



 本文分享了处理IEEE oui.txt文件的经验,详细介绍了如何通过Python读取并清洗数据,统计苹果、华为等五家厂商的MAC地址占比。解决了编码问题,并展示了成功读取和整理数据的方法。
本文分享了处理IEEE oui.txt文件的经验,详细介绍了如何通过Python读取并清洗数据,统计苹果、华为等五家厂商的MAC地址占比。解决了编码问题,并展示了成功读取和整理数据的方法。
问题背景:下载了2018 IEEE 最新的 oui.txt 文件。里面包含了 设备 MAC 地址的前六位对应的厂商。要做的工作是,将海量设备的 MAC 地址与 oui.txt 文件的信息比对,统计出 苹果,华为,小米,OPPO,VIVO 这5家厂商的占比情况。oui.txt 文档里面的内容如下图所示。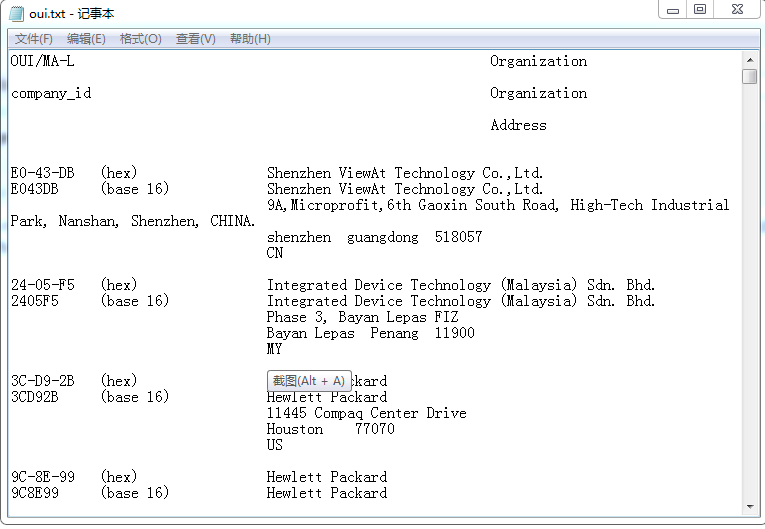
oui.txt 文件中有很多冗余信息。现在只关心前 6 位 mac 地址和五个厂商的对应关系。所以,对 oui.txt 里的数据清洗一下。
处理 oui.txt 出现的问题:
1.按照下面的写法,会报错
1 with open('data/oui.txt') as f: 2 for line in f.readlines(): 3 if('Apple' in line and '-' not in line): 4 print(line)
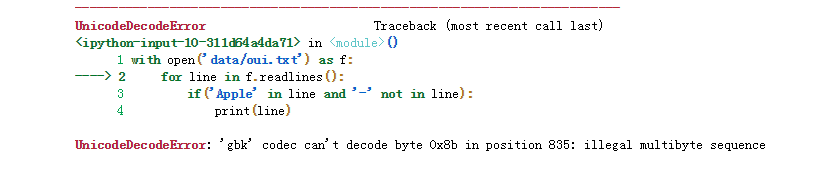
看来是编码问题,搜索了别人相关问题的回答,然后尝试方法2:
1 with open('data/oui.txt', encoding='gb18030') as f: 2 for line in f.readlines(): 3 if('Apple,' in line and '-' not in line): 4 print(line)
结果依旧出错。
再次尝试下面的的代码:
1 with open('data/oui.txt', encoding='gb18030', errors='ignore') as f: 2 for line in f.readlines(): 3 if('Apple,' in line and '-' not in line): 4 print(line)
就成功了。但是不太理解这个 error=‘ignore’ 会不会让我需要的信息漏读。
聪明的大虎给我提供了一个思路:可以用 utf-8
所以改成下面的样子:
1 with open('data/oui.txt', encoding='utf-8') as f: 2 for line in f.readlines(): 3 if('Apple,' in line and '-' not in line): 4 print(line)
这次成功,完全读取出来了,整理出的格式如下:IEEE分配给苹果的前六位mac地址太多,这里只展示一部分。
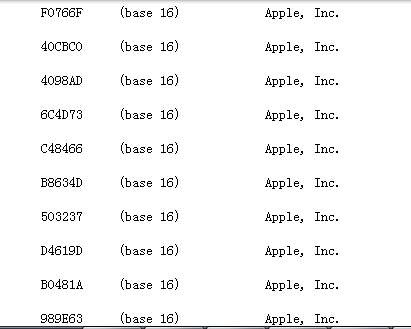
果然,看书敲代码学习是一回事,自己做东西出来是另外一回事

















 1954
1954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









