






 本文介绍了在统计模型中如何识别并处理强影响点的方法。主要通过Cook距离和变量添加图来检测那些对模型参数估计值有显著影响的数据点。Cook距离大于4/(n-k-1)的数据点被视为强影响点,而变量添加图则帮助评估这些点对模型的具体影响。
本文介绍了在统计模型中如何识别并处理强影响点的方法。主要通过Cook距离和变量添加图来检测那些对模型参数估计值有显著影响的数据点。Cook距离大于4/(n-k-1)的数据点被视为强影响点,而变量添加图则帮助评估这些点对模型的具体影响。

- 概念
强影响点,即对模型参数估计值影响有些比例失衡的点,比如移除某个点,会导致模型发生巨大的变化
- 如何检测
1、检测强影像点:Cook距离,或称 D统计量,以及变量添加图(added varialeplot),一般来说Cook'D值大于 4/(n-k-1),则表明它是强影响点,其中n为样本量大小,k是预测变量数目,可通过如下代码绘制Cook‘s图形
#绘制Cook's点检测强影响点
> cutoff <- 4/(nrow(states)-length(fit$coefficients)-2)
> plot(fit,which = 4,cook.levels = cufoff)
> abline(h=cutoff,lty=2,col="red")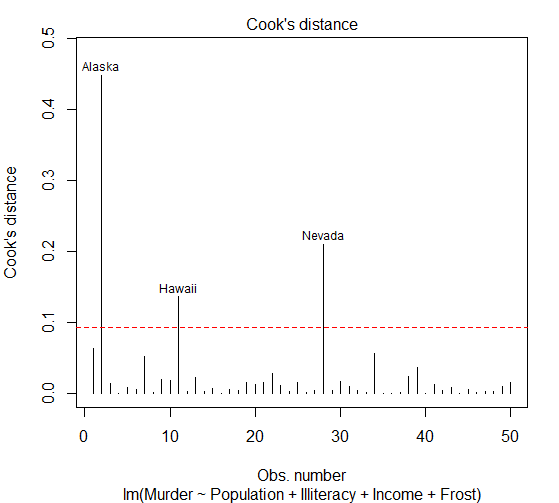
图中 Alsaka,Hawali,Nevada是强影响点,剔除会影响到回归模型的系数和截距项,注意虽然该图对搜寻最强点很有用,但我逐渐发现以 1 为分割点比 4/(n-k
-1)更具一般性。若设定 D =1 为判别标准,则数据集中没有看起来像是强影响点
- 添加变量图
Cook’s能鉴别强影响点,但是无法识别影响多少,而对于一个响应变量和k个预测变量,可以创建k个变量添加图,来观察对模型的影响
所谓变量添加图,即对每个预测变量Xk,绘制 Xk在其他 k-1 个预测变上回归的残差值相对于响应变量在其他 k-1 个预测变量上回归的残差值的关系图,car包中avPlot()函数可提供变量添加图
> library(car)
> avPlots(fit, ask=FALSE, id.method="identify")xxxxxxxxxx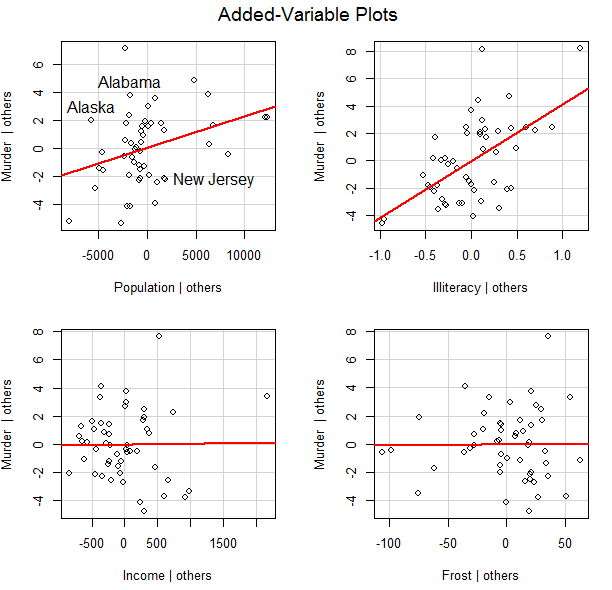

















 703
703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









