







用更好的硬件
用更好的CPU
- 主频高,让每个SQL处理时间更快,减少等待
- L1/L2/L3 Cache更大,每次CPU计算速率更快
- 线程多,同时支持更多并发SQL,提高TPS同时关闭NUMA并设置为最大性能模式
注:TPS的意思是系统吞吐量,关于相关概念的理解,我这里转载了一篇不错的文章可以给大家借鉴参考一下。
用更好的内存
- 主频高,内存读写速率更高,更高吞吐,更低时延
- 内存大,更多数据在内存中,减少直接磁盘读写,提高TPS
用更好的磁盘
- 通常来说,磁盘I/O是最大的瓶颈
- 如果是机械硬盘一定要配阵列卡,以及阵列卡的CACHE&BBU,并且使用(FORCE)WB策略
- 最好选用SSD或者PCle SSD, iops可以提升成千上万倍
用更好的网卡/网络
- 文件传输速率高,异地文件备份更快
- 主从数据复制数据传输时延更小
- 适合大数据量的分布式存储环境
- 老版本内核中,网络请求太高时会引发中断瓶颈,建议升级内核
- 多个网卡可以进行绑定,提高传输速率并提高可用性
让OS跑得更快
关闭无用服务
- 减少系统开销
- 避免潜在安全隐患
尽可能使用本地高速存储
- 坚决不用nfs
- 除非是基于SSD的高速网络分布式存储
- 用于备份场景除外
让数据库跑在专用服务器上,不混搭
- 性能上不相互影响
- 提高安全性
- 必须混搭时要做好权限管理以及安全隔离
io scheduler
- 选择deadline, noop,坚决不用cfq
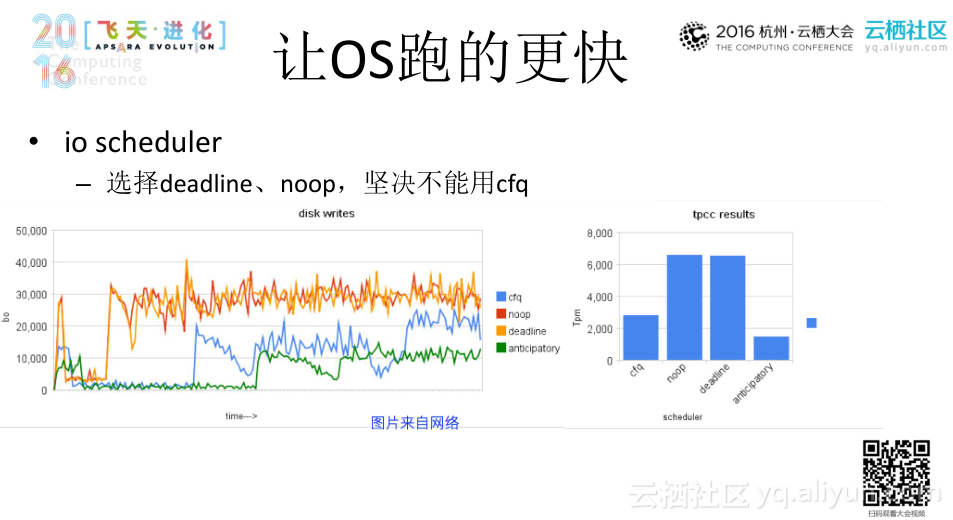
注:CFQ,即Completely Fair Queueing绝对公平调度器,力图为竞争块设备使用权的所有进程分配一个等同的时间片,在调度器分配给进程的时间片内,进程可以将其读写请求发送给底层块设备,当进程的时间片消耗完,进程的请求队列将被挂起,等待调度。相对于Noop和Deadline调度器,CFQ要复杂得多,因此可能要分几次才能将其分析完。
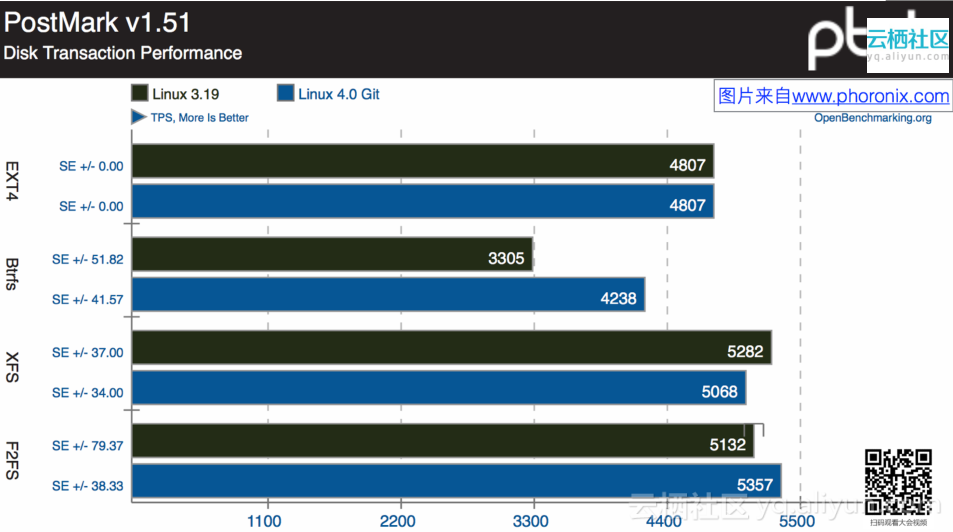
文件系统选择
- 优先选用xfs或ext4(rhel 7及以上,xfs已是默认fs)
- zfs/btrfs比较小众
- 坚决不用ext3
其他内核选项
- vm.dirty_ratio<=5
- vm.dirty_background_ratio<=10
- 避免因为io压力瞬间飙升导致内核进程卡死,os挂起
DDL,SQL写得好
(接下来就跟数据库有很大关系了,就看各位平时的数据库经验了)
一定要有主键(PRIMARY KEY)
如果没有主键的话,数据多次读写后可能更加离散,有更多随机IO。在MySql赋值环境中,如果选RBR模式,没有主键的update需要读全表,导致赋值延迟。好主键有以下特点:
- 没有业务用途
- 数值呈连续增长,最好是自增
- 坚决不能选用CHAR/UUID等类型
以上这些标注了红色的地方表示我还没有理解的,哪位朋友看了可以跟我解释一下。
关于数据长度
- 在够用的前提下,越短越好
- 消耗更少的储存空间
- 需要进行排序时候,消耗更少的内存空间
- 例如用INT UNSIGNED存储IPV4地址,不用CHAR(15)类型
- 实例:11个字符长度的数值,bigint vs char(11) vs char(11), 1w条记录,Logical_read: 111 vs 1170 vs 224
适当使用TEXT/BLOB类型
- data page默认16kb
- 每行长度超过8kb时候,就需要分裂data page
- 产生更多离散IO
- 案例:一个100G的表拆分成4个表后,总大小仅25G
每个表增加create_time update_time两个字段
- 分别表示写入时间以及最后更新时间
- 业务上可能用不到,但是对日常运维管理非常有用
- 可以用来判断那些事可以归档的老数据,定期进行归档
- 用来做自定义的差异备份也很方便
索引很重要
- InnoDB行锁基本是基于索引的实现
- 如果没有索引,后果将是灾难性的,读取时全表扫描,修改时全表记录锁。
索引设计
- 基数低的字段没必要建立单列索引
- 字符型字段上建立索引时候优先采用部分索引
- 优先多列联合索引,少用单列索引
什么是好的SQL
- 所有WHERE条件都加引号
- 避免潜在的隐士转换风险
- 避免个别条件失效时候的SQL语法错误
- 不用SELECT *
- 减少不必要的IO
- 提高可以利用覆盖索引的几率
- 避免SQL注入风险
- 所有用户输入值都要做过滤
- 利用PREPARE做预处理
- 利用SQL_MODE做限制
- LIKE查询时候不要用%通配符最左前导(无法使用索引)
- 能UNION ALL的时候就不要用UNION,因为UNION需要去重复,会产生临时表
- SQL中最好不要有预算
- WHERE子句中不要有函数
关于JOIN
- 满足业务需求前提下尽量用inner join,让优化器自动选择驱动表
- 有时候优化器选择的驱动表未必是最优的,可以尝试手动调整
- 最后的排序字段如果不在驱动表中,则会有filesort
关于EXPLAIN
- 关键业务SQL上线前,都要EXPLAIN确认其执行计划
- 或提前分析slow query log,防患于未然
- EXPLAIN中如果有Using temporary Using filesort 或 type=ALL时候,尽量想办法优化
运维习惯好
存储引擎
- 抛弃MyISAM, 拥抱InnoDB(这篇文章讲述了二者区别)
- 适当场景下可以使用TokuDB
- MEMORY不一定快
关闭QUERY CACHE
- 绝大多数情况下鸡肋,最好关闭
- QC锁是全局锁,每次更新QC的内存块锁代价高,出现wating for cache lock状态频率很高
- 实例启动前设置query_cache_type = 0 & query_cache_size =0 –
- 参考:http://t.cn/RAF4d7z http://t.cn/RAF4d7Z
使用独立undo表空间
- 避免ibdata1文件存储空间暴涨
- MySQL 5.6开始支持独立表空间
- MySQL 5.7还可以回收已经purge的表空间
- 提高file i/o能力,并适当增加purge线程数 innodb_purge_threads
- 事务及时提交,不要积压。并且默认打开autocommit = 1
启用thread pool
- 应对突发短连接
- extra port
没thread pool怎么办
- 想办法启用连接池或其他替代方案
- 适当调低超时阈值,减少空闲连接
几个关键选项
- innodb_buffer_pool_size,约物理内存的50% ~ 70%
- innodb_log_file_size,5.5及以上2G+,5.5以下建议不超512M
- innodb_flush_log_at_trx_commit,0=>最快数据最不安全,1=>最慢 最安全,2=>折中
- innodb_max_dirty_pages_pct,25%~50%为宜
- max_connections,突发最大连接数的80%为宜,过大容易导致全 部卡死
启用辅助监控机制
- 干掉超过N秒的SQL
- 干掉疑似注入SQL
- 干掉长时间不活跃的sleep连接
其他好习惯
DML(data manipulation language)是数据操纵语言:它们是SELECT、UPDATE、INSERT、DELETE,就象它的名字一样,这4条命令是用来对数据库里的数据进行操作的语言。
DDL(data definition language)是数据定义语言:DDL比DML要多,主要的命令有CREATE、ALTER、DROP等,DDL主要是用在定义或改变表(TABLE)的结构,数据类型,表之间的链接和约束等初始化工作上,他们大多在建立表时使用。
DCL(DataControlLanguage)是数据库控制语言:是用来设置或更改数据库用户或角色权限的语句,包括(grant,deny,revoke等)语句。
online ddl
- 优先用pt-osc
- 但不见得一定要用pt-osc
- 尤其是5.6以后对online ddl有了很大提升改善
删除大表
- 不要真的删除,而是先rename
- 确认对业务真的没有影响
- 再用硬连接的方法物理删除,效率更高
autocommit
- 避免某些行锁被长时间持有,影响tps
- 更严重时,可能连接数暴涨,导致整个实例挂掉
- 采用gui客户端连接时,记得及时关闭连接,或设置超时阈值以及 自动提交,否则容易发生行锁等待问题


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









