置
\\有时候,为了确保应用程序的可用性,你所要做的其实很简单。如果你的应用程序会出问题,并且很可能会在某个时间点出问题,那么此时最重要的是找到能解决问题的人。因此,请定期检查你的联系人设置,这样可以确保在发生事故时能够迅速找到解决问题的人。
\\
Spinnaker提供了一个“Page application owner”按钮,请确保这里配置的信息是最新的,这样就不会在发生问题时找错人。
\\知道如何快速回滚部署
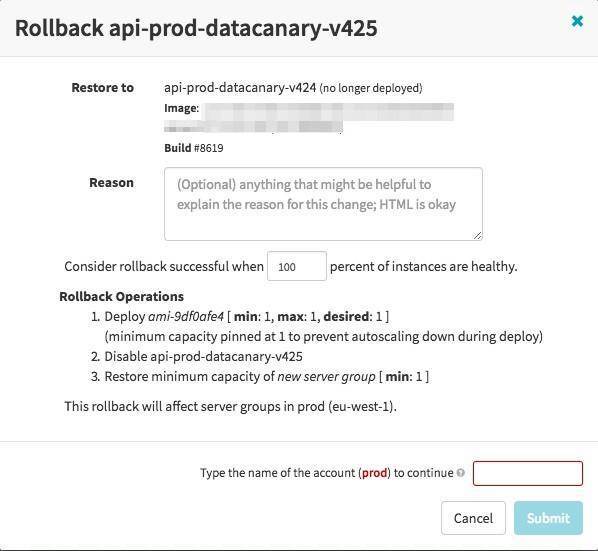
\\即使有可靠的测试、金丝雀和其他验证过程,将某些东西部署到生产环境中仍然会出现问题。也许这是一种由竞态条件导致的罕见错误,只会在达到一定规模时才发生。但无论是何种情况,最重要的是你要知道在必要时如何快速恢复到之前正常的状态。
\\在Spinnaker中,如果应用程序的新版本出现问题,可以通过“Server Group”下的“Rollback”选项进行回滚。回滚将启用你选择的ASG(通常是之前的),并禁用发生故障的ASG。Spinnaker还支持创建可在发生管道故障时执行或通过手动触发的回滚管道。
\\
如果实例运行不正常,将部署视为失败
\\多年来,有几次我们在部署成功后感觉状态不对,实例起来了,但不能正常处理流量。“成功”的部署给我们造成了一种假象,当一个关键的服务运行不正常时,请求很快会堆积起来,有时会导致重试雪崩,造成各种各样的破坏。因此,当实例运行不正常时,要将部署视为失败。
\\Spinnaker提供了一种灵活的方法用于关联实例的健康状况。当一个实例不健康时,Spinnaker会将其标注出来,更重要的是,不健康的实例将收不到流量。如果ASG中的所有实例都不健康,Spinnaker会将部署视为失败。Spinnaker还用不同的颜色来标记实例的状态,如启动中、等待发现、不健康和健康,如下所示。
\\
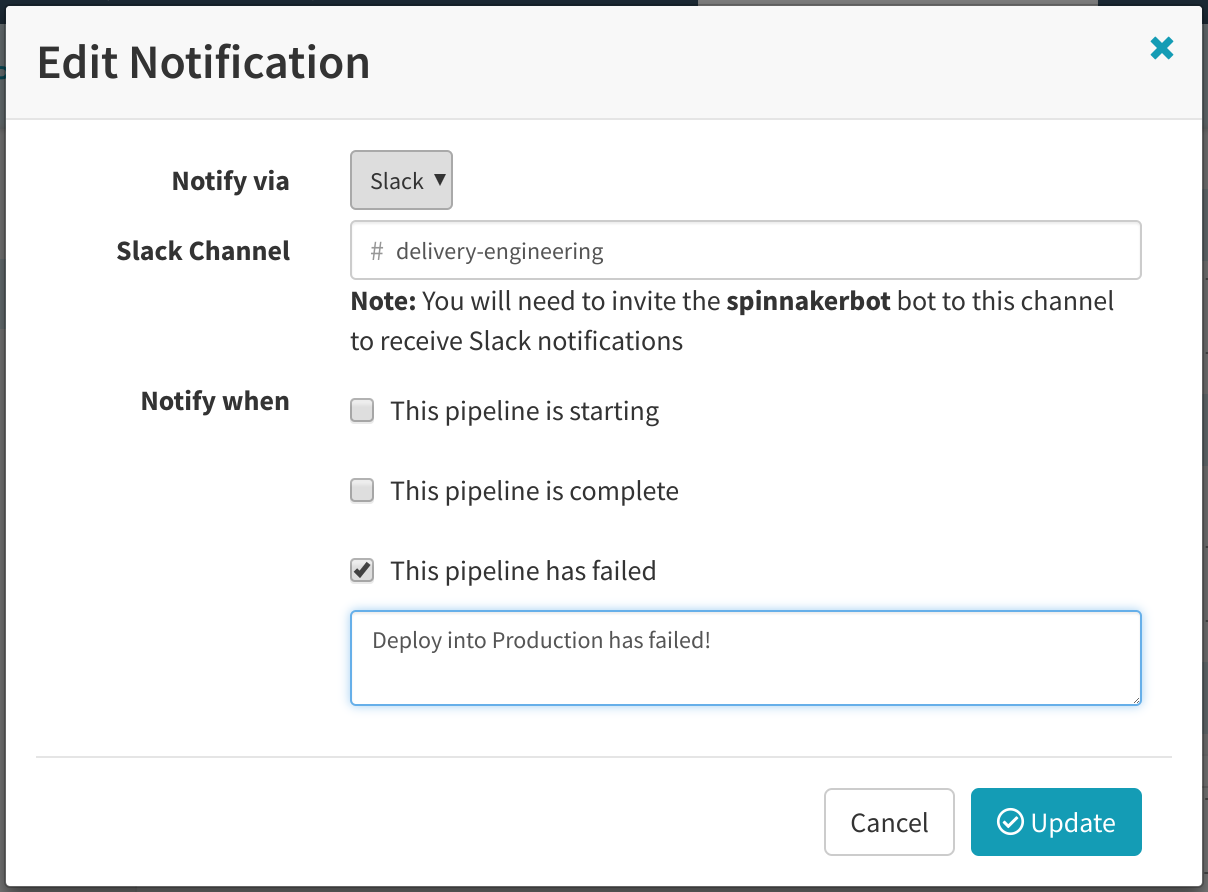
在进行自动部署时,需要通知团队有关部署的情况
\\让人们知道部署已成功进入生产环境,这对成功的运维来说至关重要。在出现问题时,需要知道发生了哪些变更以及这些变更是在什么时候发生的。因此,在进行自动部署时,需要通知团队,让他们密切关注服务的健康状况。在Netflix,我们使用Slack发送通知。在Spinnaker中,管道可以在部署完成时通知相应的Slack频道。
\\
自动化非典型部署,而不是进行一次性手动部署
\\每个工程师都为非典型情况编写过一次性脚本。而当这类“一次性”情况再次发生时,团队的其他成员并不知道写脚本的那个工程师在脚本里都干了什么,因为脚本本来是打算运行一次就丢掉的!很多人都遇到过这种情况。
\\管道是自动执行一系列步骤的有效手段,即使有些步骤并不会每天都执行。例如,一个用于紧急推送的管道,它使用参数作为控制执行的条件(比如跳过部署窗口)。
\\不要忘记定期测试非关键场景的非典型(和典型)部署管道!
\\使用先决条件验证预期状态
\\现如今,系统经常发生变化是常态。在Netflix,我们的数百个微服务在不断发生变化。做出无根据的假设(比如假设其他系统的状态)是很危险的。我们现在使用先决条件来确保在部署新代码或进行其他变更时假设仍然有效。这对于长时间执行的管道(可能是因为人工判断或部署窗口造成延迟)来说尤为重要。我们可以在发生潜在的破坏性操作之前使用先决条件来验证预期的状态。
\\结论
\\这篇文章总结了我们多年来在Netflix积累的各种技巧和最佳实践。我们的方法是尽可能围绕这些最佳实践构建工具。我们始终把提高服务可用性作为目标。在真正需要人工干预时,我们才会介入,否则就不插手。工程师的时间用在了那些可以提高可用性的任务上,而在不需要他们参与的情况下,他们可以专注其他事情。
\\英文原文:https://medium.com/@NetflixTechBlog/tips-for-high-availability-be0472f2599c
\\感谢张婵对本文的审校。

















 1150
1150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









