






 博客涉及C/C++的内存管理,转载自https://www.cnblogs.com/phpandmysql/p/10835690.html ,但未给出具体运行结果相关的详细内容。
博客涉及C/C++的内存管理,转载自https://www.cnblogs.com/phpandmysql/p/10835690.html ,但未给出具体运行结果相关的详细内容。
在C++中空类会占一个字节,这是为了让对象的实例能够相互区别。具体来说,空类同样可以被实例化,并且每个实例在内存中都有独一无二的地址,因此,编译器会给空类隐含加上一个字节,这样空类实例化之后就会拥有独一无二的内存地址。如果没有这一个字节的占位,那么空类就无所谓实例化了,因为实例化的过程就是在内存中分配一块地址。
注意:当该空白类作为基类时,该类的大小就优化为0了,这就是所谓的空白基类最优化。
注意:当该空白类作为基类时,该类的大小就优化为0了,这就是所谓的空白基类最优化。
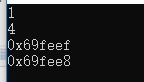
class T { }; int main() { T t1, t2; cout<<sizeof(t1)<<endl; cout<<sizeof(t2)<<endl; cout<<&t1<<endl; cout<<&t2<<endl; return 0; }
运行结果:

如上图所示,这个占位字节仅仅是用来占位。
空白基类最优化:
class T { }; class TT :public T { int a; }; int main() { T t1; TT tt1; cout<<sizeof(t1)<<endl; cout<<sizeof(tt1)<<endl; cout<<&t1<<endl; cout<<&tt1<<endl; return 0; }
运行结果:
在上例中,大部分编译器对于sizeof(derive)的结果是4,而不是8。这就是所谓的空白基类最优化在(empty base optimization-EBO 或 empty base classopimization-EBCO)。在空基类被继承后由于没有任何数据成员,所以子类优化掉基类所占的1 byte。EBO并不是c++标准所规定必须的,但是大部分编译器都会这么做。由于空基类优化技术节省了对象不必要的空间,提高了运行效率,因此成为某些强大技术的基石,基于类型定义类如stl中的binary_function、unary_function、iterator、iterator_traits的实现复用;基于策略类如内存管理、多线程安全同步的实现复用。当某个类存在空类类型的数据成员时,也可考虑借助EBO优化对象布局.

















 14万+
14万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









