






 本文详细探讨了在MySQL中创建联合索引时的最左前缀原则,通过实例演示了不同字段组合查询时索引的使用情况,揭示了哪些查询能有效利用索引,帮助读者理解联合索引的工作原理。
本文详细探讨了在MySQL中创建联合索引时的最左前缀原则,通过实例演示了不同字段组合查询时索引的使用情况,揭示了哪些查询能有效利用索引,帮助读者理解联合索引的工作原理。
情况描述:在MySQL的user表中,对a,b,c三个字段建立联合索引,那么查询时使用其中的2个作为查询条件,是否还会走索引?
根据查询字段的位置不同来决定,如查询a, a,b a,b,c a,c 都可以走索引的,其他条件的查询不能走索引。
组合索引 有“最左前缀”原则。就是只从最左面的开始组合,并不是所有只要含有这三列存在的字段的查询都会用到该组合索引。
验证过程如下所示:
首先,在SQLyog中建立一个user表,如下图所示;
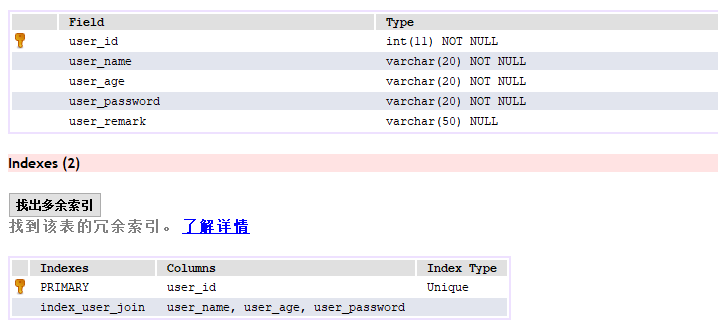
对中间3个字段(user_name,user_age,user_password)进行联合索引 index_user_join
查询情况如下所示:
1.同时查询这3个字段作为条件的SQL,索引情况及SQL语句如下所示:
SELECT *FROM t_user WHERE user_name='zs' AND user_age=20 AND user_password='123456';
其使用索引情况如下所示:

从执行结果上可以看到是从走索引进行查询的
2.使用user_age和user_password作为查询条件进行查询,索引及SQL语句如下所示:

3.使用user_name和user_password作为查询条件进行查询,索引及SQL语句如下所示:

4.使用user_name作为查询条件进行查询,索引及SQL语句如下所示:

5.使用user_age作为查询条件进行查询,索引及SQL语句如下所示:

6.使用user_password作为查询条件进行查询,索引及SQL语句如下所示:

以上是针对普通的字段建立联合索引的测试情况及截图,欢迎小伙伴们来补充~

















 1601
1601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









