






参考:http://en.wikipedia.org/wiki/Discounted_cumulative_gain
Normalized Discounted Cumulative Gain:一种对搜索引擎或相关程序有效性的度量。
2个假设:
1.强相关的文档出现在结果列表越靠前(rank越高)越有用。
2.强相关文档比弱相关文档有用,比不相关文档有用。
DCG来源于一个更早的、更基础的方法---CG。
CG不考虑结果集中的序信息,单纯把分级相关度相加。位置P处的CG值是:

 是搜索结果列表的位置i处结果的分级相关度。
是搜索结果列表的位置i处结果的分级相关度。
改变搜索结果的位置顺序不会影响p的CG值。也就是说:移动一个相关性高的文档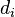 到一个评级较高但相关性不大的文档上面不改变CG的值。
到一个评级较高但相关性不大的文档上面不改变CG的值。
DCG取代CG作为一个更准确的测量方法。
如果一个强相关的文档排名靠后则应该受到惩罚,位置P处的DCG值是:

另一个DCG计算公式更加强调相关性

若分级相关度只在0和1取二值的话,二公式效果相同
nDCG
根据Query的不同,结果列表的长度也不同,所以这一度量考虑了正规化问题

IDCGp(Ideal DCG)是在一个完美的排序下,p所具有的最大DCG值
这样一来无论Query是什么,nDCG都可以得到一个平均值,因此不同的Query之间的效能就可以做比较了。
完美的排序算法会使DCGp和IDCGp相同,从而使nDCGp为1,nDCG的取值在0到1之间
例:
结果列表中的6篇文档D1,D2,D3,D4,D5,D6,判定了他们的相关度是3,2,3,0,1,2,则:
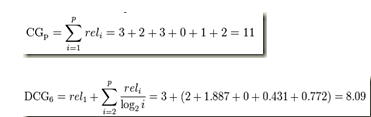
一个理想的排序应该是:3,3,2,2,1,0,所以

nDCG的缺点是:当排序的数很少(比如:只有1-3个),那么任何排序的nDCG值都比较接近,所以可以考虑使用AUC(area under the ROC curve)。
AUC学习参考文章:http://blog.youkuaiyun.com/chjjunking/article/details/5933105


















 1467
1467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









