






 本文深入探讨了单机、集群及分布式系统的基本概念与特性,对比了各自的优势与局限,尤其强调了分布式系统如何通过微服务架构解决业务模块间的耦合问题,实现系统扩展与资源高效利用。
本文深入探讨了单机、集群及分布式系统的基本概念与特性,对比了各自的优势与局限,尤其强调了分布式系统如何通过微服务架构解决业务模块间的耦合问题,实现系统扩展与资源高效利用。
一、单机
单机就是所有的业务全部写在一个项目中,部署服务到一台服务器上,所有的请求业务都由这台服务器处理。显然,当业务增长到一定程度的时候,服务器的硬件会无法满足业务需求。自然而然地想到一个程序不行就部署多个喽,
这就是集群。
二、 集群
集群就是单机的多实例,在多个服务器上部署多个服务,每个服务就是一个节点,部署N个节点,处理业务的能力就提升 N倍(大约),这些节点的集合就叫做集群。
负载均衡:协调集群里的每个节点均衡地接受业务请求。通俗的讲就是服务A和服务B相同时间段内处理的同类业务请求数量是相似的
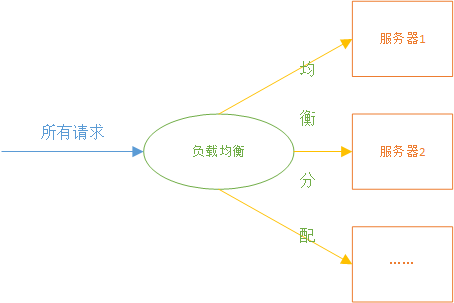
集群的特点:
扩展性好:集群只是单机的多个复制,没有改变单机的原有的代码结构,每次部署新节点只需要复制部署即可。
单个节点业务耦合度高、资源浪费:节点是多个业务处理集合(耦合高),每个具体业务的访问量可能差异很大,比如JD上账户管理模块的访问量肯定低于订单模块,
然而账户管理模块和订单模块的部署数量是一样的(因为每个节点里都有这两个模块),相对订单模块来说,部署同样多的账户管理模块就是浪费。
那就把单机节点不同的业务处理模块拆开喽,这就是分布式了
三、分布式(微服务)
分布式结构就是将一个完整的系统,按照业务功能,拆分成一个个独立的子系统,在分布式结构中,每个子系统就被称为“服务”。这些子系统能够独立运行在web容器中,它们之间通过RPC方式通信。
举个例子,假设需要开发一个在线商城。按照微服务的思想,我们需要按照功能模块拆分成多个独立的服务,如:用户服务、产品服务、订单服务、后台管理服务、数据分析服务等等。
这一个个服务都是一个个独立的项目,可以独立运行。如果服务之间有依赖关系,那么通过RPC方式调用。
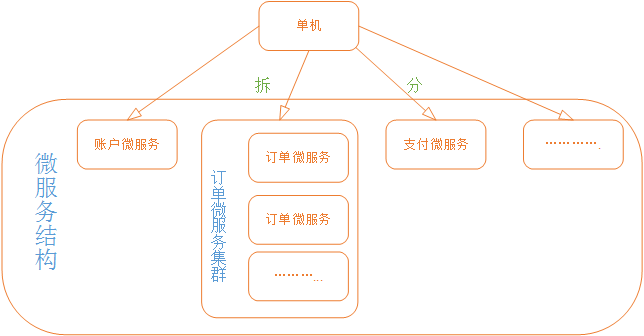
优点:
- 系统之间的耦合度大大降低,可以独立开发、独立部署、独立测试,系统与系统之间的边界非常明确,排错也变得相当容易,开发效率大大提升。
- 系统之间的耦合度降低,从而系统更易于扩展。我们可以针对性地扩展某些服务,就是对子系统集群。例如双十一时,订单子系统、支付子系统需要集群,账户管理子系统不需要集群。
- 服务的复用性更高。比如,当我们将用户系统作为单独的服务后,该公司所有的产品都可以使用该系统作为用户系统,无需重复开发。
参考链接:https://www.zhihu.com/question/20004877/answer/282033178

















 518
518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









