



 本文探讨了在多个二项式模型中选择最佳模型的方法。通过将数据分为训练集、交叉验证集和测试集,利用交叉验证误差和推广误差评估模型性能,确保所选模型不仅在训练数据上表现良好,还能泛化到未知数据。
本文探讨了在多个二项式模型中选择最佳模型的方法。通过将数据分为训练集、交叉验证集和测试集,利用交叉验证误差和推广误差评估模型性能,确保所选模型不仅在训练数据上表现良好,还能泛化到未知数据。
假设我们要在10 个不同次数的二项式模型之间进行选择:
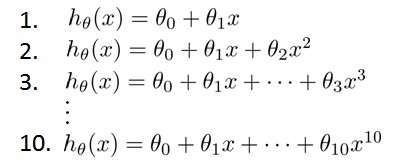
显然越高次数的多项式模型越能够适应我们的训练数据集,但是适应训练数据集并不
代表着能推广至一般情况,我们应该选择一个更能适应一般情况的模型。我们需要使用交叉
验证集来帮助选择模型。
即:使用60%的数据作为训练集,使用 20%的数据作为交叉验证集,使用20%的数据
作为测试集。
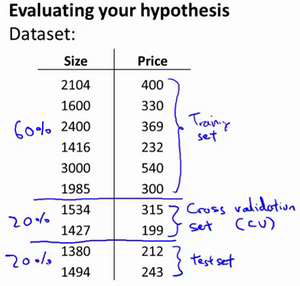
模型选择的方法为:
1. 使用训练集训练出10 个模型
2. 用10 个模型分别对交叉验证集计算得出交叉验证误差(代价函数的值)
3. 选取代价函数值最小的模型
4. 用步骤3 中选出的模型对测试集计算得出推广误差(代价函数的值)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









