






 本文介绍如何在Hadoop集群中部署和配置Ganglia监控工具,包括安装过程、配置详解及启动预览等内容。
本文介绍如何在Hadoop集群中部署和配置Ganglia监控工具,包括安装过程、配置详解及启动预览等内容。
1.概述
最近,有朋友私密我,Hadoop有什么好的监控工具,其实,Hadoop的监控工具还是蛮多的。今天给大家分享一个老牌监控工具Ganglia,这个在企业用的也算是比较多的,Hadoop对它的兼容也很好,不过就是监控界面就不是很美观。下次给大家介绍另一款工具——Hue,这个界面官方称为Hadoop UI,界面美观,功能也比较丰富。今天,在这里主要给大家介绍Ganglia这款监控工具,介绍的内容主要包含如下:
- Ganglia背景
- Ganglia安装部署、配置
- Hadoop集群配置Ganglia
- 启动、预览Ganglia
下面开始今天的内容分享。
2.Ganglia背景
Ganglia是UC Berkeley发起的一个开源集群监视项目,设计用于测量数以千计的节点。Ganglia的核心包含gmond、gmetad以及一个Web前端。主要是用来监控系统性能,如:cpu 、mem、硬盘利用率, I/O负载、网络流量情况等,通过曲线很容易见到每个节点的工作状态,对合理调整、分配系统资源,提高系统整体性能起到重要作用。
Ganglia其核心由3部分组成:
- gmond:运行在每个节点上监视并收集节点信息,可以同时收发统计信息,它可以运行在广播模式和单播模式中。
- gmetad:从gmond以poll的方式收集和存储原数据。
- ganglia-web:部署在gmetad机器上,访问gmetad存储的元数据并由Apache Web提高用户访问接口。
下面,我们来看看Ganglia的架构图,如下图所示:
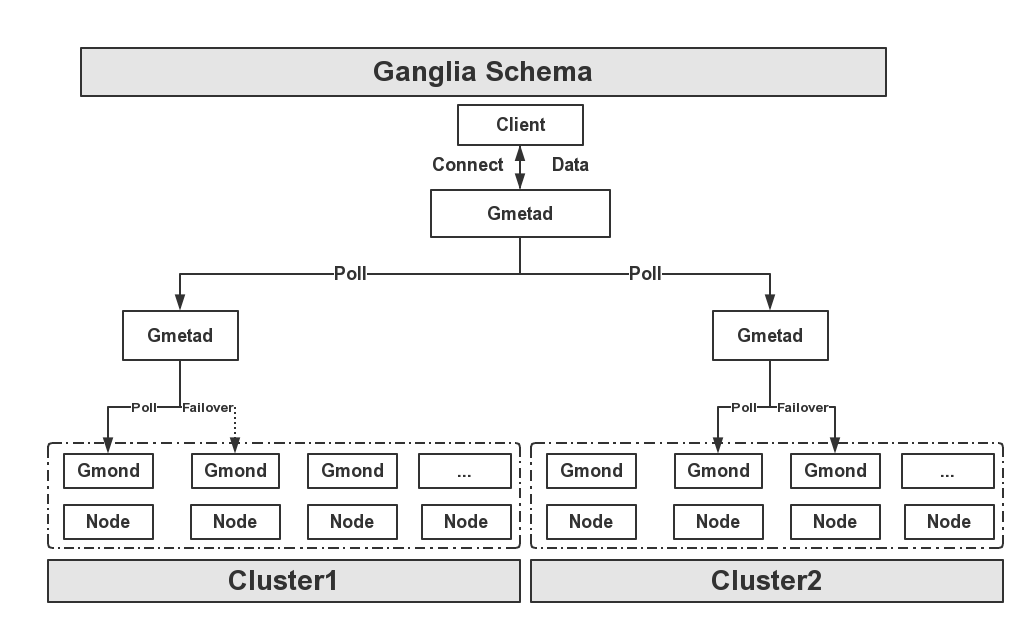
从架构图中,我们可以知道Ganglia支持故障转移,统计可以配置多个收集节点。所以我们在配置的时候,可以按需选择去配置Ganglia,既可以配置广播,也可以配置单播。根据实际需求和手上资源来决定。
3.Ganglia安装部署、配置
3.1安装
本次安装的Ganglia工具是基于Apache的Hadoop-2.6.0。另外系统环境是CentOS 6.6。首先,我们下载Ganglia软件包,步骤如下所示:
- 第一步:安装yum epel源
[hadoop@nna ~]$ rpm -Uvh http://dl.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch.rpm
- 第二步:安装依赖包
[hadoop@nna ~]$ yum -y install httpd-devel automake autoconf libtool ncurses-devel libxslt groff pcre-devel pkgconfig
- 第三步:查看Ganglia安装包
[hadoop@nna ~]$ yum search ganglia
然后,我为了简便,把Ganglia安装全部安装,安装命令如下所示:
- 第四步:安装Ganglia
[hadoop@nna ~]$ yum -y install ganglia*
最后等待安装完成,由于这里资源有限,我将Ganglia Web也安装在NNA节点上,另外,其他节点也需要安装Ganglia的Gmond服务,该服务用来发送数据到Gmetad,安装方式参考上面的步骤。
3.2部署
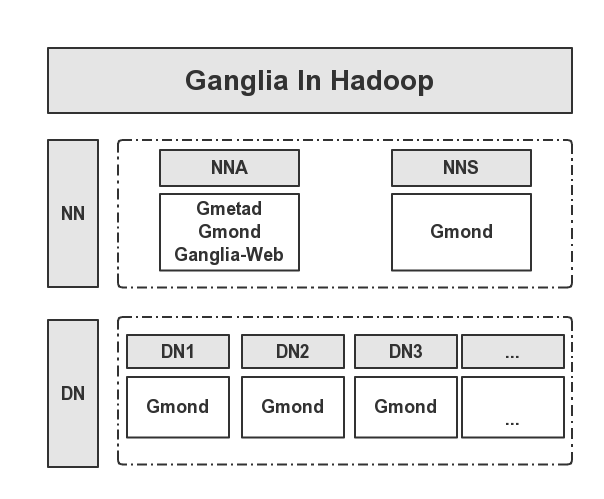
在安装Ganglia时,我这里将Ganglia Web部署在NNA节点,其他节点部署Gmond服务,下表为各个节点的部署角色:
| 节点 | Host | 角色 |
| NNA | 10.211.55.26 | Gmetad、Gmond、Ganglia-Web |
| NNS | 10.211.55.27 | Gmond |
| DN1 | 10.211.55.16 | Gmond |
| DN2 | 10.211.55.17 | Gmond |
| DN3 | 10.211.55.18 | Gmond |
Ganglia部署在Hadoop集群的分布图,如下所示:
3.3配置
在安装好Ganglia后,我们需要对Ganglia工具进行配置,在由Ganglia-Web服务的节点上,我们需要配置Web服务。
-
ganglia.conf
[hadoop@nna ~]$ vi /etc/httpd/conf.d/ganglia.conf
#
# Ganglia monitoring system php web frontend
#
Alias /ganglia /usr/share/ganglia
<Location /ganglia>
Order deny,allow
# Deny from all
Allow from all
# Allow from 127.0.0.1
# Allow from ::1
# Allow from .example.com
</Location>注:红色为添加的内容,绿色为注销的内容。
- gmetad.conf
[hadoop@nna ~]$ vi /etc/ganglia/gmetad.conf
修改内容如下所示:
data_source "hadoop" nna nns dn1 dn2 dn3
这里“hadoop”表示集群名,nna nns dn1 dn2 dn3表示节点域名或IP。
- gmond.conf
[hadoop@nna ~]$ vi /etc/ganglia/gmond.conf
/*
* The cluster attributes specified will be used as part of the <CLUSTER>
* tag that will wrap all hosts collected by this instance.
*/
cluster {
name = "hadoop"
owner = "unspecified"
latlong = "unspecified"
url = "unspecified"
}
/* Feel free to specify as many udp_send_channels as you like. Gmond
used to only support having a single channel */
udp_send_channel {
#bind_hostname = yes # Highly recommended, soon to be default.
# This option tells gmond to use a source address
# that resolves to the machine's hostname. Without
# this, the metrics may appear to come from any
# interface and the DNS names associated with
# those IPs will be used to create the RRDs.
# mcast_join = 239.2.11.71
host = 10.211.55.26
port = 8649
ttl = 1
}
/* You can specify as many udp_recv_channels as you like as well. */
udp_recv_channel {
# mcast_join = 239.2.11.71
port = 8649
bind = 10.211.55.26
retry_bind = true
# Size of the UDP buffer. If you are handling lots of metrics you really
# should bump it up to e.g. 10MB or even higher.
# buffer = 10485760
}这里我采用的是单播,cluster下的name要与gmetad中的data_source配置的名称一致,发送节点地址配置为NNA的IP,接受节点配置在NNA上,所以绑定的IP是NNA节点的IP。以上配置是在有Gmetad服务和Ganglia-Web服务的节点上需要配置,在其他节点只需要配置gmond.conf文件即可,内容配置如下所示:
/* Feel free to specify as many udp_send_channels as you like. Gmond
used to only support having a single channel */
udp_send_channel {
#bind_hostname = yes # Highly recommended, soon to be default.
# This option tells gmond to use a source address
# that resolves to the machine's hostname. Without
# this, the metrics may appear to come from any
# interface and the DNS names associated with
# those IPs will be used to create the RRDs.
# mcast_join = 239.2.11.71
host = 10.211.55.26
port = 8649
ttl = 1
}
/* You can specify as many udp_recv_channels as you like as well. */
udp_recv_channel {
# mcast_join = 239.2.11.71
port = 8649
# bind = 10.211.55.26
retry_bind = true
# Size of the UDP buffer. If you are handling lots of metrics you really
# should bump it up to e.g. 10MB or even higher.
# buffer = 10485760
}4.Hadoop集群配置Ganglia
在Hadoop中,对Ganglia的兼容是很好的,在Hadoop的目录下/hadoop-2.6.0/etc/hadoop,我们可以找到hadoop-metrics2.properties文件,这里我们修改文件内容如下所示,命令如下所示:
[hadoop@nna hadoop]$ vi hadoop-metrics2.properties
namenode.sink.ganglia.servers=nna:8649
#datanode.sink.ganglia.servers=yourgangliahost_1:8649,yourgangliahost_2:8649
resourcemanager.sink.ganglia.servers=nna:8649
#nodemanager.sink.ganglia.servers=yourgangliahost_1:8649,yourgangliahost_2:8649
mrappmaster.sink.ganglia.servers=nna:8649
jobhistoryserver.sink.ganglia.servers=nna:8649这里修改的是NameNode节点的内容,若是修改DataNode节点信息,内容如下所示:
#namenode.sink.ganglia.servers=nna:8649
datanode.sink.ganglia.servers=dn1:8649
#resourcemanager.sink.ganglia.servers=nna:8649
nodemanager.sink.ganglia.servers=dn1:8649
#mrappmaster.sink.ganglia.servers=nna:8649
#jobhistoryserver.sink.ganglia.servers=nna:8649其他DN节点可以以此作为参考来进行修改。
另外,在配置完成后,若之前Hadoop集群是运行的,这里需要重启集群服务。
5.启动、预览Ganglia
Ganglia的启动命令有start、restart以及stop,这里我们分别在各个节点启动相应的服务,各个节点需要启动的服务如下:
- NNA节点:
[hadoop@nna ~]$ service gmetad start
[hadoop@nna ~]$ service gmond start
[hadoop@nna ~]$ service httpd start
- NNS节点:
[hadoop@nns ~]$ service gmond start
- DN1节点:
[hadoop@dn1 ~]$ service gmond start
- DN2节点:
[hadoop@dn2 ~]$ service gmond start
- DN3节点:
[hadoop@dn3 ~]$ service gmond start
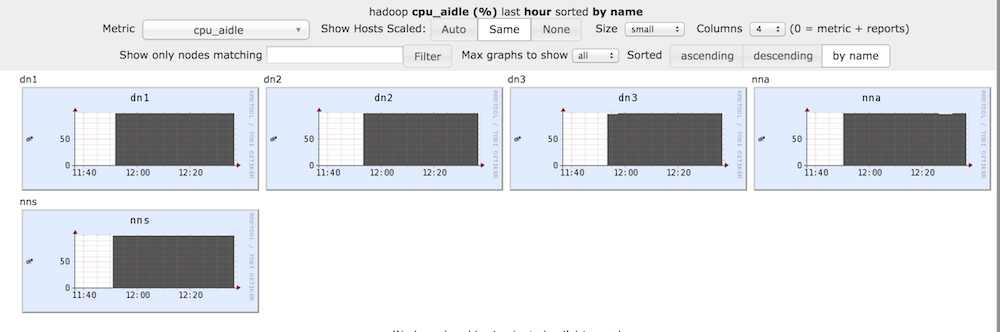
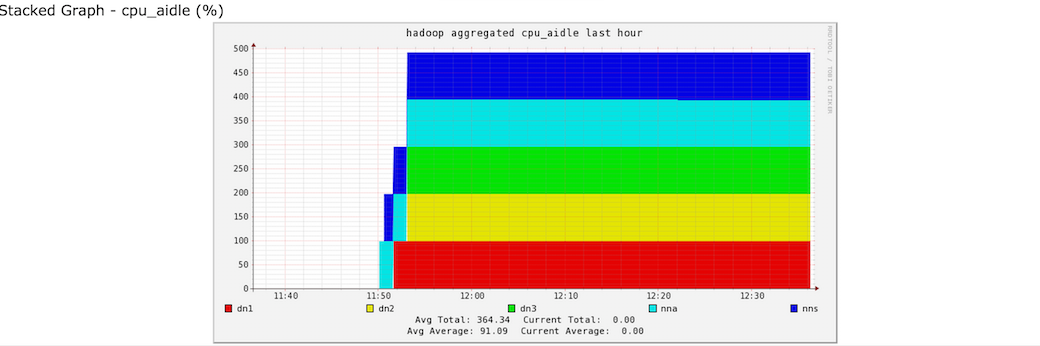
然后,到这里Ganglia的相关服务就启动完毕了,下面给大家附上Ganglia监控的运行截图,如下所示:
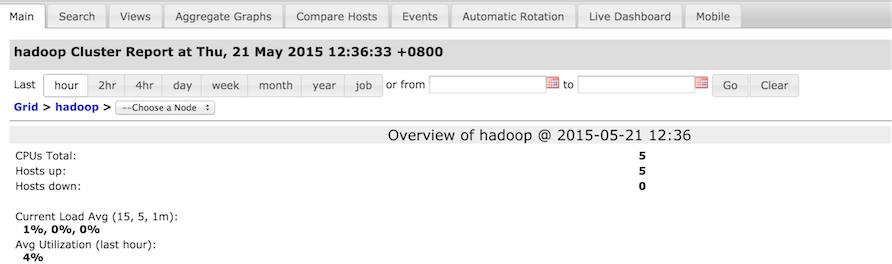
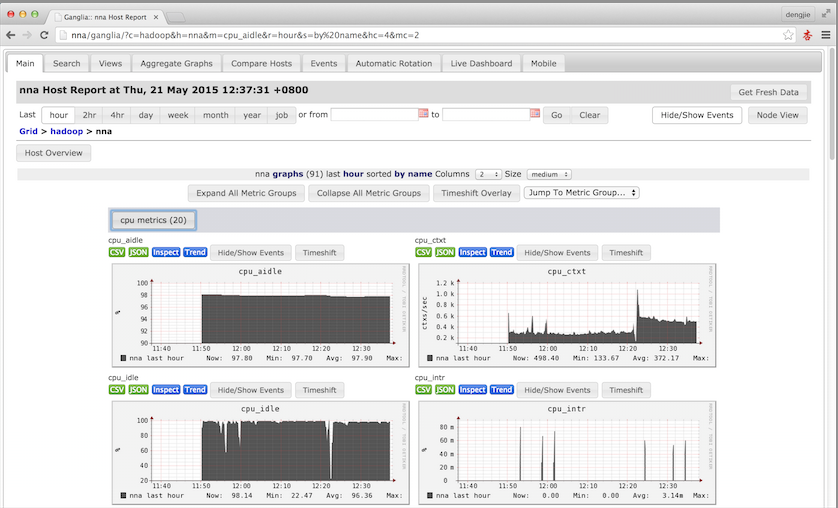
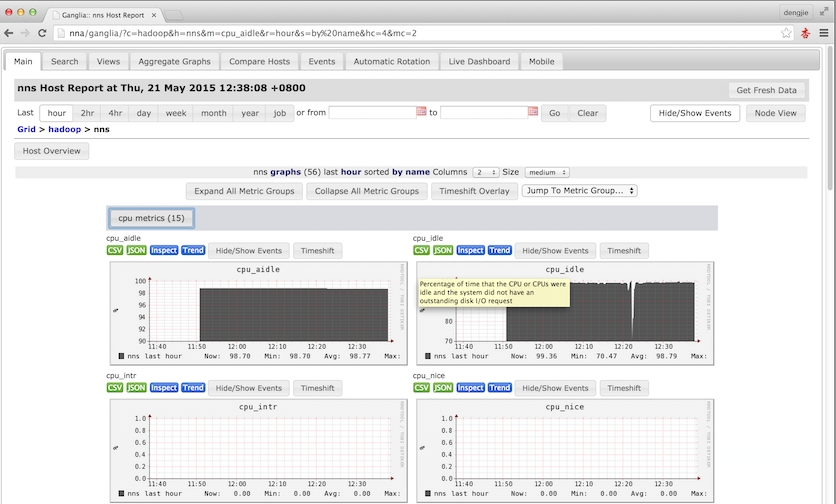
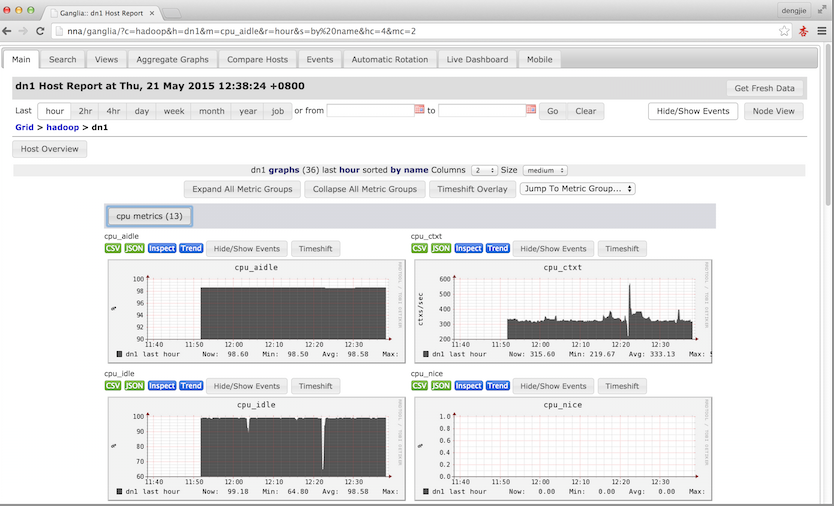
6.总结
在安装Hadoop监控工具Ganglia时,需要在安装的时候注意一些问题,比如:系统环境的依赖,由于Ganglia需要依赖一些安装包,在安装之前把依赖环境准备好,另外在配置Ganglia的时候需要格外注意,理解Ganglia的架构很重要,这有助于我们在Hadoop集群上去部署相关的Ganglia服务,同时,在配置Hadoop安装包的配置文件下(/etc/hadoop)目录下,配置Ganglia配置文件。将hadoop-metrics2.properties配置文件集成到Hadoop集群中去。
7.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!

















 1821
1821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









