






 本文介绍了一个简单的Python爬虫项目,用于抓取豆瓣电影Top250榜单中的电影名称。通过分析网页结构并利用requests和BeautifulSoup库,实现了对目标网页的有效解析。该教程适合初学者实践网络爬虫技术。
本文介绍了一个简单的Python爬虫项目,用于抓取豆瓣电影Top250榜单中的电影名称。通过分析网页结构并利用requests和BeautifulSoup库,实现了对目标网页的有效解析。该教程适合初学者实践网络爬虫技术。
利用python2.7抓取豆瓣电影top250
1.任务说明
- 抓取top100电影名称
- 依次打印输出
2.网页解析
- 要进行网络爬虫,利用工具(如浏览器)查看网页HTML文件的相关内容是很有必要,我使用的是Firefox浏览器,并安装了Firebug插件,
这个插件可以方便查看包括HTML在内许多内容
打开豆瓣电影排行榜top250网页,发现每页有25部电影,一共10页,其每一页url具有如下特征:
......
以此类推因此只需要利用循环对后面的0,25,...225处理即可。
- 网页点击任何一个电影中文名,右击鼠标“查看元素”查看HTML源代码:
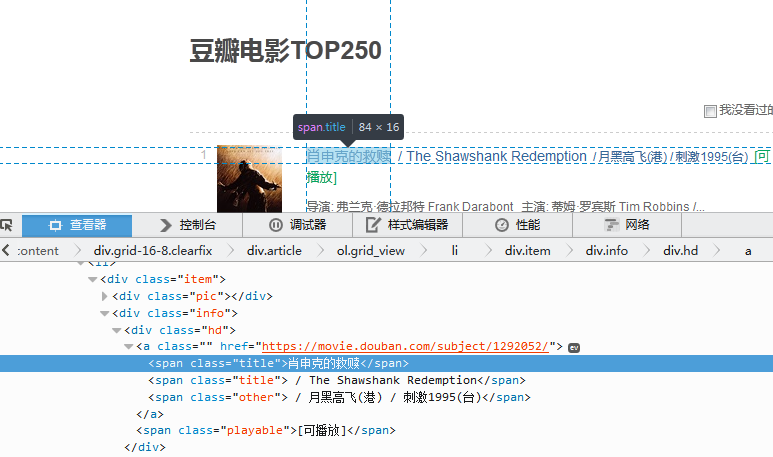
可以发现电影名称放在<span class="title"> </span>中,同时英文名也放在<span class="title"> </span>中。
可以利用正则表达式<span class="title">(.*)</span>匹配电影的中文名和英文名,但这里只想得到中文名,所以需要过滤英文名。
过滤方法可以利用find(str,pos_start,pos_end)函数实现,剔除英文名字里特有的特征:‘ ’和‘/’,详见代码。
3.代码实现
这里代码比较简单,因此就不用定义函数了。
1 #!/usr/bin/python 2 # -*- coding: utf-8 -*- # 3 import requests,sys,re 4 from bs4 import BeautifulSoup 5 6 reload(sys) 7 sys.setdefaultencoding('utf-8') 8 print '正在从豆瓣电影Top250抓取数据......' 9 10 for page in range(10): 11 url='https://movie.douban.com/top250?start='+str((page-1)*25) 12 print '---------------------------正在爬取第'+str(page+1)+'页......--------------------------------' 13 html=requests.get(url) 14 html.raise_for_status() 15 try: 16 soup=BeautifulSoup(html.text,'html.parser') 17 soup=str(soup) # 利用正则表达式需要将网页文本转换成字符串 18 title=re.compile(r'<span class="title">(.*)</span>') 19 names=re.findall(title,soup) 20 for name in names: 21 if name.find('/')==-1: # 剔除英文名(英文名特征是含有'/') 22 print name 23 except Exception as e: 24 print e 25 print '爬取完毕!'
由于水平有限,难免存在不足,欢迎大家斧正!

















 917
917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









