






 本文介绍了一种改进的AB实验方案,解决了多层AB实验时分桶复杂及数据评估难的问题。通过对唯一标识添加实验ID进行md5计算实现各层实验间的正交分流,确保了实验的独立性;同时引入链路ID机制简化数据评估流程,提高实验效率。
本文介绍了一种改进的AB实验方案,解决了多层AB实验时分桶复杂及数据评估难的问题。通过对唯一标识添加实验ID进行md5计算实现各层实验间的正交分流,确保了实验的独立性;同时引入链路ID机制简化数据评估流程,提高实验效率。
概述
传统AB核心内容主要分为两块:分流控制和数据评估。
分流控制比较通过的作法是对某一唯一标识进行hash,然后进行分桶来完成,其存在的问题是如果一个功能下会有多层AB时,那么如果集中做分桶则会比较复杂。假如有3层,然后每层2个实验就要分8个桶,层数、分桶越多,这个集中分桶数会更大,不便于管理。另外还要协调多层之间各自可以使用哪些分桶来进行AB实验,相对上下游沟通成本较大。
数据评估的核心在于如何进行埋点并采集到数据,数据主要包括曝光和点击两大类。目前大多数AB方案是将分桶等信息通过层层上传的方式,最终透到展现端,然后在展现端触发相关行为时记录下AB信息。这种方式存在的问题是层层上传AB信息这个需求上下游全链路所有接口协同配合才能完成,离展现端越远,协同成本越大;另外如果多层AB实验,那么如何隔离存放多层各自所需的AB信息也会存在很大的问题。
那么如何解决上述两个问题呢?
解决方案
分流控制
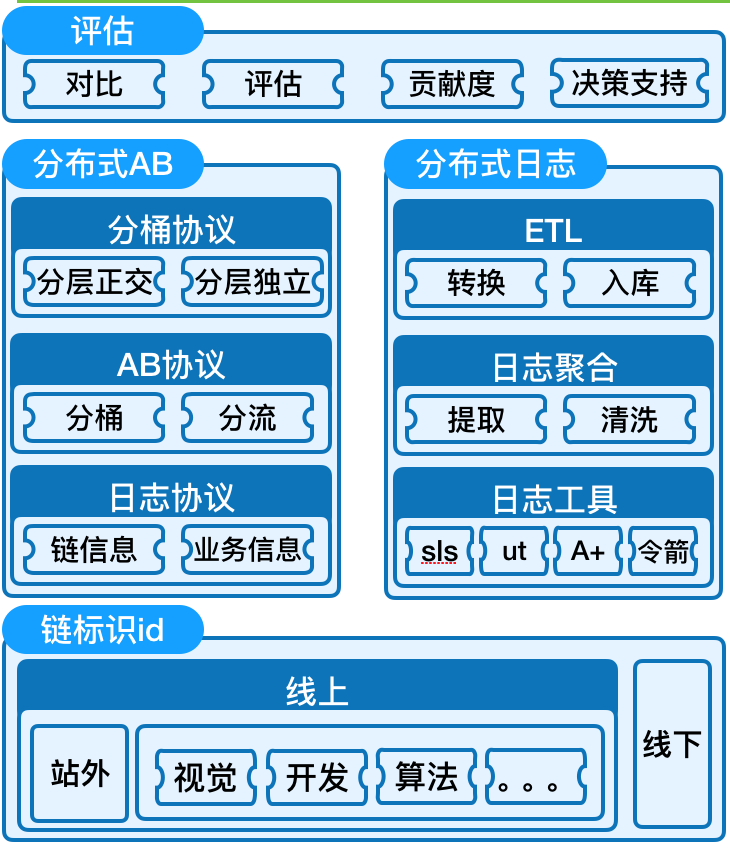
针对多层分流的情况,使各层能够在互相隔离的情况下进行AB实验,其实业界已经有现成的方案,主要是基于google的《Overlapping Experiment Infrastructure More, Better, Faster Experimentation》这篇论文。原来计算分桶算法一般是使用一个唯一标识的hash值来进行分桶:
bucket_id=hash(unique_id)%100
为了使多层实验间互不干扰,相互正交,先通过在唯一标识后加一个该层实验的唯一标识计算一个md5值,然后计算hash值来进行分桶。利用md5的特征,使各层之间的分流逻辑相互独立。
bucket_id=hash(md5(unique_id,layer_id))%100
这样如果有一个集中的AB平台,则可以使用每个实验的id来代替layer_id,这样就可以得到一个各层甚至各AB实验完全正交的分桶能力。
数据评估
针对数据评估,如前所述主要要解决的如何进行数据埋点。层层上传数据到展现端的方案中间协调成本太大,并且各自记录数据的隔离性不好,有可能会生产冲突。
针对这个问题的解决方法是构建一个链路id,全链路中的各个节点都能取到,然后展现端将记录曝光点击数据时将该链路id加入到这些日志信息中,然后各链路节点、各层实验单独在服务端记录日志,包括链路id、AB信息以及其它数据评估所需的内容。
然后展现端和后端通过链路id做关联,就可以将AB实验与展现端业务数据效果进行关联,得到最终的效果评估。目前可以使用鹰眼的traceId来做为链路id使用。
这样打点只要前后端衔接环节会有一个协调成本,将traceid埋入业务日志中,而后下游链路各节点想做AB都可以独立进行,只要使用的layer_id互不冲突即可。
架构方案

















 2194
2194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









