



 文章探讨了核心交换机端口出现大量丢包的原因,通过对端口状态及硬件参数的分析,揭示了overrun现象及其解决方案。最终确定更换硬件以解决性能瓶颈。
文章探讨了核心交换机端口出现大量丢包的原因,通过对端口状态及硬件参数的分析,揭示了overrun现象及其解决方案。最终确定更换硬件以解决性能瓶颈。
最近发现核心交换机有几个下联二层交换机的端口出现了很多丢包,从监控平台上显示如下:

显示为7609的receive discards,登陆上交换机查看端口如下:
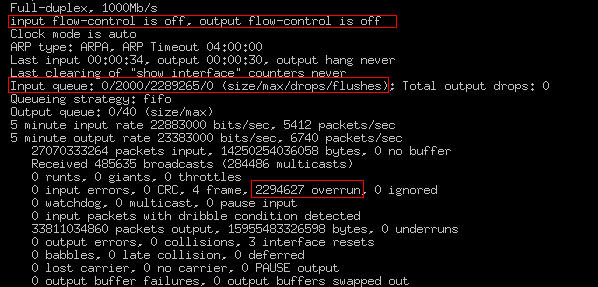
从上图中看到有很多数据包overrun(2294627),说明此端口的buffer已经耗尽,其将此buffer里的数据送往PFC的速度慢于此端口的接收数据报的速度,因此这些数据报就会丢弃,如上图Input queue有2289265 drops。overrun的官方解释如下:
Q. What are overruns on a serial interface?
A. Overruns appear in the output of the show interface Serial 0 command when the serial receiver hardware is unable to hand received data to a hardware buffer because the input rate exceeds the receiver's ability to handle the data.This occurs due to a limitation of the hardware. Overruns occur when the internal First In, First Out (FIFO) buffer of the chip is full, but is still tries to handle incoming traffic. The serial controller chip has limited internal FIFO.
而同时由上图可以看出此端口没有启用flow-control特性,flow-control的官方解释如下:


因此启用flow-control特性可以避免overrun的现象。但是从根本上来考虑此端口为GE端口速率为1000Mbps,且为full-duplex。而且当时此端口的input速率为22.8Mbps,远没有达到GE的上限。而从硬件架构来看,也远没有达到瓶颈。下为硬件参数显示信息:


查看了一下此板卡WS-X6548-GE-TX的结构图,表示每连续8个GE端口共享1G,而且此8GE端口共享16KB的RX BUFFER和1M的TX/RX BUFFER。所以从结构上来看,应该没有达到性能瓶颈的。


查看了一下此板卡WS-X6548-GE-TX的结构图,表示每连续8个GE端口共享1G,而且此8GE端口共享16KB的RX BUFFER和1M的TX/RX BUFFER。所以从结构上来看,应该没有达到性能瓶颈的。
补充:
本周通过与cisco case中心交涉,提交几个show命令显示结果给case中心,然后在case中心的协助下:完成以下2种测试:
1,disable head of line blocking which will utilize the interface buffers instead of the
shared buffers. This will result in only the single over utilized port having drops。查看了一下cisco网站,意思就是说启用head of line blocking使得此8个一组端口的每个端口都启用自己的32kb buffer,而不使用共享的1Mb buffer,这样就能看出到底是哪个端口overrun比较多。详见 [url]http://www.cisco.com/en/US/products/hw/switches/ps700/products_tech_note09186a00801751d7.shtml[/url]
配置命令如下:
6500(config)#service internal //此命令表示可以启用内部命令,注意内部命令TAB或者?都无效,直接敲入就是了。
6500(config)#interface gigabit 1/1
6500(config-if)#hol-blocking disable
%HOL Blocking is Disabled on: Gi1/1 Gi1/2 Gi1/3 Gi1/4 Gi1/5 Gi1/6 Gi1/7 Gi1/8
这样可以找出来到底是哪一个端口过多overrun,然后将此端口挪到另外一组去。
shared buffers. This will result in only the single over utilized port having drops。查看了一下cisco网站,意思就是说启用head of line blocking使得此8个一组端口的每个端口都启用自己的32kb buffer,而不使用共享的1Mb buffer,这样就能看出到底是哪个端口overrun比较多。详见 [url]http://www.cisco.com/en/US/products/hw/switches/ps700/products_tech_note09186a00801751d7.shtml[/url]
配置命令如下:
6500(config)#service internal //此命令表示可以启用内部命令,注意内部命令TAB或者?都无效,直接敲入就是了。
6500(config)#interface gigabit 1/1
6500(config-if)#hol-blocking disable
%HOL Blocking is Disabled on: Gi1/1 Gi1/2 Gi1/3 Gi1/4 Gi1/5 Gi1/6 Gi1/7 Gi1/8
这样可以找出来到底是哪一个端口过多overrun,然后将此端口挪到另外一组去。
2,try to config "hold queue 4096 in" to raise the hold queue. please refer to :
[url]http://www.cisco.com/en/US/docs/ios/12_3/interface/command/reference/int_d1g.html#wp1142192[/url]
在软件队列处理上通过“hold queue 4096 in”将端口的hold queue调高,看看是否有效果。实际上没有多大效果,依然有很大的丢包。
[url]http://www.cisco.com/en/US/docs/ios/12_3/interface/command/reference/int_d1g.html#wp1142192[/url]
在软件队列处理上通过“hold queue 4096 in”将端口的hold queue调高,看看是否有效果。实际上没有多大效果,依然有很大的丢包。
综合以上测试,case中心给出答复如下:
丢包现象为WS-X6548-GE-TX板卡性能瓶颈所致,即WS-X6548-GE-TX的端口buffer太小,请换成6148A或者6748板卡。下面比较一下此三个板卡的硬件架构:
1),X6548-GE:每8个端口(1-8,9-16,17-24...)共享16KB RX buffer和1MB的RX/TX buffer,并且每8个端口共享1GE带宽,此板卡为fabric-enabled,可以与引擎通过一个8GE的CrossBar或者32GE的系统共享Bus相连;
2),X6148A-GE:每8个端口共享160KB RX buffer,每一个端口独享5.2MB的TX buffer,并且每8个端口共享1GE带宽,但是此板卡为nonfabric-enabled,只能通过32GE的系统共享Bus相连;
3),X6748-GE:每个端口独享166KB的RX buffer和1.164MB的TX buffer,并且此板卡为fabric-enabled,可以与引擎通过每24个端口(1-24,25-48)共享20GE的CrossBar相连或者48GE端口共享32GE的系统共享Bus相连。
丢包现象为WS-X6548-GE-TX板卡性能瓶颈所致,即WS-X6548-GE-TX的端口buffer太小,请换成6148A或者6748板卡。下面比较一下此三个板卡的硬件架构:
1),X6548-GE:每8个端口(1-8,9-16,17-24...)共享16KB RX buffer和1MB的RX/TX buffer,并且每8个端口共享1GE带宽,此板卡为fabric-enabled,可以与引擎通过一个8GE的CrossBar或者32GE的系统共享Bus相连;
2),X6148A-GE:每8个端口共享160KB RX buffer,每一个端口独享5.2MB的TX buffer,并且每8个端口共享1GE带宽,但是此板卡为nonfabric-enabled,只能通过32GE的系统共享Bus相连;
3),X6748-GE:每个端口独享166KB的RX buffer和1.164MB的TX buffer,并且此板卡为fabric-enabled,可以与引擎通过每24个端口(1-24,25-48)共享20GE的CrossBar相连或者48GE端口共享32GE的系统共享Bus相连。
本文转自 chris_lee 51CTO博客,原文链接:http://blog.51cto.com/ipneter/92240,如需转载请自行联系原作者

















 5106
5106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









