





由于开发一个人工智能项目,需要强大的后台数据库加持,所以,没有办法,又是需要医疗数据,只能自己爬某医疗网站数据,进行分析,但是由于不同网站的结构不一样,所以这个程序只能爬该网站的,第一次爬网页数据,自己写的底层分析处理源码,不能当做你们的爬数据工具,但是可以进行学习,毕竟是底层级别的,也很简单,放到这里,免费交流,免费下载源码,我放到GitHub上去了。
https://github.com/ChangeYD/changeMax
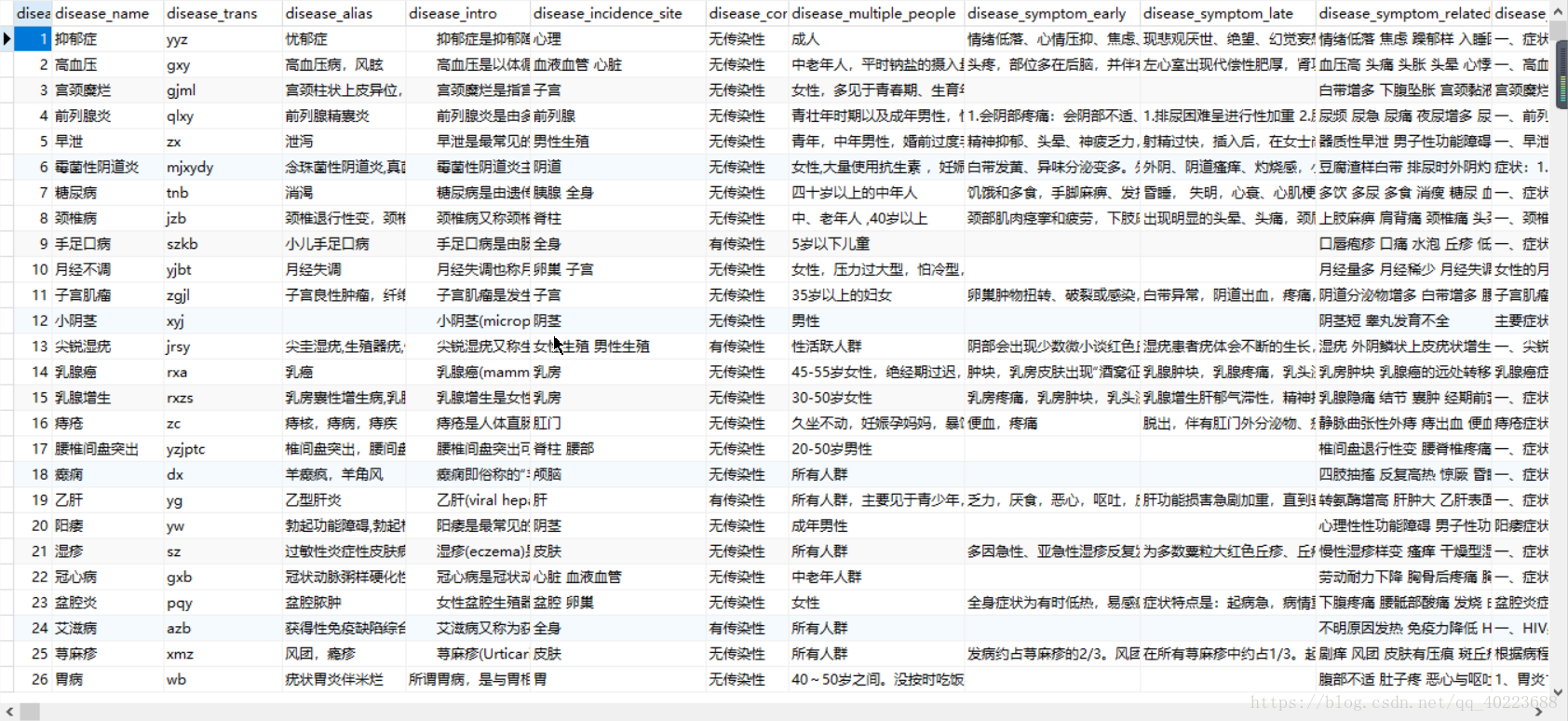
这是爬下来的数据,很多,我也分类了几张表。

 本文分享了作者首次爬取医疗网站数据的经验,包括编写底层分析处理源码的过程,并提供了 GitHub 下载链接供免费交流学习。
本文分享了作者首次爬取医疗网站数据的经验,包括编写底层分析处理源码的过程,并提供了 GitHub 下载链接供免费交流学习。
由于开发一个人工智能项目,需要强大的后台数据库加持,所以,没有办法,又是需要医疗数据,只能自己爬某医疗网站数据,进行分析,但是由于不同网站的结构不一样,所以这个程序只能爬该网站的,第一次爬网页数据,自己写的底层分析处理源码,不能当做你们的爬数据工具,但是可以进行学习,毕竟是底层级别的,也很简单,放到这里,免费交流,免费下载源码,我放到GitHub上去了。
https://github.com/ChangeYD/changeMax
这是爬下来的数据,很多,我也分类了几张表。
转载于:https://www.cnblogs.com/changemax/p/10015062.html

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























