



CB算法
基于内容的推荐。
用户喜欢电影: A ,现在有一部新电影B,怎么确定是否要推荐给用户。
1.对所有的电影进行特征建立和建模。特征就是电影的属性:比如名字,描述,类型,标签,主演等等
2.根据A的特征去筛选电影,如果B的得分很高,那么就可以推荐给此用户
应用场景
比如一个音乐网站,你点击一首歌,那么基于这首歌会推荐内容相关的其他歌曲给你。
CB与其他模块的关系
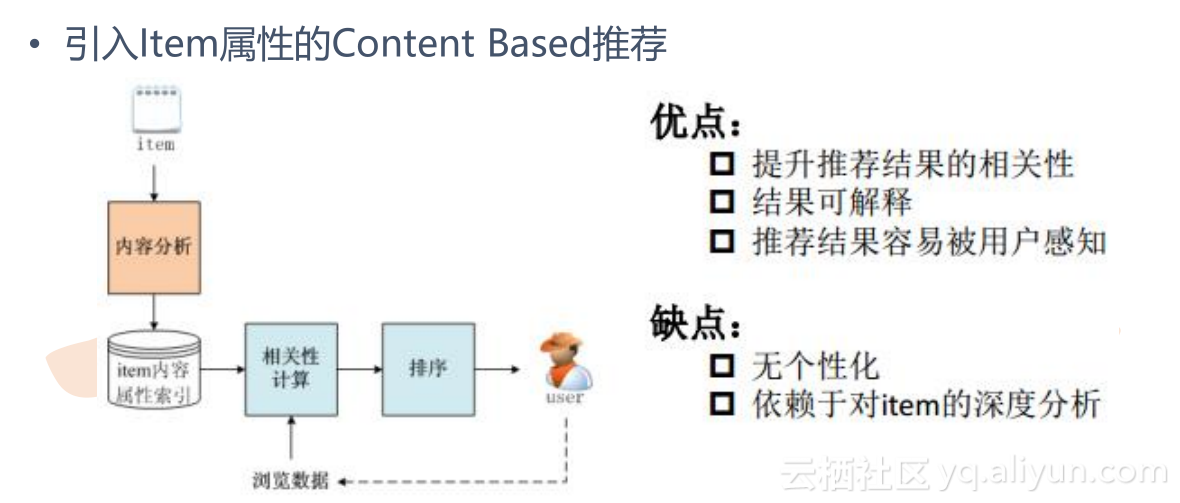
以音乐网站为例
item:音乐,音乐包含:ID,名字,描述,标签
内容分析:CB算法
item内容属性索引:CB分析的结果
相关性计算:根据用户点击的音乐,对检索出来的其他音乐,按照CB算法计算得分
排序:对计算得到的结果按得分从高到低排序,一般是取TOPN
流程:根据用户点击的音乐,检索出多个音乐,按相关性计算,排序,推荐给用户
CB算法demo
数据:
音乐id,音乐名
itemid itemName
为了是demo简单,只使用了音乐名字特征
建立倒排索引
源输入是:itemid itemName
目标输出是: tokenid itemid1:score1_itemid2:score2
tokenId:itemName的分词的id。
score:分词的得分
根据倒排索引可以得到词关联的itemId+score的列表,知道itemid也就知道了itemName了。
第一列是词的id,以\t分隔,第二列是itemId1:score1_itemId2:score2
分词
针对音乐名使用jieba分词,输出token:score,也就是词和得分。
注意:一个数量的词,jieba会忽略。
jieba已经提供了idf,所以我们只要计算音乐名的tf就行,得分=tdf*tf
之前有一个误区:以为tf的分子是样本的所有单词数,其实实际的是音乐名里面的词总数。
比如李逸朗《榕树》,词总数就是2,只有两个词:李逸朗、榕树
itemId:itemName -> itemId:itemName \t token1^Ascore1^Btoken2^Ascore2
token与score用^A分隔;item,score之间用^B分隔
967241243 李逸朗《榕树》 -> 967241243 李逸朗《榕树》 \t 李逸朗^A0.5^B榕树^A0.2^
967242243 李逸朗《水》 -> 967242243 李逸朗《水》 \t 李逸朗^A0.5^B水^A0.4^
转化
主要是为了存储方便,把中文分词转化为id
建立token2id(词:词id的映射);可以放入加入内存,数据量不大。
李逸朗 321
..........
榕树 498
水 499倒排
itemId:itemName -> itemId:itemName \t token1^Ascore1^Btoken2^Ascore2 转化成
tokenId1 \t itemId1:score1_itemId2:score2
967241243 李逸朗《榕树》 -> 967241243 李逸朗《榕树》 \t 李逸朗^A0.5^B榕树^A0.2^
967242243 李逸朗《水》 -> 967242243 李逸朗《水》 \t 李逸朗^A0.5^B水^A0.4^
转化得到
321 \t 967241243:0.5_967242243:0.4 #李逸朗498 \t 967241243:0.5 #榕树
499 \t 967242243:0.4 #水
使用倒排索引
有了倒排索引之后,那么就可以根据分词进行检索了
用户点击了一个首歌: 李逸朗《有心人》
对歌名进行分词tfidf得到:李逸朗:0.5 有心人:0.3
拿“李逸朗”检索倒排索引得到:《榕树》:0.5、《水》:0.4 等,那么《榕树》=0.5*0.5=0.25 《水》最终得分=04*0.5=0.2
分词“有心人”的过程和“李逸朗”一致。
得到的结果按分数从高到低排序,得到top2推荐
如果有不对之处,欢迎指正。

















 4341
4341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









