






原文:XQzip: Querying Compressed XML Using Structural Indexing
作者:James Cheng , Wilfred Ng
作者:James Cheng , Wilfred Ng
目 录
第一章 概述
XML的数据冗余
一、不可查询压缩:XMill
二、可查询压缩:XGrind、XPRESS
三、XQzip
第二章 XQzip结构
XQzip的结构分四部分:
压缩过程
查询过程
第三章 XML结构索引树(Structure Index Trees)
3.1 XML结构的基本概念
定义1 分支和分支排序
定义2 SIT等价(Sit-Equivalence)
定义3 合并运算(Merge Operator)
3.2 构造SIT
第四章 已压缩XML数据的可查询存储模型
第五章 用SIT查询已压缩XML
5.1 查询覆盖度
5.2 实施查询
解析查询
节点选取
获取数据与解压缩
查询结果输出
XML的数据冗余
一、不可查询压缩:XMill
二、可查询压缩:XGrind、XPRESS
三、XQzip
第二章 XQzip结构
XQzip的结构分四部分:
压缩过程
查询过程
第三章 XML结构索引树(Structure Index Trees)
3.1 XML结构的基本概念
定义1 分支和分支排序
定义2 SIT等价(Sit-Equivalence)
定义3 合并运算(Merge Operator)
3.2 构造SIT
第四章 已压缩XML数据的可查询存储模型
第五章 用SIT查询已压缩XML
5.1 查询覆盖度
5.2 实施查询
解析查询
节点选取
获取数据与解压缩
查询结果输出
第一章 概述
XML的数据冗余:
原因:使用重复的标记描述数据。
后果:阻碍(hinder)了XML数据交换(data exehange)和数据存档(data archiving)上的应用。
近几年解决xml数据冗余问题的方案可归为两类:
1、可查询压缩
2、非可查询压缩
原因:使用重复的标记描述数据。
后果:阻碍(hinder)了XML数据交换(data exehange)和数据存档(data archiving)上的应用。
近几年解决xml数据冗余问题的方案可归为两类:
1、可查询压缩
2、非可查询压缩
一、不可查询压缩:XMill
整块数据必须先被整体解压后再进行查询。
二、可查询压缩:XGrind、XPRESS
1、独立编码各数据项,使已压缩数据项可以直接存取,而不需把文件全部解压缩。
2、与全块压缩的方案相比,压缩率有所降低。
A、XGrind、XPRESS采用的是同型变换(homomorphic transformation),保留了XML数据的结构信息,因此可在此结构上进行查询。
缺点:所保留的结构通常太大(与xml文档的大小呈线性关系),搜索这么大的结构空间效率太低,即使是简单的路径查询。
例如:在图1的文档中搜索初始价格<initial>项低于$10的拍卖项<bid>。XGrind解析整个xml压缩文档,对解析的每一个元素/属性,将其路径与输入的查询的路径进行匹配,。XPRESS作了改进,它将逐元素的匹配改为逐路径的匹配(具体方法还不清楚)。逐路径的匹配仍然是低效的,因为xml文档中大部分路径是重复的。
2、与全块压缩的方案相比,压缩率有所降低。
A、XGrind、XPRESS采用的是同型变换(homomorphic transformation),保留了XML数据的结构信息,因此可在此结构上进行查询。
缺点:所保留的结构通常太大(与xml文档的大小呈线性关系),搜索这么大的结构空间效率太低,即使是简单的路径查询。
例如:在图1的文档中搜索初始价格<initial>项低于$10的拍卖项<bid>。XGrind解析整个xml压缩文档,对解析的每一个元素/属性,将其路径与输入的查询的路径进行匹配,。XPRESS作了改进,它将逐元素的匹配改为逐路径的匹配(具体方法还不清楚)。逐路径的匹配仍然是低效的,因为xml文档中大部分路径是重复的。
<site>
<open_auctions>
<open_auction id="open1">
<initial>$12.00</initial>
<bid>
<date>12/02/2000</date>
<increase>$2.00</increase>
</bid>
<bid>
<date>12/03/2000</date>
<increase>$1.50</increase>
</bid>
<seller person="person71"/>
</open_auction>
<open_auction id="open2">
<initial>$500.00</initial>
<seller person="person8"/>
</open_auction>
<open_auction id="open3">
<initial>$1.50</initial>
<bid>
<date>11/29/2002</date>
<increase>$0.50</increase>
</bid>
<seller person="person15"/>
</open_auction>
<open_auction id="open4">
<initial>$100.00</initial>
<seller person="person11"/>
</open_auction>
<open_auction id="open5">
<initial>$8.50</initial>
<bid>
<date>08/20/2002</date>
<increase>$5.00</increase>
</bid>
<seller person="person7"/>
</open_auction>
</open_auctions>
</site>
<open_auctions>
<open_auction id="open1">
<initial>$12.00</initial>
<bid>
<date>12/02/2000</date>
<increase>$2.00</increase>
</bid>
<bid>
<date>12/03/2000</date>
<increase>$1.50</increase>
</bid>
<seller person="person71"/>
</open_auction>
<open_auction id="open2">
<initial>$500.00</initial>
<seller person="person8"/>
</open_auction>
<open_auction id="open3">
<initial>$1.50</initial>
<bid>
<date>11/29/2002</date>
<increase>$0.50</increase>
</bid>
<seller person="person15"/>
</open_auction>
<open_auction id="open4">
<initial>$100.00</initial>
<seller person="person11"/>
</open_auction>
<open_auction id="open5">
<initial>$8.50</initial>
<bid>
<date>08/20/2002</date>
<increase>$5.00</increase>
</bid>
<seller person="person7"/>
</open_auction>
</open_auctions>
</site>
图1 A Sample Auction XML Extract
三、XQzip的特点:
1. 支持对压缩文件的查询(采用结构索引树SIT)
2. 针对目前XML压缩算法中存在的压缩和查询性能的问题
3. 广泛支持XPath查询:如多重、深度内嵌的谓词及其集合
1. 支持对压缩文件的查询(采用结构索引树SIT)
2. 针对目前XML压缩算法中存在的压缩和查询性能的问题
3. 广泛支持XPath查询:如多重、深度内嵌的谓词及其集合
第二章 XQzip结构
XQzip的结构分四部分:
1、压缩模块the Compressor
2、索引构造模块the Index Constructor
3、查询处理模块 the Query Processor
4、存储区the Repository
1、压缩模块the Compressor
2、索引构造模块the Index Constructor
3、查询处理模块 the Query Processor
4、存储区the Repository
压缩过程
这里提到的“数据”和“结构”的区别:这里提到的数据包括XML文档中的元素内容和属性值;结构包括XML文档中的标记名和属性名。
输入的XML文档被SAX解析器解析(SAX解析器的功能是把XML数据项(包括元素内容和属性值)分发给压缩模块,把XML结构信息(包括标记名和属性名)分发给索引构建模块)。压缩模块将数据压缩成块,这些块能通过哈希表高效存取,其中哈希表中存储着元素名/属性名。
索引构建模块为xml结构创建SIT。
输入的XML文档被SAX解析器解析(SAX解析器的功能是把XML数据项(包括元素内容和属性值)分发给压缩模块,把XML结构信息(包括标记名和属性名)分发给索引构建模块)。压缩模块将数据压缩成块,这些块能通过哈希表高效存取,其中哈希表中存储着元素名/属性名。
索引构建模块为xml结构创建SIT。
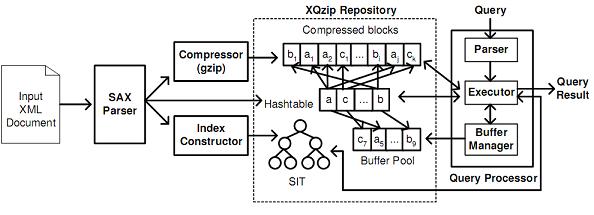
图4 XQzip系统结构
查询过程
对于查询过程,查询解析器(Query Parser)解析一个输入的查询,接着查询执行模块(Query Executor)利用索引(index)进行查询。Executor与缓存管理(Buffer Manager)协调工作,其中缓存管理应用LRU算法(最近最少使用算法)管理保存已解压数据块的缓冲池。若数据已经在缓冲池中,Executor直接将其取出而不用从压缩文件中解压;否则,Executor与哈希表通信,从压缩文件中取出数据。
对于查询过程,查询解析器(Query Parser)解析一个输入的查询,接着查询执行模块(Query Executor)利用索引(index)进行查询。Executor与缓存管理(Buffer Manager)协调工作,其中缓存管理应用LRU算法(最近最少使用算法)管理保存已解压数据块的缓冲池。若数据已经在缓冲池中,Executor直接将其取出而不用从压缩文件中解压;否则,Executor与哈希表通信,从压缩文件中取出数据。
第三章 XML结构索引树(Structure Index Trees)
结构索引树(STI)是一种高效的索引结构,这里先定义描述SIT用到的一些术语,然后介绍一个生成SIT的算法。
3.1 XML结构的基本概念
一个XML文档的结构可以模拟为一棵树,称为结构树。结构树包含一个根节点和若干元素节点。元素节点既可表示元素也可表示属性。这里在属性名前加前缀“@”来和元素名进行区分。
算法中为每个特定的“标记/属性”名指派一个Hash ID,存入哈希表,例如图4所示的哈希表。数据项则从结构中分离出来压缩成不同的块,这些块可以通过哈希表存取。因此这个模型中没有要考虑的文本节点。同时也不考虑名字空间,PI和注释,尽管包含这些只需要简单的扩展。
算法中为每个特定的“标记/属性”名指派一个Hash ID,存入哈希表,例如图4所示的哈希表。数据项则从结构中分离出来压缩成不同的块,这些块可以通过哈希表存取。因此这个模型中没有要考虑的文本节点。同时也不考虑名字空间,PI和注释,尽管包含这些只需要简单的扩展。


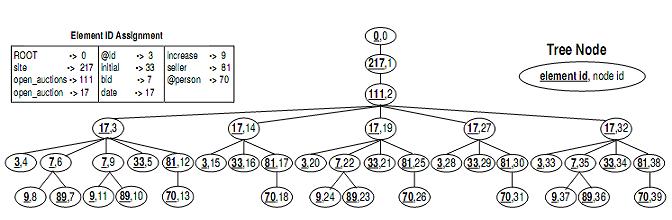
图2 图1的结构树
而图3中的树表示为
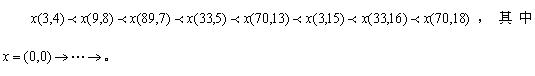
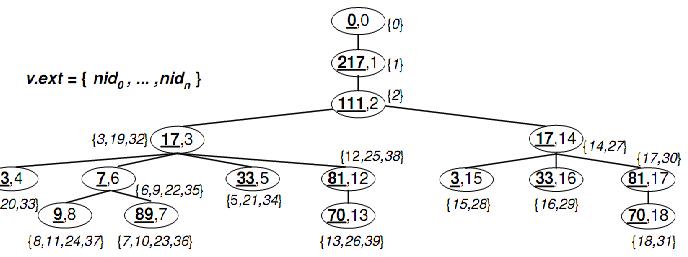
图3 图2结构树的SIT
定义2 SIT等价(Sit-Equivalence)
1、分支等价

2、子树等价

定义3 合并运算(Merge Operator)

因此,合并运算将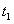 和
和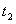 合并生成t,t和和是SIT等效的。合并运算的结果是完全相同的SIT等价结构被删除了。通过消除子树结构的这种冗余得到一个更简练的结构表示——结构索引树(SIT)。通过对结构树反复应用
合并生成t,t和和是SIT等效的。合并运算的结果是完全相同的SIT等价结构被删除了。通过消除子树结构的这种冗余得到一个更简练的结构表示——结构索引树(SIT)。通过对结构树反复应用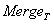 ,直到无任何两个SIT等价的子树剩下。例如,图3中的树是图2中结构树的SIT,注意到图2中所有SIT等价的子树都合并到图3的SIT中一个相应的SIT等价的子树中。
,直到无任何两个SIT等价的子树剩下。例如,图3中的树是图2中结构树的SIT,注意到图2中所有SIT等价的子树都合并到图3的SIT中一个相应的SIT等价的子树中。
一个结构树和它的SIT是等价的,因为被删除的SIT等价的子树的结构保留在SIT中。另外,删除的节点由保存在节点 exts 中的它们的节点标识 nid 来表示,而删除的边可随着节点次序重建。由于SIT通常比其结构树更小,因此能进行比其结构树更高效的节点选定。
和合并生成t,t和和是SIT等效的。合并运算的结果是完全相同的SIT等价结构被删除了。通过消除子树结构的这种冗余得到一个更简练的结构表示——结构索引树(SIT)。通过对结构树反复应用,直到无任何两个SIT等价的子树剩下。例如,图3中的树是图2中结构树的SIT,注意到图2中所有SIT等价的子树都合并到图3的SIT中一个相应的SIT等价的子树中。一个结构树和它的SIT是等价的,因为被删除的SIT等价的子树的结构保留在SIT中。另外,删除的节点由保存在节点 exts 中的它们的节点标识 nid 来表示,而删除的边可随着节点次序重建。由于SIT通常比其结构树更小,因此能进行比其结构树更高效的节点选定。
3.2 构造SIT
本节介绍一种构建XML文档SIT的高效算法。首先为每个树节点定义四个节点指针:parent,previousSibling,nextSibling,firstChild。指针很大程度上加速了SIT构造和查询操作中节点的定位(navigation)。指针占用的空间并不重要,因为一个SIT通常很小。
SIT构造过程:
SAX仅线性扫描输入的XML文档一次,建立其SIT,同时压缩文本数据。
对解析的每个SAX开始/结束标记事件,调用SIT构造程序,如图5所示。其主要思想是对“基(base)树”和“构造中的树”的操作。“构造中的树”是指正在为每个被解析的开始标记构造的树,它是“基”树的子树。当解析到一个结束标记时,一个“构造中的树”就完成了。若该完成的子树和“基”树中的任一子树是SIT等价的,它就被合并到该SIT等价的子树中;否则,它就成为“基”树的一部分。我们用一个堆栈来指示先前和当前XML元素的父子或兄弟关系,建立树结构。程序伪代码的11-20行保持了结构信息的连贯性并跳过冗余信息。因此,栈的大小通常小于SIT高度的两倍。
SAX仅线性扫描输入的XML文档一次,建立其SIT,同时压缩文本数据。
对解析的每个SAX开始/结束标记事件,调用SIT构造程序,如图5所示。其主要思想是对“基(base)树”和“构造中的树”的操作。“构造中的树”是指正在为每个被解析的开始标记构造的树,它是“基”树的子树。当解析到一个结束标记时,一个“构造中的树”就完成了。若该完成的子树和“基”树中的任一子树是SIT等价的,它就被合并到该SIT等价的子树中;否则,它就成为“基”树的一部分。我们用一个堆栈来指示先前和当前XML元素的父子或兄弟关系,建立树结构。程序伪代码的11-20行保持了结构信息的连贯性并跳过冗余信息。因此,栈的大小通常小于SIT高度的两倍。
 procedure construct_SIT (SAX-Event) /*stack is an array keeping the start/end tag information (either START-TAG or END-TAG); top indicates the stack top; c is the current node pointer; count initially is set to 0 */ begin if (SAX-Event is a start-tag event) /*an attribute is also a start-tag event*/ create a new node,u,where u.eid:=hash(SAX-Event) and count:=count+1,u.nid:=count; if (stack[top]=START-TAG) assign u as the firstchild of c; /*若栈顶为开始标记,说明当前SAX事件的开始标记为栈顶标记所在元素(因为栈顶的开始标记可能是一属性)的属性或子元素*/ else insert u among the siblings of c according to the SIT node ordering; top:=top+1; stack[top]:=START-TAG; /*开始、结束标记都要入栈*/ else if (SAX-Event is an end-tag event) /*an end-tag event is also passed after processing an attribute value*/ /* 存在空元素的情况:<element iq=”...” /> */ if (subtree(c) is SIT-equivalent to subtree(one of c’s siblings,u)) /*by a parallel DFS*/ (subtree(u),subtree(c)); if (stack[top]=START-TAG) /*c has no child and the START-TAG was pushed for c*/ if (stack[top-1])=START-TAG /*c is the first child of its parent*/ stack[top]:=END-TAG; /*finish processing c*/ else /*c has preceding sibling(s) (processed)*/ top:=top-1; /*use the previous END-TAG to indicate c has been processed*/ /*处理完成后,c出栈*/ else /*the END-TAG indicates c’s child processed,stack[top-1] must be START-TAG indicating c not processed*/ /* 栈顶为END-TAG */ if (stack[top-2]=START-TAG) /*c is the first child of its parent*/ top:=top-1;stack[top]:=END-TAG; /*remove c’s child’s stack and indicates c has been processed(c已处理完毕)*/ else /*为END-TAG,说明c前边的兄弟曾完成处理*/ /*c’s preceding sibling(s) processed*/ top:=top-2; /*use c’s preceding sibling’s END-TAG, i.e. stack[top-2],to indicate c has been processed*/ c:=u; /* u成为当前处理元素 */ end
procedure construct_SIT (SAX-Event) /*stack is an array keeping the start/end tag information (either START-TAG or END-TAG); top indicates the stack top; c is the current node pointer; count initially is set to 0 */ begin if (SAX-Event is a start-tag event) /*an attribute is also a start-tag event*/ create a new node,u,where u.eid:=hash(SAX-Event) and count:=count+1,u.nid:=count; if (stack[top]=START-TAG) assign u as the firstchild of c; /*若栈顶为开始标记,说明当前SAX事件的开始标记为栈顶标记所在元素(因为栈顶的开始标记可能是一属性)的属性或子元素*/ else insert u among the siblings of c according to the SIT node ordering; top:=top+1; stack[top]:=START-TAG; /*开始、结束标记都要入栈*/ else if (SAX-Event is an end-tag event) /*an end-tag event is also passed after processing an attribute value*/ /* 存在空元素的情况:<element iq=”...” /> */ if (subtree(c) is SIT-equivalent to subtree(one of c’s siblings,u)) /*by a parallel DFS*/ (subtree(u),subtree(c)); if (stack[top]=START-TAG) /*c has no child and the START-TAG was pushed for c*/ if (stack[top-1])=START-TAG /*c is the first child of its parent*/ stack[top]:=END-TAG; /*finish processing c*/ else /*c has preceding sibling(s) (processed)*/ top:=top-1; /*use the previous END-TAG to indicate c has been processed*/ /*处理完成后,c出栈*/ else /*the END-TAG indicates c’s child processed,stack[top-1] must be START-TAG indicating c not processed*/ /* 栈顶为END-TAG */ if (stack[top-2]=START-TAG) /*c is the first child of its parent*/ top:=top-1;stack[top]:=END-TAG; /*remove c’s child’s stack and indicates c has been processed(c已处理完毕)*/ else /*为END-TAG,说明c前边的兄弟曾完成处理*/ /*c’s preceding sibling(s) processed*/ top:=top-2; /*use c’s preceding sibling’s END-TAG, i.e. stack[top-2],to indicate c has been processed*/ c:=u; /* u成为当前处理元素 */ end 图5 SIT构建程序伪代码
<?xml:namespace prefix = o ns = "urn:schemas-microsoft-com:office:office" />
转载于:https://blog.51cto.com/qiyanfeng/105578


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









