






 本文介绍了一个简单的机器阅读理解模型——AttentionSumReader。该模型通过词嵌入、双向GRU编码和注意力机制,有效地解决了CNN/DailyMail及CBT数据集上的问题。实验表明,即使模型简单,也能取得优秀的效果。
本文介绍了一个简单的机器阅读理解模型——AttentionSumReader。该模型通过词嵌入、双向GRU编码和注意力机制,有效地解决了CNN/DailyMail及CBT数据集上的问题。实验表明,即使模型简单,也能取得优秀的效果。
本文是机器阅读系列的第四篇文章,本文的模型常出现在最新的机器阅读paper中related works部分,也是很多更好的模型的基础模型,所以很有必要来看下这篇paper,看得远往往不是因为长得高,而是因为站得高。本文的题目是Text Understanding with the Attention Sum Reader Network,作者是来自IBM Watson的研究员Rudolf Kadlec,paper最早于2016年3月4日submit在arxiv上。
本文的模型被称作Attention Sum Reader,具体见下图:
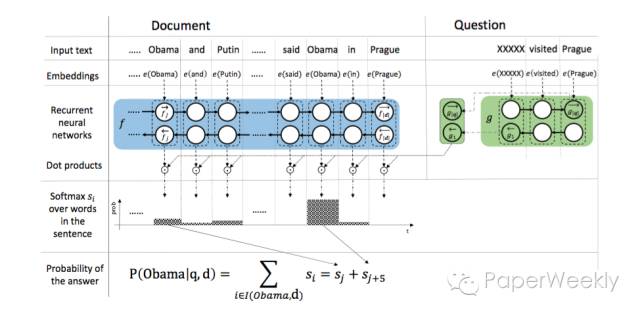
step 1 通过一层Embedding层将document和query中的word分别映射成向量。
step 2 用一个单层双向GRU来encode document,得到context representation,每个time step的拼接来表示该词。
step 3 用一个单层双向GRU来encode query,用两个方向的last state拼接来表示query。
step 4 每个word vector与query vector作点积后归一化的结果作为attention weights,就query与document中的每个词之前的相关性度量。
step 5 最后做一次相同词概率的合并,得到每个词的概率,最大概率的那个词即为answer。
模型在CNN/Daily Mail和CBT的Nouns、Named Entity数据集上进行了测试,在当时的情况下都取得了领先的结果。并且得到了一些有趣的结论,比如:在CNN/Daily Mail数据集上,随着document的长度增加,测试的准确率会下降,而在CBT数据集上得到了相反的结论。从中可以看得出,两个数据集有着不同的特征,构造方法也不尽相同,因此同一个模型会有着不同的趋势。
本文的模型相比于Attentive Reader和Impatient Reader更加简单,没有那么多繁琐的attention求解过程,只是用了点乘来作为weights,却得到了比Attentive Reader更好的结果,从这里我们看得出,并不是模型越复杂,计算过程越繁琐就效果一定越好,更多的时候可能是简单的东西会有更好的效果。
另外,在这几篇paper中的related works中,都会提到用Memory Networks来解决这个问题。接下来的文章将会分享Memory Networks在机器阅读理解中的应用,大家敬请关注。
来源:paperweekly

















 175
175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









