




一、依赖环境
jdk1.8
hadoop2.7.6
二、安装布骤
独立模式
解压hadoop目录如下
![]()
配置JAVA路径etc/hadoop/hadoop-env.sh
export JAVA_HOME=${JAVA_HOME}
变更为jdk HOME的路径
![]()
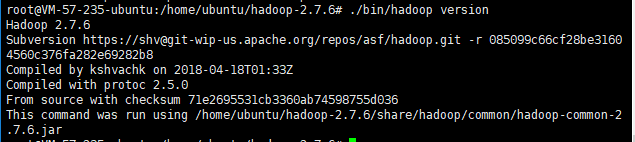
./bin/hadoop version 查看版本
执行一个简单的mapReduce任务
$ mkdir input $ cp etc/hadoop/*.xml input $ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar grep input output 'dfs[a-z.]+' $ cat output/*
伪分布式模式
/etc/hadoop/core-site.xml 配置如下
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
etc/hadoop/hdfs-site.xml 配置如下
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
配置ssh 免登录模式
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keys
初始化hdfs文件系统
./bin/hdfs namenode -format
启动hadoop
./sbin/start-dfs.sh
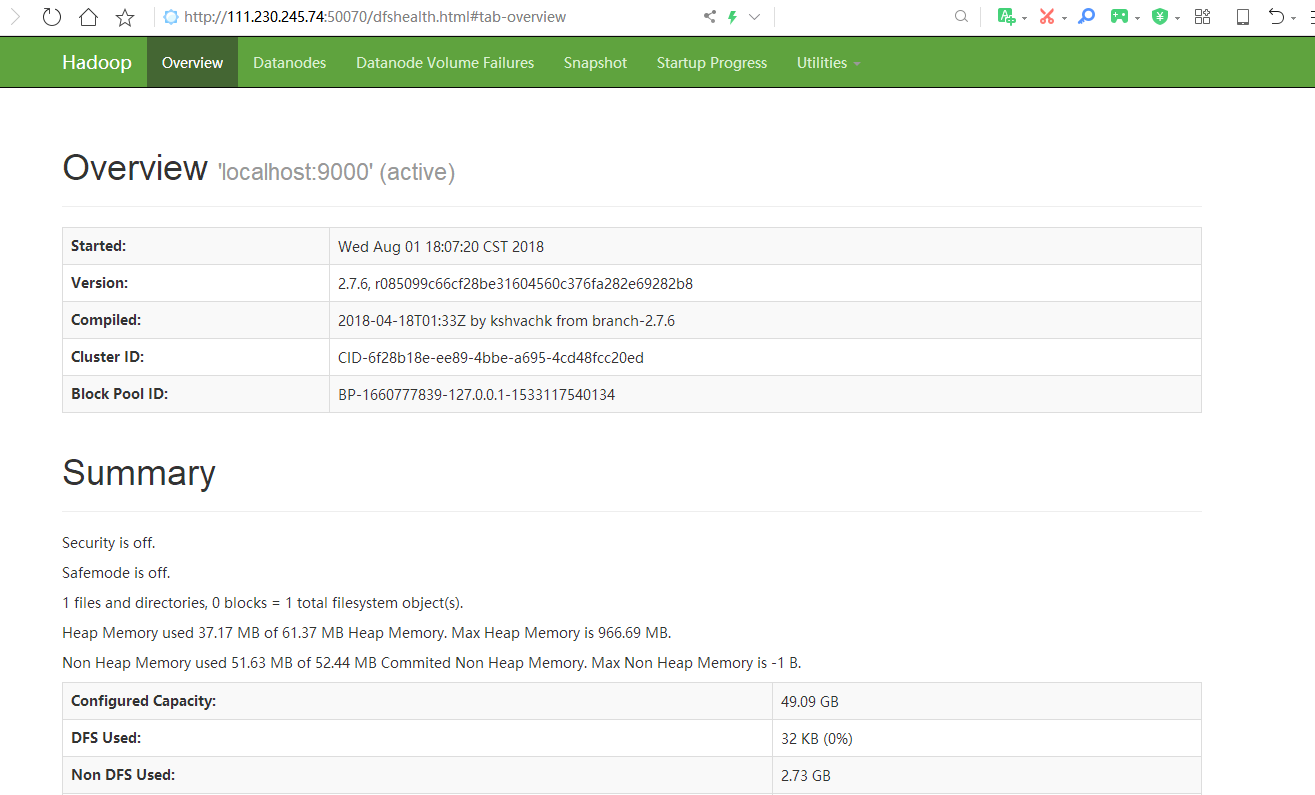
访问http://ip:50070,看到如下则部署成功
停止./sbin/stop-dfs.sh
YARN 单机模式
/etc/hadoop/mapred-site.xml 配置如下
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
/etc/hadoop/yarn-sitexml 配置如下
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
启动
sbin/start-yarn.sh
访问http://ip:8088
停止
sbin/stop-yarn.sh

















 3184
3184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









