






各位一定从未听说过“ISee搜索引擎”,因为今天刚刚诞生,况且还只是个模型。
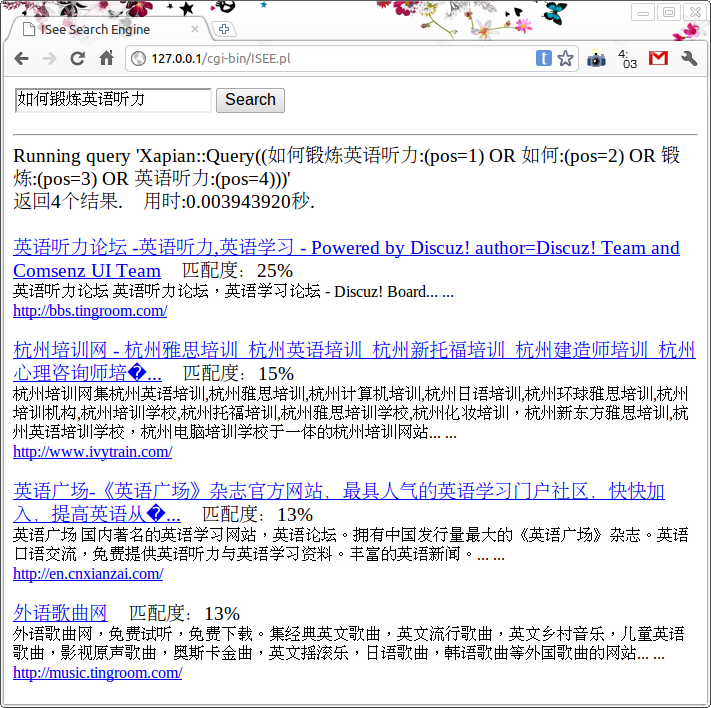
我是个很愿意分享的人,源代码奉上:
#!/usr/bin/perl
use CGI qw(:standard);
use Time::HiRes qw(time);
use Search::Xapian;
use Text::Scws;
print header("text/html;charset=utf-8");
print start_html(-title=>'ISee Search Engine');
print start_form,
textfield('terms'),
submit('Search'),
p,
end_form;
print hr;
if(param()){
$|=1; ##清空输出缓冲区
my $begin=time; ##开始计时
my $db = Search::Xapian::Database->new("/home/orisun/master/db1");
my $term=param('terms');
$scws = Text::Scws->new();
$scws->set_charset('utf-8');
$scws->set_dict('/usr/local/etc/dict.utf8.xdb');
$scws->set_rule('/usr/local/etc/rules.utf8.ini');
$scws->set_ignore(1);
$scws->set_multi(1);
$scws->send_text($term);
my @xifen=();
while($r=$scws->get_result()){
foreach(@$r){
$term.=" $_->{word}";
}
}
my $qp=new Search::Xapian::QueryParser($db);
$qp->set_stemmer(new Search::Xapian::Stem("english"));
#$qp->set_default_op(OP_OR); ##默认的就是OP_OR
my $enq = $db->enquire($qp->parse_query($term));
my @matches = $enq->matches(0, 100);
printf "Running query '%s'\n", $enq->get_query()->get_description();
print br;
print "返回",scalar(@matches), "个结果. ";
printf ("用时:%.9f秒.",time-$begin); ##结束计时
print br;
print br;
open (INDEXFH,"<index") or print "Open index file failed:$!.<br>";
foreach my $match ( @matches ) {
my $doc = $match->get_document();
my $fulldoc=$doc->get_data();
$fulldoc=~/^url=may21\/(.*)\s+sample=(.*)\s+caption=(.*)\s+type=(.*)\s+modtime=(.*)\s+size=(.*)/sx;
my ($filename,$doccontent,$webtitle,$webtype,$modifytime,$docsize)=($1,$2,$3,$4,$5,$6);
$filename=~/^f0*(\d+).html/;
my $num=$1;
my $hylink="";
seek(INDEXFH,0,0);
while(<INDEXFH>){
chomp;
$_=~s/^\s+\s+$//g;
my($no,$link)=split(' ',$_,2);
if($no==$num){
$hylink=$link;
last;
}
}
print a({-href=>$hylink,-target=>_blank},"$webtitle");
printf " 匹配度:%d%%<br>", $match->get_percent();
print small("$doccontent... ..."),"<br>";
print a({-href=>$hylink,-target=>_blank},small($hylink)),br;
print p;
}
close INDEXFH;
}
print end_html;


















 9572
9572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









