




 本文详细介绍了大数据Benchmark,包括Hibench、Berkeley BigDataBench、Hadoop GridMix、Bigbench以及BigDataBenchmark等,涵盖了数据类型、工作负载和度量指标等方面,旨在评估和优化大数据系统性能。
本文详细介绍了大数据Benchmark,包括Hibench、Berkeley BigDataBench、Hadoop GridMix、Bigbench以及BigDataBenchmark等,涵盖了数据类型、工作负载和度量指标等方面,旨在评估和优化大数据系统性能。

Benchmark在计算机领域应用最成功的就是性能测试,主要测试负载的执行时间、传输速度、吞吐量、资源占用率等。
数据库领域,TPC的Bench已经成为开发数据库的主流Benchmark。开发者在开发的过程中,利用Benchmark生成结构化的数据,同时利用查询生成器生成指定数据库的SQL方言。这样在开发的数据库或
者改进的算法上用SQL负载(Workload)进行测试,就能够更加精准地了解性能瓶颈,对系统进行调优。
有些Benchmark只适用于某些领域。例如,TPC针对数据仓库开发了TPC-DS Benchmark,而针对其他的数据库又有TPC-H等系列的Benchmark。
用大数据领域Benchmark标准尚未统一。下面是几种著名的大数据benchmark
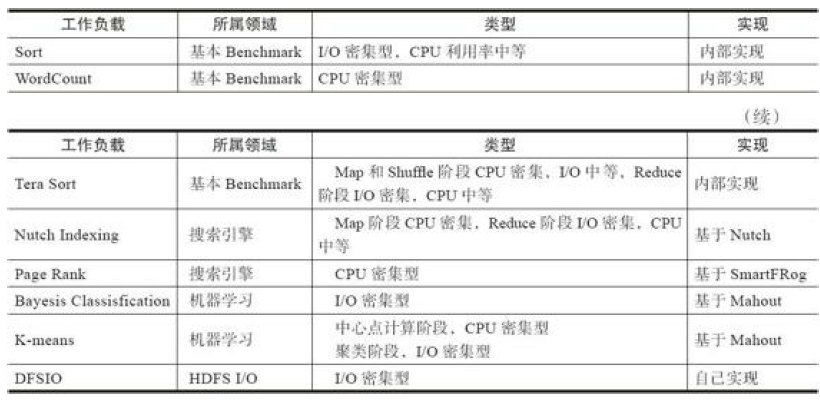
Hibench
Hibench是由Intel开发的一个针对Hadoop的基准测试工具。它包含有一组Hadoop工作负载的集合,有人工模拟实验环境的工作负载,也有一部分是生产环境的Hadoop应用程序。
包含负载如下:
Berkeley BigDataBench
是随着Spark、Shark的推出,由AMPLab开发的一套大数据基准测试工具。其一部分是基于Hibench的数据集和数据生成器。同时它有一部分数据集是Common Crawl上采样的文档数据集。
目前主要针对SQL on Hadoop产品进行基准测试。
现在支持Documents、Ranking和UserVisits 3个数据集。
工作负载包括:
(1)Scan Query
查询的目的是对关系表进行选择和投影操作。
(2)Aggregation Query
查询的目的是先对关系表分组,然后使用字符串解析的函数对每个元组进行解析最后进行一个高基数的聚集函数操作
(3)Join Query
查询使用大小表连接,然后对结果进行排序。因为很多SQL on Hadoop产品都是基于Map Reduce计算模型,所以这里涉及一个经典的优化方式是Map Side Join,可以避免Shuffle阶段的网络开销
(4)External Script Query
调用一个会抽取和聚集URL信息的Python外部函数,然后分组聚集整个URL的数量
Hadoop GridMix
Hadoop自带的Benchmark,Gridmix同样不支持Spark,用户要使用Spark,仍需自己实现Workload算法
Gridmix的使用用例不能代表所有的Hadoop使用场景。Gridmix的用例中,没有包括较为复杂的计算,也没有明显的CPU密集型的用例。而现实应用中,存在很多I/O密集型的应用,同时CPU密集型的应用也大量存在,如机器学习算法、构建倒排索引等。因此,Gridmix的WorkLoad负载并不能完全展现大数据工作负载的全貌
包含负载如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 823
823

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









