




环境说明
集群中包括4个节点,1个Master节点,3个Slave节点.都运行在CentOS虚拟机下面。4个节点位于同一个局域网,相互之间能够PING通。其次请确保安装了JDK.
下载安装包
http://hadoop.apache.org/#Download+Hadoop
首先从Apache官方网站上下载最新的Hadoop压缩包。我此处使用的是2.2.0

修改主机名称

通过hostname命令可以查看当前主机名,修改/etc/sysconfig/network配置文件可以修改主机名称。
配置hosts文件
在进行Hadoop集群配置中,需要在"/etc/hosts"文件中添加集群中所有机器的IP与主机名,这样Master与所有的Slave机器之间不仅可以通过IP进行通信,而且还可以通过主机名进行通信。所以在所有的机器上的"/etc/hosts"文件末尾中都要添加如下内容:

配置完成后可以通过Master节点去ping Slave节点

Hadoop用户和组
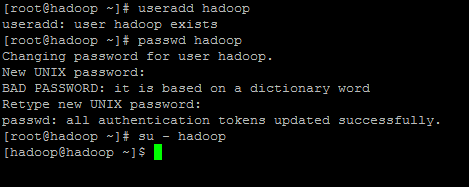
安装Hadoop需要特定的用户和权限,所以需要添加Hadoop用户。
1.useradd hadoop
2.passwd hadoop
配置SSH无密码协议
使用hadoop用户权限进配置。
su - hadoop
1.创建 .ssh文件并赋予权限。
2.ssh-keygen -t rsa 生成无密码密钥对。 一共会有3个询问,直接回车。
3.生成的公钥添加到authorized_keys文件中。
4.修改authorized_keys文件的权限。
测试:
root 权限重启ssh
service sshd restart
su - hadoop
ssh Hadoop.Master测试成功后需要在每个结点中配置其它结点的公钥。这样各个结点都能通过ssh无密码连接。所以保证每个节点的authorized_keys文件中包含了至少4个公钥。
安装Hadoop
首先用root登录Hadoop.Master, 解压缩hadoop压缩包。
tar -zxvf hadoop-2..2.0.tar.gz //解压缩
mv hadoop-2.2.0 hadoop //重命名
chown –R hadoop:hadoop hadoop //修改文件夹权限
cp -r hadoop /usr/ //移动到/usr目录下面。把Hadoop的安装路径添加到"/etc/profile"中,修改"/etc/profile"文件(配置java环境变量的文件),将以下语句添加到末尾,并使其有效:
export HADOOP_HOME=/usr/hadoop
export PATH=$PATH:$HADOOP_HOME/bin 在"/usr/hadoop"创建"tmp"文件夹
mkdir /usr/hadoop/tmp配置Hadoop
hadoop-env.sh(/usr/hadoop/etc/hadoop/)
在文件的末尾添加下面内容。
export JAVA_HOME=/usr/java/jdk1.6.0_25修改Hadoop核心配置文件core-site.xml,这里配置的是HDFS的地址和端口号。
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/tmp</value>
(备注:请先在 /usr/hadoop 目录下建立 tmp 文件夹)
<description>A base for other temporary directories.</description>
</property>
<!-- file system properties -->
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.1.1:9000</value>// Hadoop.Master的IP
</property>
</configuration> hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
(备注:replication 是数据副本数量,默认为3,salve少于3台就会报错)
</property>
<configuration>配置slaves文件
[root@Hadoop hadoop]# cat slaves
Hadoop.Slave1
Hadoop.Slave2
Hadoop.Slave3
[root@Hadoop hadoop]#到止前为止Master节点已经配置完了,需要以此种方式在所有结点上进行同样的配置。 你也可以把Master节点的Hadoop文件夹复制到所有的Slave节点下面。
关闭所有节点上的防火墙
service iptables stop启动Hadoop
格式化HDFS文件系统(请确保所有节点hadoop文件夹下面的权限都是hadoop)
su - hadoop
hadoop namenode -format在启动前关闭集群中所有机器的防火墙,不然会出现datanode开后又自动关闭。
启动namenode:
hadoop namenode启动datanode:
hadoop datanodehadoop命令的使用:
Usage: hadoop [--config confdir] COMMAND
这里COMMAND为下列其中一个:
namenode -format 格式化DFS文件系统
secondarynamenode 运行DFS的第二个namenode
namenode 运行DFS的namenode
datanode 运行一个DFS的datanode
dfsadmin 运行一个DFS的admin 客户端
fsck 运行一个DFS文件系统的检查工具
fs 运行一个普通的文件系统用户客户端
balancer 运行一个集群负载均衡工具
jobtracker 运行MapReduce的jobTracker节点
pipes 运行一个Pipes作业
tasktracker 运行一个MapReduce的taskTracker节点
job 处理MapReduce作业
version 打印版本
jar <jar> 运行一个jar文件
















 1784
1784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









