<think>嗯,用户需要的是如何使用JMeter配置批量请求,每个请求体包含100条CSV数据的方法。从用户引用的站内资料来看,ta已经掌握了基础的单条数据参数化操作(比如CSVDataSetConfig组件),现在需要扩展为批量处理。用户可能正在做接口压力测试,比如需要模拟批量提交订单或批量创建用户。这类场景的特点是:单次请求需要携带大量数据,但传统参数化只能逐行读取CSV。用户引用[4]提到JSR223脚本和结果存储,说明ta可能还关心结果收集效率。需要解决的核心问题是:如何将100行CSV数据合并为一个请求体。现有组件无法直接实现,得用脚本处理。比较合理的方案是参考用户引用[4]的Groovy脚本思路,但需要改造为累加多行数据。另外用户没提数据是否需要去重或特殊排序,暂时按顺序累加处理。线程组循环控制是个易错点:CSV默认逐行读取,但我们需要每100行才发一次请求。所以循环次数应该是总行数/100,这个计算逻辑最好在脚本里自动处理。用户引用[5]的RecycleonEOF参数也要注意,防止数据不足100时出错。响应数据量大的话,直接存CSV可能影响JMeter性能,要提醒用户控制结果保存字段。另外批量请求失败时的排查更困难,建议ta先在少量数据(比如10条)验证脚本逻辑。</think>
好的,下面讲解如何使用 JMeter 读取 CSV 文件,并将每 **100 条数据组合成一个请求体** 进行批量请求的配置方法。
**核心思路:**
1. 使用 **CSV Data Set Config** 逐行读取 CSV 文件中的单条数据。
2. 使用 **JSR223 脚本(推荐 Groovy)** 或 **BeanShell Sampler** 收集一定数量的行(本例中是 100 行),并将这些数据组装成最终需要的大请求体。
3. 使用一个 **控制器**(如 While Controller 或 Loop Controller)配合计数器来控制收集多少条数据组装一次请求。
4. 配置 **HTTP 请求** 来发送组装好的大请求体。
5. (可选)保存批量请求的结果。
**详细配置步骤:**
### 1. 准备 CSV 文件
* 确保你的 CSV 文件包含所需的数据字段,例如:`id,name,limit,status` 等。
* 文件第一行通常定义为列名(Header)。例如:
```csv
userId,userName,email,productId
1001,UserA,a@example.com,P001
1002,UserB,b@example.com,P002
1003,UserC,c@example.com,P003
... (至少准备 100 行或更多)
```
* **重要:** 确认文件编码(通常 UTF-8)和分隔符(通常逗号 `,`)。
### 2. 添加线程组
* 右键点击 `测试计划` -> `添加` -> `线程(用户)` -> `线程组`。
* 设置 `线程数 (Users)`: 你需要发起多少个 *批量请求*。例如,如果你有 1000 条记录,每组 100 条,那么需要 10 次批量请求,设置`线程数`为 `10`。
* 设置 `循环次数`: `1` (我们通过脚本内部计数来控制读 100 行发一次)。
### 3. 添加 CSV Data Set Config
* 右键点击 `线程组` -> `添加` -> `配置元件` -> `CSV 数据文件设置`。
* 配置如下:
* **文件名 (Filename):** CSV 文件的 *完整路径* (或相对于 JMeter 脚本的路径)。
* **文件编码 (File Encoding):** 与 CSV 文件一致 (如 `UTF-8`)。
* **变量名称 (Variable Names):** CSV 文件 *列名* 对应的 JMeter 变量名,**以逗号分隔**。例如 `csv_userId,csv_userName,csv_email,csv_productId`。JMeter 会按行读取文件,并将每一列的值赋给对应的变量。
* **忽略首行?(Ignore first line):** `True` (如果 CSV 有标题行)。
* **分隔符 (Delimiter):** CSV 实际使用的分隔符,如 `,`。
* **遇到文件结束符再次循环?(Recycle on EOF):** `True` (如果测试数据不足且需要循环使用)。
* **遇到文件结束符停止线程?(Stop thread on EOF):** `False`。
* **变量名称是否共享?(Sharing mode):** `All threads`(通常情况)。
[^1][^2][^5]
### 4. 添加计数器 (Counter)
* 右键点击 `线程组` -> `添加` -> `配置元件` -> `计数器`。
* **目的:** 在脚本中知道我们当前收集到了第几条数据(准备凑齐 100 条发一次)。
* 配置如下:
* **起始值 (Start):** `1`
* **最大值 (Maximum):** `100` (每次批量请求收集的数据条数)
* **引用名称 (Reference Name):** 给计数器一个变量名用于后续脚本访问,例如 `itemCount`。
* **每次迭代后递增?(Increment each iteration?)** 保持默认勾选。
### 5. 添加 While Controller
* 右键点击 `线程组` -> `添加` -> `逻辑控制器` -> `While Controller`。
* **目的:** 控制循环读取 CSV 文件,直到收集满 100 条数据(或者文件尾)。其条件基于计数器和 CSV 文件是否还有数据。
* **条件 (Condition):** 输入 `"${__jexl3("${itemCount}" != "${itemCount_max}" && "${csv_userId}" != "<EOF>",)}"}`
* **解释:**
* `"${itemCount}" != "${itemMax}"`:判断计数器当前值是否还没达到最大值 100 (即还没收集满 100 条)。
* `&&`:并且。
* `"${csv_userId}" != "<EOF>"`:判断 CSV 文件是否没有读到结尾(CSV Data Set Config 在读取完所有行后,会将变量值设置为 `<EOF>`)。
### 6. 添加 JSR223 采样器 (或 BeanShell 采样器) - *收集单行数据*
* 右键点击 `While 控制器` -> `添加` -> `取样器` -> `JSR223 Sampler`(选择 Groovy 语言)。
* **目的:** 在循环内部,每次读取 CSV 文件的一行数据,并将该条数据存储到一个列表变量(`itemsList`)中。同时更新计数器。
* 编写 **Groovy 脚本**:
```groovy
import org.apache.jmeter.threads.JMeterContextService;
// 1. 获取当前线程的变量空间
def ctx = JMeterContextService.getContext();
def vars = ctx.getVariables();
// 2. 初始化存储数据行的 List (每次批量请求开始时,List 应该是空的)
// 利用 vars.getObject("itemsList") 或直接操作 vars.putObject
if (vars.get("itemCount") == "1") { // 如果是本次批量请求的第一条数据
vars.putObject("itemsList", new java.util.ArrayList()); // 新建一个空 List
}
// 3. 获取当前行读取的 CSV 变量值
// 假设 CSV 列名对应的变量名如配置: csv_userId, csv_userName, csv_email, csv_productId
def currentItem = [
userId: vars.get("csv_userId"),
userName: vars.get("csv_userName"),
email: vars.get("csv_email"),
productId: vars.get("csv_productId")
];
// 4. 将当前行数据 Map 添加到 itemsList 中
def itemsList = vars.getObject("itemsList");
itemsList.add(currentItem);
vars.putObject("itemsList", itemsList); // 更新回变量空间
// 5. 增加计数器 (这一步由计数器本身自动完成,脚本里通常不需要操作,但可以获取其值记录日志)
def currentCount = vars.get("itemCount").toInteger();
// 6. 模拟执行一次采样器 (如果脚本作为采样器存在,需要有有效的 SampleResult)
SampleResult.setResponseData("Collecting item ${currentCount}", "UTF-8");
// 重要:确保 While Controller 能继续进行下一次迭代(计数器自增在下一次迭代前自动发生)
```
* **关键点:**
* 使用 `vars.putObject("itemsList", ...)` 和 `vars.getObject("itemsList")` 来存储和操作复杂的 List 对象。
* `if (vars.get("itemCount") == "1")` 确保在收集第一条数据时初始化 `itemsList`。
* 每次迭代创建一条数据的 `Map` (`currentItem`) 并加入 `itemsList`。
* `SampleResult.setResponseData(...)` 确保脚本能返回一个有效结果。
[^3] (概念相关: 循环控制)
### 7. 添加 JSR223 PostProcessor - *组装批量请求体并清除临时数据*
* 右键点击 `While 控制器` -> `添加` -> `后置处理器` -> `JSR223 PostProcessor`(选择 Groovy 语言)。
* **位置:** 放在 `While 控制器` 内部的 **最后面**(在 JSR223 采样器之后,但在退出 `While 控制器` 之前)。
* **目的:**
1. 在收集完一批数据(100 条)退出 `While 控制器` 后,将 `itemsList` 中的数据组装成最终的批量请求体(通常是 JSON 或 XML 格式字符串)。
2. 将组装好的请求体字符串放入一个 JMeter 变量(如 `batchRequestBody`),供后面的 HTTP 请求使用。
3. 清空 `itemsList` 和计数器变量(可选,但建议做,为下一次批量请求做准备)。
* 编写 **Groovy 脚本**:
```groovy
import groovy.json.JsonOutput
// 1. 获取存储的数据行 List
def itemsList = vars.getObject("itemsList");
if (itemsList == null || itemsList.isEmpty()) {
log.error("ItemsList is empty! Batch request body cannot be generated.");
vars.put("batchRequestBody", '{"error": "No items collected"}');
// 或者可以考虑设置一个标记跳过 HTTP 请求
return;
}
// 2. 根据 API 要求的格式,组装批量请求体
// 示例: 生成一个包含 itemsList 中所有对象的 JSON 数组
def batchPayload = [
data: itemsList // 假设 API 要求的数据字段名是 "data"
];
// 使用 JsonOutput 将 Groovy Map/List 转换为 JSON 字符串
def jsonPayload = JsonOutput.toJson(batchPayload);
def prettyPayload = JsonOutput.prettyPrint(jsonPayload); // 美化可读,可选
// 3. 将 JSON 字符串放入 JMeter 变量
vars.put("batchRequestBody", prettyPayload); // 或者直接用 jsonPayload
// 4. (重要) 清除临时变量,为下一次批量请求做准备 (放在线程组下的计数器负责重置计数)
// 方法 1: 清除 itemsList 对象
// vars.putObject("itemsList", null); // 可以但可能不够彻底
// 方法 2: 更安全移除变量
vars.remove("itemsList");
// 如果需要,也可以在这里重置计数器值到起点(虽然计数器配置元件默认行为是每次迭代重置)
// vars.put("itemCount", "1");
```
* **关键点:**
* 使用 Groovy 的 `JsonOutput` 方便地转换对象为 JSON。
* 脚本逻辑执行在 `While 控制器` 的循环结束后(即达到 100 条或文件尾)。
* 组装好的请求体字符串放入 `batchRequestBody` 变量。
* **强烈建议清除 `itemsList` 变量 (`vars.remove("itemsList")`)**,避免影响下一次迭代。
### 8. 添加 HTTP 请求
* 右键点击 `线程组` -> `添加` -> `取样器` -> `HTTP 请求`。
* **配置:**
* **协议**: `http` 或 `https`
* **服务器名称或 IP**: API 服务地址。
* **端口号**: API 端口(如有)。
* **方法**: 通常是 `POST` 或 `PUT` (用于批量创建/更新)。
* **路径**: API 端点路径。
* **请求体:** (关键)
* 切换到 `Body Data` 标签页。
* 将上一步 `JSR223 PostProcessor` 生成的 `batchRequestBody` 变量填入: `${batchRequestBody}`
* **请求头:**
* 切换到 `消息头管理器`,添加必要的 Header,特别是:
* `Content-Type: application/json` (如果请求体是 JSON)
* `Authorization: Bearer <token>` (如果需要认证)
* 其他 API 要求的 Header。
### 9. (可选) 添加监听器保存结果
* 右键点击 `线程组` -> `添加` -> `监听器` -> `用表格查看结果` (查看概要)。
* 右键点击 `线程组` -> `添加` -> `监听器` -> `保存响应到文件`。**注意:** 如果批量返回的数据很大,保存到文件可能会影响性能并生成庞大的结果文件。仅在有明确分析需求时使用。
* 更常见的做法是使用 **Simple Data Writer** 保存关键响应信息到 CSV:
* 右键点击 `线程组` -> `添加` -> `监听器` -> `Simple Data Writer`。
* 配置 `文件名`。
* 勾选你感兴趣的字段,如 `timeStamp`, `elapsed`, `label`, `responseCode`, `responseMessage`, `failureMessage`, `bytes`, `isSuccess`, `requestData`, `responseData` (注意 `responseData` 通常很大)。
* 设置 `Separator` (如 `,`)。
* 如果使用 `保存响应到文件`,可以在文件名中使用变量(如 `${__time()}`)避免覆盖:
* 在 `保存响应到文件` 的 `File` 字段填入类似:`results/Batch_Response_${__time(yyyyMMdd-HHmmss)}.dat`。
[^4]
## 工作流程总结
1. 线程组初始化,启动指定线程数(批量请求次数)。
2. 每个线程开始执行:
* 计数器初始化为 1。
* 进入 `While 控制器`。
* *条件检查*:计数器 `< 100` *且* CSV 数据有效 (`!= <EOF>`)?
* *条件为真*:
* 执行 `JSR223 采样器`:将 CSV 读取的当前行存储到 `itemsList` (List 中)。
* 计数器自增(自动)。
* 回到循环条件检查。
* *条件为假*(计数器到 100 或文件尾):退出 `While 控制器`。
* 执行 `JSR223 PostProcessor`:
* 将 `itemsList` 中的数据组装成 JSON (或其他格式) 的 `batchRequestBody` 字符串。
* 清除 `itemsList` 变量。
* 执行 `HTTP 请求`:将 `${batchRequestBody}` 作为请求体发送。
* 处理并记录响应(可选)。
* 线程结束。
## 注意事项
1. **文件尾处理:** 逻辑需要能处理文件结尾时不足 100 条数据的情况(`While` 条件中的 `<EOF>` 判断会保证即使不足 100 条也正常退出循环并生成请求体)。
2. **性能:** `While 控制器` + Groovy 脚本本身会有一定开销。对于极高并发的压测场景,需评估是否成为瓶颈。
3. **内存:** 脚本中在内存中累积 `itemsList`。每组 100 条数据通常问题不大,但要注意数据量和结构复杂度。避免在一个测试中累积非常大的对象列表。
4. **JSON 库:** `JsonOutput` 是 Groovy 的标准库。如果遇到特殊字符或序列化问题,可以尝试使用其他库(如 `import groovy.json.JsonBuilder`)。
5. **调试:** 使用 `Debug Sampler` 和 `View Results Tree` 监听器检查 `itemsList` 和 `batchRequestBody` 的值是否正确。在脚本中使用 `log.info(...)` 输出调试信息(可以在 JMeter `bin/jmeter.log` 中查看)。
6. **数据清洗:** CSV 文件中可能有 JMeter 无法直接处理的特殊字符(如换行符、引号),在 Groovy 脚本中组装 JSON 时需要注意转义处理。必要时在读取 CSV 后对数据进行清洗。
7. **线程安全:** 确保 `itemsList` 的初始化、操作、清理只发生在单个线程内(不要跨线程共享),本配置方案默认是每个线程有自己的副本。
按照上述步骤配置完成后,运行测试计划,JMeter 就会按照要求,每读取 CSV 文件的 100 行数据(或到文件尾),就组装成一个包含 100 条数据的请求体并发起一次 HTTP 请求。
[^1][^2][^3][^4][^5]: 以上配置参考并融合了 CSV 数据文件设置、循环控制、脚本处理和结果保存的相关原理。








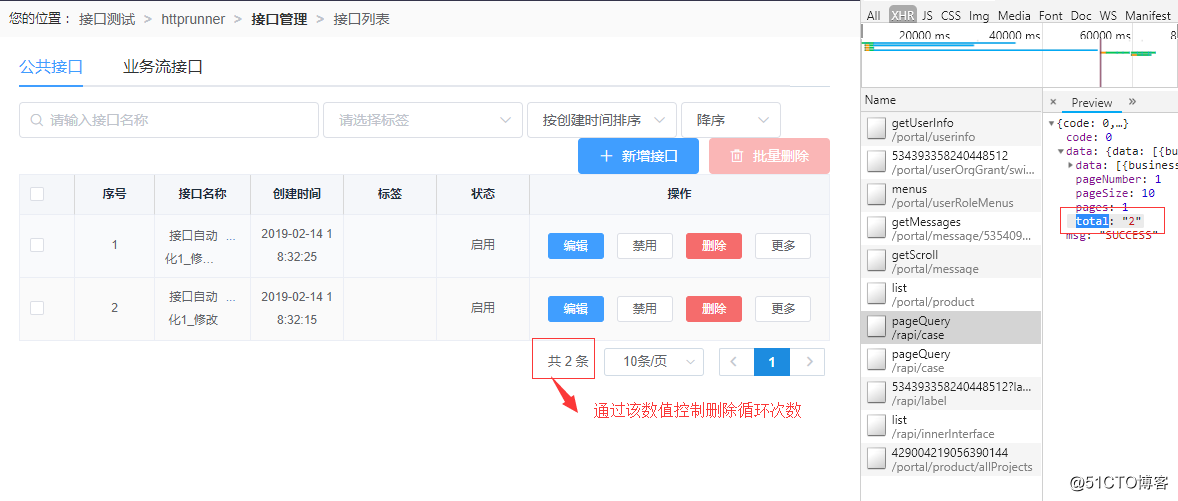
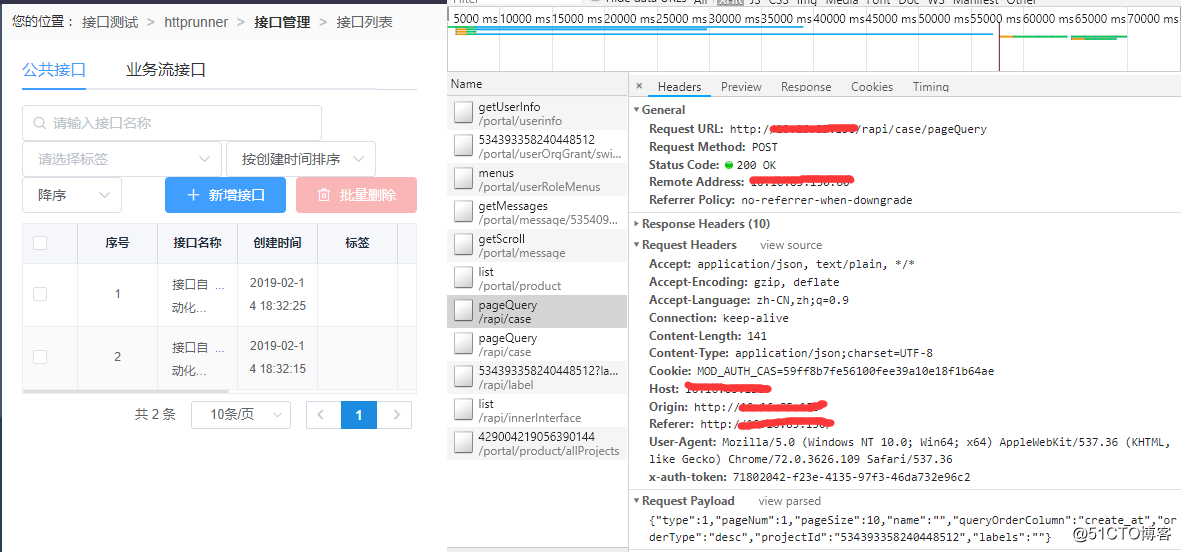
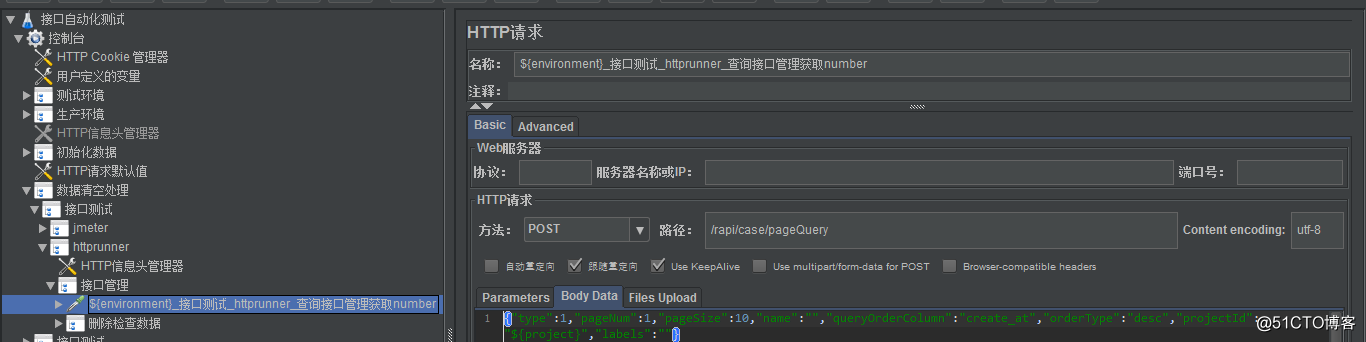
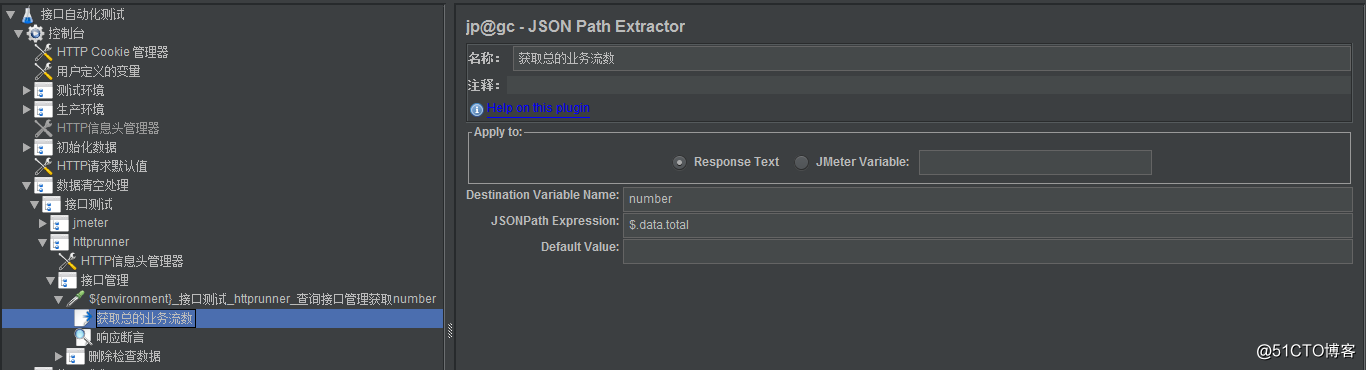
 本文介绍了如何使用Jmeter在接口自动化测试中初始化并清空旧数据,包括通过获取total数值和利用jmeter变量matchNr进行清空的两种方法,并强调了在数据删除时的数据安全校验,提出在执行自动清除前进行projectid的有效性判断以避免生产事故。
本文介绍了如何使用Jmeter在接口自动化测试中初始化并清空旧数据,包括通过获取total数值和利用jmeter变量matchNr进行清空的两种方法,并强调了在数据删除时的数据安全校验,提出在执行自动清除前进行projectid的有效性判断以避免生产事故。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1248
1248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









