






 本文详细介绍了如何利用Pig将分析完成的数据存储到MySQL数据库中,包括配置数据库驱动、实现数据存储的具体步骤以及解决权限问题的方法。通过实例演示,展示了从读取文件数据、过滤条件、存储到数据库的全过程,最终验证数据正确写入数据库的效果。
本文详细介绍了如何利用Pig将分析完成的数据存储到MySQL数据库中,包括配置数据库驱动、实现数据存储的具体步骤以及解决权限问题的方法。通过实例演示,展示了从读取文件数据、过滤条件、存储到数据库的全过程,最终验证数据正确写入数据库的效果。

上篇介绍了如何把Pig的结果存储到Solr中,那么可能就会有朋友问了,为什么不存到数据库呢? 不支持还是? 其实只要我们愿意,我们可以存储它的结果集到任何地方,只需要重写我们自己的StoreFunc类即可。
关于如何将Pig分析完的结果存储到数据库,在pig的piggy贡献组织里,已经有了对应的UDF了,piggybank是非apache官方提供的工具函数,里面的大部分的UDF都是,其他公司或着个人在后来使用时贡献的,这些工具类,虽然没有正式划入pig的源码包里,但是pig每次发行的时候,都会以扩展库的形式附带,编译后会放在pig根目录下一个叫contrib的目录下,
piggybank的地址是
https://cwiki.apache.org/confluence/display/PIG/PiggyBank
,感兴趣的朋友们,可以看一看。
将pig分析完的结果存入到数据库,也是非常简单的,需要的条件有:
(1)piggybank.jar的jar包
(2)依赖数据库的对应的驱动jar
有一点需要注意下,在将结果存储到数据库之前,一定要确保有访问和写入数据库的权限,否则任务就会失败!
散仙在存储到远程的MySQL上,就是由于权限的问题,而写入失败了,具体的异常是这样描述的:
Java代码 


Access denied for user 'root'@'localhost'
Access denied for user 'root'@'localhost'
当出现上面异常的时候,就意味着权限写入有问题,我们使用以下的授权方法,来给目标机赋予权限:
(1)允许所有的机器ip访问
GRANT ALL PRIVILEGES ON *.* TO 'myuser'@'%' IDENTIFIED BY 'mypassword' WITH GRANT OPTION;
(2)允许指定的机器ip访问:
1. GRANT ALL PRIVILEGES ON *.* TO 'myuser'@'192.168.1.3' IDENTIFIED BY 'mypassword' WITH GRANT OPTION;
确定有权限之后,我们就可以造一份数据,测试是否可以将HDFS上的数据存储到数据库中,测试数据如下:
Java代码
1,2,3
1,2,4
2,2,4
3,4,2
8,2,4
1,2,3
1,2,4
2,2,4
3,4,2
8,2,4
提前在对应的MySQL上,建库建表建字段,看下散仙测试表的结构: 
最后,在来看下我们的pig脚本是如何定义和使用的:
Java代码
--注册数据库驱动包和piggybank的jar
register ./dependfiles/mysql-connector-java-5.1.23-bin.jar;
register ./dependfiles/piggybank.jar
--为了能使schemal和数据库对应起来,建议在这个地方给数据加上列名
a = load '/tmp/dongliang/g.txt' using PigStorage(',') as (id:int,name:chararray,count:int) ;
--过滤出id大于2的数据
a = filter a by id > 2;
--存储结果到数据库里
STORE a INTO '/tmp/dbtest' using org.apache.pig.piggybank.storage.DBStorage('com.mysql.jdbc.Driver', 'jdbc:mysql://192.168.146.63/user', 'root', 'pwd',
'INSERT into pig(id,name,count) values (?,?,?)');
~
--注册数据库驱动包和piggybank的jar
register ./dependfiles/mysql-connector-java-5.1.23-bin.jar;
register ./dependfiles/piggybank.jar
--为了能使schemal和数据库对应起来,建议在这个地方给数据加上列名
a = load '/tmp/dongliang/g.txt' using PigStorage(',') as (id:int,name:chararray,count:int) ;
--过滤出id大于2的数据
a = filter a by id > 2;
--存储结果到数据库里
STORE a INTO '/tmp/dbtest' using org.apache.pig.piggybank.storage.DBStorage('com.mysql.jdbc.Driver', 'jdbc:mysql://192.168.146.63/user', 'root', 'pwd',
'INSERT into pig(id,name,count) values (?,?,?)');
~
执行成功后,我们再去查看数据库发现已经将pig处理后的数据正确的写入到了数据库中: 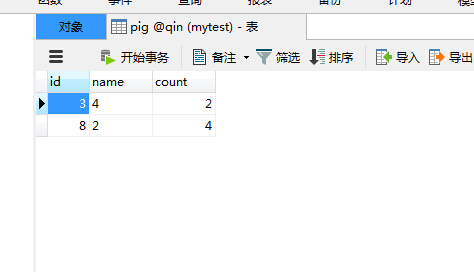
最后,附上DBStore类的源码:
Java代码
/*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.pig.piggybank.storage;
import org.joda.time.DateTime;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.OutputCommitter;
import org.apache.hadoop.mapreduce.OutputFormat;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.pig.StoreFunc;
import org.apache.pig.backend.executionengine.ExecException;
import org.apache.pig.data.DataByteArray;
import org.apache.pig.data.DataType;
import org.apache.pig.data.Tuple;
import java.io.IOException;
import java.sql.*;
public class DBStorage extends StoreFunc {
private final Log log = LogFactory.getLog(getClass());
private PreparedStatement ps;
private Connection con;
private String jdbcURL;
private String user;
private String pass;
private int batchSize;
private int count = 0;
private String insertQuery;
public DBStorage(String driver, String jdbcURL, String insertQuery) {
this(driver, jdbcURL, null, null, insertQuery, "100");
}
public DBStorage(String driver, String jdbcURL, String user, String pass,
String insertQuery) throws SQLException {
this(driver, jdbcURL, user, pass, insertQuery, "100");
}
public DBStorage(String driver, String jdbcURL, String user, String pass,
String insertQuery, String batchSize) throws RuntimeException {
log.debug("DBStorage(" + driver + "," + jdbcURL + "," + user + ",XXXX,"
+ insertQuery + ")");
try {
Class.forName(driver);
} catch (ClassNotFoundException e) {
log.error("can't load DB driver:" + driver, e);
throw new RuntimeException("Can't load DB Driver", e);
}
this.jdbcURL = jdbcURL;
this.user = user;
this.pass = pass;
this.insertQuery = insertQuery;
this.batchSize = Integer.parseInt(batchSize);
}
/**
* Write the tuple to Database directly here.
*/
public void putNext(Tuple tuple) throws IOException {
int sqlPos = 1;
try {
int size = tuple.size();
for (int i = 0; i < size; i++) {
try {
Object field = tuple.get(i);
switch (DataType.findType(field)) {
case DataType.NULL:
ps.setNull(sqlPos, java.sql.Types.VARCHAR);
sqlPos++;
break;
case DataType.BOOLEAN:
ps.setBoolean(sqlPos, (Boolean) field);
sqlPos++;
break;
case DataType.INTEGER:
ps.setInt(sqlPos, (Integer) field);
sqlPos++;
break;
case DataType.LONG:
ps.setLong(sqlPos, (Long) field);
sqlPos++;
break;
case DataType.FLOAT:
ps.setFloat(sqlPos, (Float) field);
sqlPos++;
break;
case DataType.DOUBLE:
ps.setDouble(sqlPos, (Double) field);
sqlPos++;
break;
case DataType.DATETIME:
ps.setDate(sqlPos, new Date(((DateTime) field).getMillis()));
sqlPos++;
break;
case DataType.BYTEARRAY:
byte[] b = ((DataByteArray) field).get();
ps.setBytes(sqlPos, b);
sqlPos++;
break;
case DataType.CHARARRAY:
ps.setString(sqlPos, (String) field);
sqlPos++;
break;
case DataType.BYTE:
ps.setByte(sqlPos, (Byte) field);
sqlPos++;
break;
case DataType.MAP:
case DataType.TUPLE:
case DataType.BAG:
throw new RuntimeException("Cannot store a non-flat tuple "
+ "using DbStorage");
default:
throw new RuntimeException("Unknown datatype "
+ DataType.findType(field));
}
} catch (ExecException ee) {
throw new RuntimeException(ee);
}
}
ps.addBatch();
count++;
if (count > batchSize) {
count = 0;
ps.executeBatch();
ps.clearBatch();
ps.clearParameters();
}
} catch (SQLException e) {
try {
log
.error("Unable to insert record:" + tuple.toDelimitedString("\t"),
e);
} catch (ExecException ee) {
// do nothing
}
if (e.getErrorCode() == 1366) {
// errors that come due to utf-8 character encoding
// ignore these kind of errors TODO: Temporary fix - need to find a
// better way of handling them in the argument statement itself
} else {
throw new RuntimeException("JDBC error", e);
}
}
}
class MyDBOutputFormat extends OutputFormat<NullWritable, NullWritable> {
@Override
public void checkOutputSpecs(JobContext context) throws IOException,
InterruptedException {
// IGNORE
}
@Override
public OutputCommitter getOutputCommitter(TaskAttemptContext context)
throws IOException, InterruptedException {
return new OutputCommitter() {
@Override
public void abortTask(TaskAttemptContext context) throws IOException {
try {
if (ps != null) {
ps.close();
}
if (con != null) {
con.rollback();
con.close();
}
} catch (SQLException sqe) {
throw new IOException(sqe);
}
}
@Override
public void commitTask(TaskAttemptContext context) throws IOException {
if (ps != null) {
try {
ps.executeBatch();
con.commit();
ps.close();
con.close();
ps = null;
con = null;
} catch (SQLException e) {
log.error("ps.close", e);
throw new IOException("JDBC Error", e);
}
}
}
@Override
public boolean needsTaskCommit(TaskAttemptContext context)
throws IOException {
return true;
}
@Override
public void cleanupJob(JobContext context) throws IOException {
// IGNORE
}
@Override
public void setupJob(JobContext context) throws IOException {
// IGNORE
}
@Override
public void setupTask(TaskAttemptContext context) throws IOException {
// IGNORE
}
};
}
@Override
public RecordWriter<NullWritable, NullWritable> getRecordWriter(
TaskAttemptContext context) throws IOException, InterruptedException {
// We don't use a record writer to write to database
return new RecordWriter<NullWritable, NullWritable>() {
@Override
public void close(TaskAttemptContext context) {
// Noop
}
@Override
public void write(NullWritable k, NullWritable v) {
// Noop
}
};
}
}
@SuppressWarnings("unchecked")
@Override
public OutputFormat getOutputFormat()
throws IOException {
return new MyDBOutputFormat();
}
/**
* Initialise the database connection and prepared statement here.
*/
@SuppressWarnings("unchecked")
@Override
public void prepareToWrite(RecordWriter writer)
throws IOException {
ps = null;
con = null;
if (insertQuery == null) {
throw new IOException("SQL Insert command not specified");
}
try {
if (user == null || pass == null) {
con = DriverManager.getConnection(jdbcURL);
} else {
con = DriverManager.getConnection(jdbcURL, user, pass);
}
con.setAutoCommit(false);
ps = con.prepareStatement(insertQuery);
} catch (SQLException e) {
log.error("Unable to connect to JDBC @" + jdbcURL);
throw new IOException("JDBC Error", e);
}
count = 0;
}
@Override
public void setStoreLocation(String location, Job job) throws IOException {
// IGNORE since we are writing records to DB.
}
}
















 1007
1007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









