






 本文介绍了MySQL Schema设计中应避免的陷阱,如过多的列、关联和枚举,以及混用范式和反范式的策略。讨论了缓存表、汇总表的使用,计数器的高效管理,以及优化ALTER TABLE速度和快速创建MYISAM索引的方法。
本文介绍了MySQL Schema设计中应避免的陷阱,如过多的列、关联和枚举,以及混用范式和反范式的策略。讨论了缓存表、汇总表的使用,计数器的高效管理,以及优化ALTER TABLE速度和快速创建MYISAM索引的方法。
一、设计中的陷阱
1、太多的列
MySQL的存储引擎API工作时需要在服务器层和存储引擎层之间通过行缓冲格式拷贝数据,然后在服务器层将缓冲内容解码为各个列。这是一个代价很高的操作,转换的代价依赖于列的数量,列太多的话,转换代价就会很高。
2、太多的关联
一个粗略的经验法则,如果希望查询和并发行好,单个查询不要超过10个表的关联。
3、过度的枚举
修改一个枚举列的值时,需要alter table的阻塞操作,代价很高。
4、避免不可能的值CREATE TABLE date_test(
dt DATETIME NOT NULL DEFAULT '0000-00-00 00:00:00');
二、混用范式和反范式
最常见的反范式数据的方法是复制或者缓存,在不同的表中存储相同的特定列。缓存衍生值,比方说某个帖子的评论总数。混用的目的是在关联查询和增删改操作上做一个性能的折中考虑。
三、缓存表和汇总表
缓存表来存储那些某个主表上的一部分列数据,用来提供高效的查询操作。
汇总表保存的是使用GROUP BY语句聚合数据的表。
建立这些表是为了减少在主表上因为某些查询需要加很多特殊的索引。
当重建汇总表或缓存表时,通常需要保证数据在操作时仍然可用。这就需要通过使用“影子表”。drop table if exists my_summary_new,my_summary_old;
create table my_summary_new like my_summay;
#导入数据
rename table my_summary to my_summary_old,my_summary_new to my_summary;
四、计数器
如果在表中保存计数器,在更新计数器时可能碰到并发问题,所以创建一张独立的表存储计数器通常是个好主意。
假设有一个计数器表,只有一行数据,记录网站的点击次数
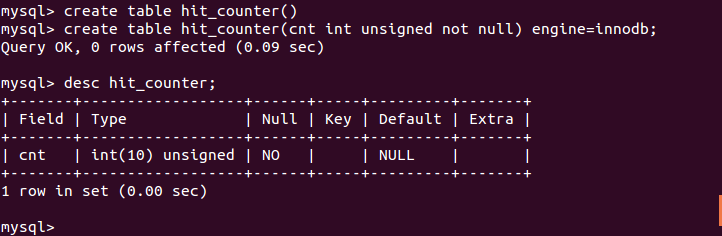
网站的每次点击都会导致对计数器更新update hit_counter set cnt = cnt + 1;
问题在于,对于任何想要更新这一行的事务来说,这条记录会有全局的写锁,这会使事务只能串行执行。要获得更高的并发行,可以将计数器保存在多行中,每次随机选择一个行更新。create table hit_counter(
id tinyint unsigned not null primary key,
cnt int unsigned not null
) engine = innodb;
然后预先增加100行数据,当更新的时候随机选择一条记录来更新update hit_counter set cnt=cnt+1 where id= rand()*100;
这样的统计结果就变成了select sum(cnt) from hit_counter;
一个常见的需求是每隔一段时间开始一个新的计数器,这个时候需要简单的修改一下表的设计
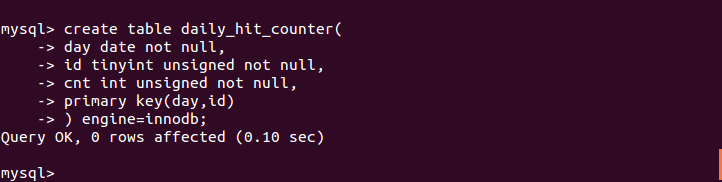
在这个场景中,不需要预先生成行,而用on duplicate key update 代替insert into daily_hit_counter(day,id,cnt) values(current_date(),rand() * 100,1) on duplicate key update cnt = cnt + 1;
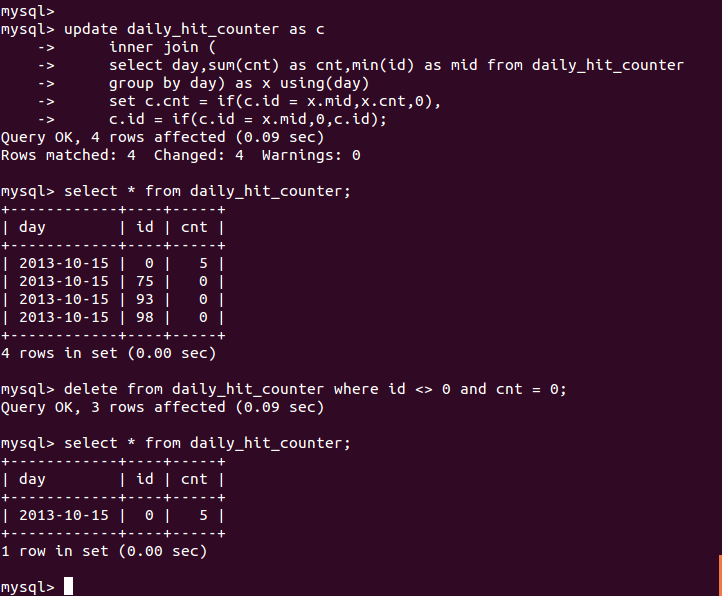
如果希望减少表的行数,以免表太大,可以写一个周期执行的任务,合并所有结果到一行,并删除其他所有的行。
五、加快ALTER TABLE速度
alter table 对大表来说是个问题。MySQL执行大部分修改表结果操作的方法是用新的结果创建一个空表,从旧表查出所有数据插入新表,然后删除旧表,这样的操作花费时间很长。
为了防止阻塞,有2个技巧
1、在一台不提供服务的机器上执行alter table,然后和提供服务的主库进行切换
2、影子拷贝
但并不是所有的alter table操作会引起表的重建,比方说修改或删除一个列的默认值。
一个很慢的方法是alter table film modify column sss tinyint(3) not null default 5;
show status显示表重建了。
列的默认值存储在.frm文件中,所以只需要修改.frm文件,但是modify column都将导致表重建。
另一种快速方法,只修改.frm文件,所以很快。alter table film alter column sss set default 5;
六、快速创建MYISAM索引
为了高效的载入数据到myisam表中,可以先禁用索引,载入数据,然后重新启用索引。
alter table test disable keys;
#load data
alter table test enable keys;
但是只针对非唯一索引,唯一索引还是会检测。

















 1532
1532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









