






 本文介绍如何使用awk命令处理特定格式的数据,包括从JSON和SQL插入语句中提取关键信息、替换指定关键字所在的行以及统计IP地址出现次数等实用操作。
本文介绍如何使用awk命令处理特定格式的数据,包括从JSON和SQL插入语句中提取关键信息、替换指定关键字所在的行以及统计IP地址出现次数等实用操作。

问题描述如下需要取得奇数行PlatformId:后边的字段或者insert后的第10个字段, 奇数行不会同时出现这两个标签
偶数行的竖线分割的第二个字段
数据如下
{"Channel":"abc","PlatformId":"123345","CpInfo":"","Code":"1","Message":""}
28202|1962|214290201||1427859800|xxxxxxxxxxxxxxxx
--
{"Channel":"abc","PlatformId":"123346","CpInfo":"","Code":"1","Message":""}
28202|1932|214290208||1427859979|xxxxxxxxxxxxxxx
--
insert into mylogin(platformId,tank,uuk,kku) values ('12347','214290210','357159050234338',1427860159);
28202|1969|214290210||1427860159|xxxxxxxxxxxxxxx
--
{"Channel":"abc","PlatformId":"123348","CpInfo":"","Code":"1","Message":""}
28202|1962|214290201||1427859800|xxxxxxxxxxxxxxxx
--
{"Channel":"abc","PlatformId":"123349","CpInfo":"","Code":"1","Message":""}
28202|1932|214290208||1427859979|xxxxxxxxxxxxxxx
--
insert into mylogin(platformId,tank,uuk,kku) values ('123450','214290210','357159050234338',1427860159);
28202|1969|214290210||1427860159|xxxxxxxxxxxxxxx
--
awk脚本如下文件名称awk-test.sh
#!/usr/bin/awk -f
BEGIN{#这里得大括弧不可以放在下边BEGIN必须要大写
FS="[ \(,:|]";
count=0 ;
line=0;
account="";
}
#行号自加过滤掉无效的空白行
{
line++;
if(NF >1)
count++
}
#在出现标签的行把需要的数据现保存在account变量
/PlatformId/{#这里得大括弧不可以放在下边
account=$4
}
/insert/{#这里得大括弧不可以放在下边
account=$10
}
#在偶数行打印需要输出的数据
{
if(count%2==0 && NF>1)
printf("%s,%d,count:%d\n",account,$2,line)
}
执行方法 ./awk-test.sh a.txt 数据要保存在a.txt内
替换包含指定关键字的行的指定列的数据,需要注意的是使用gsub替换而不是直接给列赋值,修改源文件需要如下这样执行 a.sh file 1<>file
#!/usr/bin/awk -f
BEGIN{#这里得大括弧不可以放在下边BEGIN必须要大写
FS="[ \(,:|]";
}
#在出现标签的行把需要的数据现保存在account变量
/s59b0c01627258/{#这里得大括弧不可以放在下边
gsub($16,"\"203\"")
}
/s599e903388b40/{
gsub($16,"\"207\"")
}
/s59b0c270704e9/{
gsub($16,"\"207\"")
}
{
print
}
关于awk的分隔符的理解如下如果以FS="[: ]"作为分隔符可以被分割为四个字段
port number :7766
$1=port,$2=number,$3="",$4=7766,关于$3的来源,因为空格和冒号是连着的,连着的两个分隔符中间肯定是个空字符
然后就可以很容的理解下面的这行被分割为五个字段了
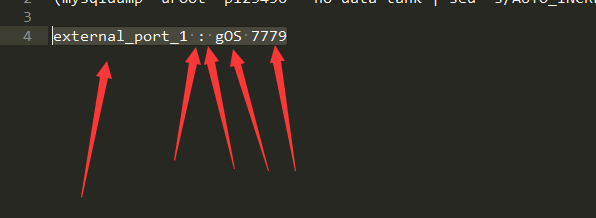
external_port_1 : gOS 7779
统计ip地址出现次数最多的前十个
uniq -c, --count 在每行前加上表示相应行目出现次数的前缀编号
sort -nr 依照数值的大小倒叙排列
awk '{print $1}' ./access.log | sort | uniq -c | sort -nr | head -10

















 362
362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









