



插入语句insert
insert 数据表名(字段名...)
values(字段值);
例 :
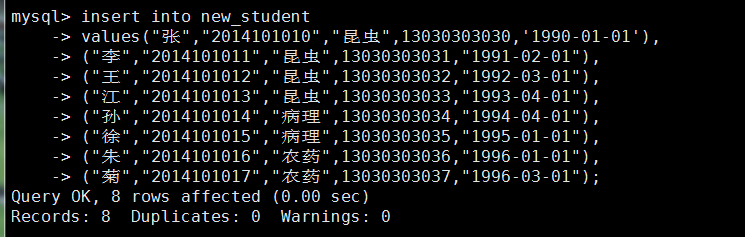
insert into new_student values("张","2014101010","昆虫",13030303030,'1990-01-01');
insert into new_student values("李","2014101011","昆虫",13030303031,"1991-02-01");
insert into new_student values("王","2014101012","昆虫",13030303032,"1992-03-01");
insert into new_student values("江","2014101013","昆虫",13030303033,"1993-04-01");
insert into new_student values("孙","2014101014","病理",13030303034,"1994-04-01");
insert into new_student values("徐","2014101015","病理",13030303035,"1995-01-01");
insert into new_student values("朱","2014101016","农药",13030303036,"1996-01-01");
insert into new_student values("菊","2014101017","农药",13030303037,"1996-03-01");
同时插入多条语句:
mysql> insert into new_student values("邬家栋","2014101780","昆虫",13580303030,'1850-01-01'),
->("蒋睿","2014101058","昆虫",13030303089,"1991-07-01");
注意:逗号分隔,语句结束时是分号。
insert ... set 语句通过等号赋值
语法格式:
inert into 数据表名
set 字段名=字段值,
...;
例:
mysql> insert into new_student
-> set new_name="徐晴玉",
-> sid="2015010111",
-> major="昆虫",
-> tel=15468972013,
-> birthday="1990-05-23";
简单select查询
语法格式:
select 字段名 from 数据表名
where 条件表达式
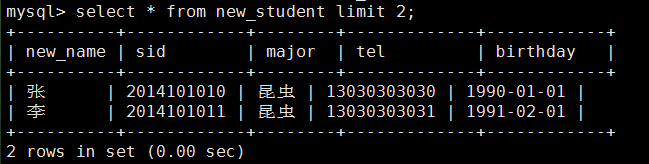
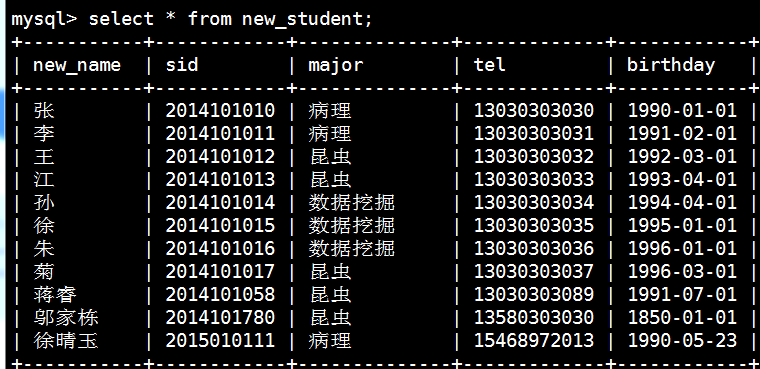
查看某个表的所有数据:select * from new_student;
查看某个表的数据的前几行:select * from new_student limit 3;
筛选出符合条件的的人的名字:select new_name from new_student where birthday >= '1992-01-01'; #生日大于1991.01.01

筛选出符合条件的所有人信息:select * from new_student where birthday >= '1992-01-01'; #星号代替所有字段
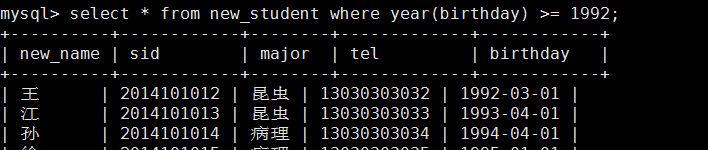
筛选出符合条件的所有人信息:select * from new_student where year(birthday) >= 1993; #year是内置函数。找出大于1993年的人所有信息
带结果排序的select查询
语法格式:
select 字段名 from 数据表名
where 条件表达式
order by 字段名 [asc][desc];
例:
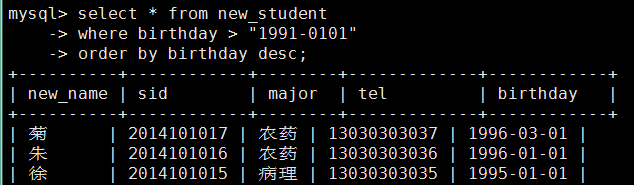
mysql> select new_name,birthday from new_student
-> where birthday > '1990-01-01'
-> order by birthday desc; #desc降序排列
限定结果条数的select语句查询
语法格式:
select 字段名 from 数据表名
where 条件表达式
limit row_count;
例:
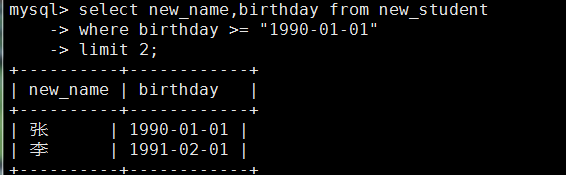
mysql> select new_name,birthday from new_student
-> where birthday >= '1990-01-01'
-> limit 3;
#先对结果进行排序,再做出选择
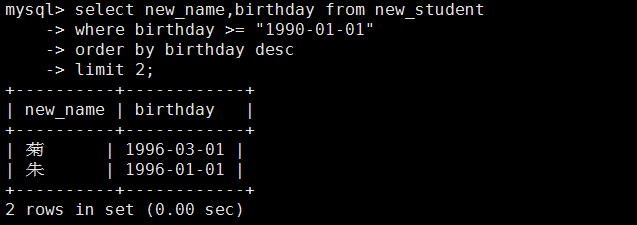
mysql> select new_name,birthday from new_student
-> where birthday >= '1990-01-01'
-> order by birthday desc
-> limit 3;
更新语句update
语法格式:
update 数据表名
set 字段名=字段值,...
[where 查询条件]
例
mysql> update new_student
-> set majot="昆虫"; #将所有的专业都改成了昆虫
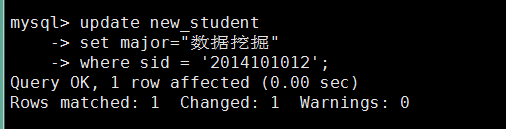
mysql> update new_student
-> set major="病理" 将major修改为病理,注意major后面没有逗号
-> where sid='2014101011'; #where是定位修改记录
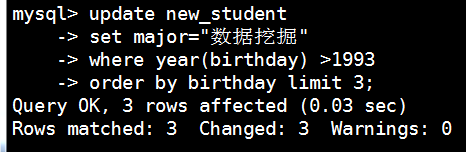
mysql> update new_student
-> set major="数据挖掘" #修改major为数据挖掘
-> where year(birthday) >1993 #查询生日大于1993年的
-> order by birthday limit 3; #然后按生日排序 依次修改3个
删除语句delete
语法格式:
delete from 数据表名
[where 查询条件] #若无where语句则删除该表所有记录
例:
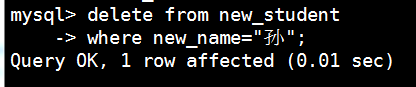
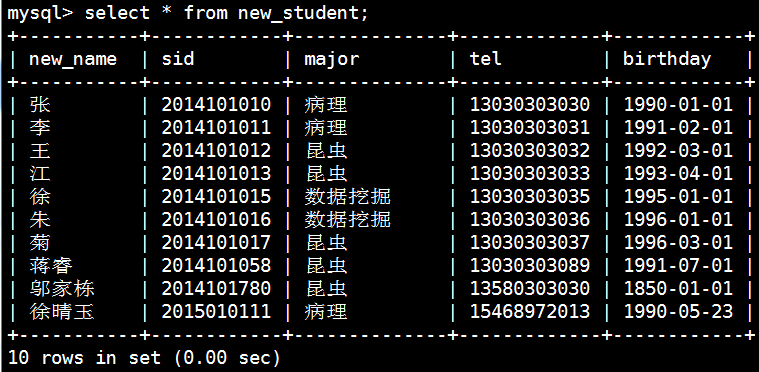
mysql> delete from new_student
-> where new_name="孙";
新增指标
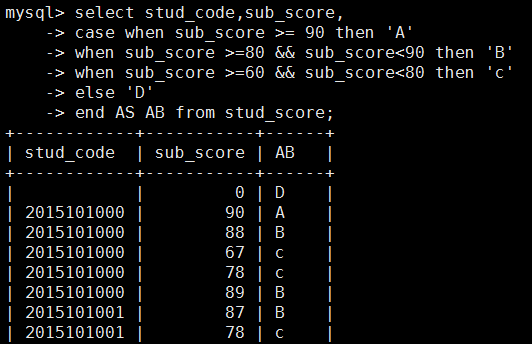
mysql> select stud_code,sub_score,
-> case when sub_score >= 90 then 'A'
-> when sub_score >=80 && sub_score<90 then 'B'
-> when sub_score >=60 && sub_score<80 then 'c'
-> else 'D'
-> end AS AB from stud_score;
将新指标保存到一个新表中
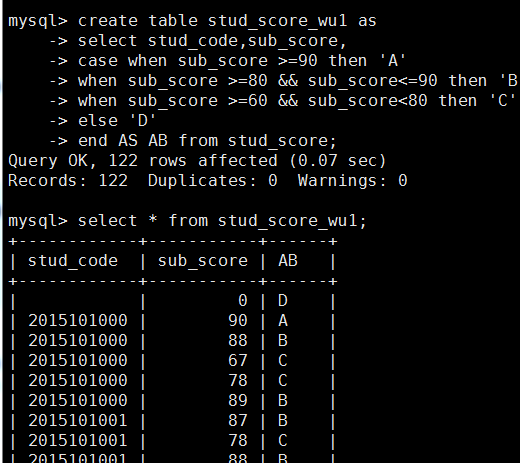
mysql> create table stud_score_wu1 as
-> select stud_code,sub_score,
-> case when sub_score >=90 then 'A'
-> when sub_score >=80 && sub_score<=90 then 'B'
-> when sub_score >=60 && sub_score<80 then 'C'
-> else 'D'
-> end AS AB from stud_score;
实例
1创建一个含自增量为主键的表;往表中插入记录、修改、删除记录。
1创建一个含自增量为主键的表;往表中插入记录、修改、删除记录。
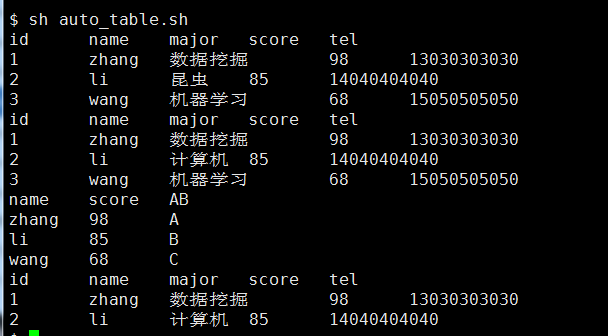
1 #!/bin/bash 2 #文件名称;auto_table.sh 3 #文件功能:创建一含自增量为主键的表,并进行增删改操作 4 #创建时间:2016-07-30 5 #创建作者:邬家栋 6 7 mysql -u feigu_mysql -pfeigu2016 testdb << EOF 8 drop table if exists wu_auto_table; 9 create table wu_auto_table( 10 id int unsigned not null auto_increment, 11 name varchar(20) not null comment "姓名", 12 major char(50) not null, 13 score int(10) not null, 14 tel varchar(11) null, 15 primary key(id) 16 ); 17 18 /*插入数据*/ 19 insert into wu_auto_table(name,major,score,tel) values("zhang","数据挖掘",98,13030303030),("li","昆虫",85,14040404040),("wang","机器学习",68,15050505050); 20 select * from wu_auto_table; 21 22 /*更新数据*/ 23 update wu_auto_table set major="计算机" where id=2; 24 select * from wu_auto_table; 25 26 /*新增指标 */ 27 drop table if exists new_table; 28 create table new_table as 29 select name,score, 30 case when score>=90 then "A" 31 when score >=80 && score<90 then "B" 32 else "C" 33 end AS AB from wu_auto_table; 34 select * from new_table; 35 36 /*删除数据*/ 37 delete from wu_auto_table where id =3; 38 select * from wu_auto_table; 39 EOF
2 修改stud_score表中 stud_code=2015101000的高等代数成绩,并将结果保存到一个文件中。
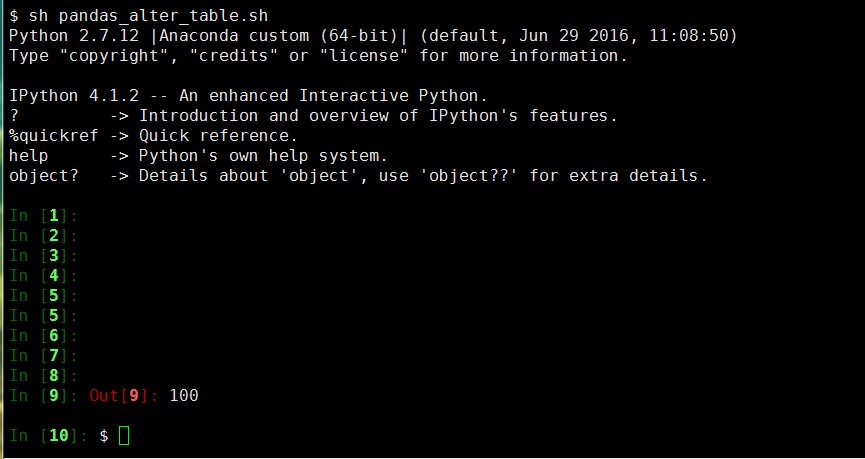
1 #!/bin/bash 2 #文件名称;pandas_alter_table.sh 3 #文件功能:修改stud_score表中某行成绩并保存结果到文件 4 #创建时间:2016-07-30 5 #创建作者:邬家栋 6 7 ipython << EOF 8 import numpy as np 9 import pandas as pd 10 from pandas import DataFrame 11 import MySQLdb 12 13 conn=MySQLdb.connect(host='localhost',port=21124,user='feigu_mysql',passwd='feigu2016',db='testdb',charset='utf8',unix_socket='/var/run/mysqld/mysqld.sock') 14 data=pd.read_sql('select * from stud_score',conn) 15 df1=DataFrame(data) 16 df2=df1.ix[2015101000,['sub_score']]=100 17 df2 18 quit 19 EOF
问题:做到这里不会做了修改之后不知奥怎么保存。最后几步有问题。

















 1525
1525

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









