



 本文介绍了一种使用KNN算法进行文本分类的方法,包括Java和C++两种实现方式的对比,详细展示了算法流程及分类效果。
本文介绍了一种使用KNN算法进行文本分类的方法,包括Java和C++两种实现方式的对比,详细展示了算法流程及分类效果。
先是写了个Java版本,由于运行时间太长,后来写了个C++版本,虽然时间缩短了,但还是得数小时。
Java版:

 View Code
View Code
1 /**
2 * Author: Orisun
3 * Date: Oct 10, 2011
4 * FileName: KNN.java
5 * Function: 对于一个unseen文档,计算它与所有训练文档的向量夹角,根据KNN决定它以至于哪一类
6 */
7
8 import java.io.BufferedReader;
9 import java.io.File;
10 import java.io.FileNotFoundException;
11 import java.io.FileOutputStream;
12 import java.io.FileReader;
13 import java.io.IOException;
14 import java.io.PrintWriter;
15 import java.util.ArrayList;
16 import java.util.Comparator;
17 import java.util.Date;
18 import java.util.HashMap;
19 import java.util.Iterator;
20 import java.util.Map;
21 import java.util.PriorityQueue;
22 import java.util.Vector;
23 import java.util.Map.Entry;
24
25 import com.sleepycat.je.DatabaseException;
26
27 public class KNN extends AbstractBDB {
28
29 final int K=15; //KNN中的K
30 final int veclen=1000; //文档向量的维数
31 final int catnum=9; //一共有9大分类
32 final int tdocnum=7196; //训练文本的总数
33 final int adocnum=7193; //测试文档的总数
34 String[] classes={"C39","C7","C3","C32","C31","C38","C34","C11","C19"};
35 int[] tnumperclass={1070,440,513,816,750,756,1392,473,986}; //训练集每一类的文档数目
36 int[] anumperclass={1066,447,508,822,741,758,1404,463,984}; //测试集每一类的文档数目
37
38 // 优先馺队列存储与test文档夹角最大的K个文档名
39 PriorityQueue<Entry<String, Double>> pq;
40 // 存储test文档的向量
41 ArrayList<Double> v = new ArrayList<Double>(veclen);
42 int[][] decide; // 记录每个分类判断正确和错误的次数
43
44 public KNN(String homeDirectory) throws DatabaseException,
45 FileNotFoundException {
46 super(homeDirectory);
47 pq = new PriorityQueue<Entry<String, Double>>(K,
48 new Comparator<Map.Entry<String, Double>>() {
49 public int compare(Entry<String, Double> arg0,
50 Entry<String, Double> arg1) {
51 return arg0.getValue().compareTo(arg1.getValue());
52 }
53 });
54 decide = new int[catnum][];
55 for (int i = 0; i < catnum; i++) {
56 decide[i] = new int[2];
57 }
58 for(int i=0;i<veclen;i++)
59 v.add(0.0);
60 }
61 public void initV(){
62 for(int i=0;i<veclen;i++)
63 v.set(i, 0.0);
64 }
65 // 计算两个向量的夹角的余弦。如果此值的绝对值越大,说明夹角越小,越相似,距离越近。
66 public double cos(ArrayList<Double> v1, Vector<Double> v2, int len) {
67 double res = 0.0;
68 double mul = 0.0;
69 double p1 = 0.0, p2 = 0.0;
70 for (int i = 0; i < len; i++) {
71 double one = v1.get(i);
72 double two = v2.get(i);
73 mul += one * two;
74 p1 += Math.pow(one, 2);
75 p2 += Math.pow(two, 2);
76 }
77 res = Math.abs(mul) / Math.sqrt(p1 * p2);
78 return res;
79 }
80
81 // 填充优先级队列
82 public void fillQueue() {
83 pq.clear();
84 int i = 0;
85 for (; i < K; i++) {
86 Vector<Double> v1 = VectorDB.get(String.valueOf(i));//测试集的文档向量所在的数据库名叫VectorDB
87 double arc = cos(v, v1, veclen);
88 HashMap<String, Double> map = new HashMap<String, Double>();
89 map.put(String.valueOf(i), arc);
90 Iterator<Entry<String, Double>> iter = map.entrySet().iterator();
91 pq.add(iter.next());
92 }
93 for (; i < tdocnum; i++) {
94 Vector<Double> v1 = VectorDB.get(String.valueOf(i));
95 double arc = cos(v, v1, veclen);
96 if (arc > pq.peek().getValue()) {
97 pq.poll();
98 HashMap<String, Double> map = new HashMap<String, Double>();
99 map.put(String.valueOf(i), arc);
100 Iterator<Entry<String, Double>> iter = map.entrySet()
101 .iterator();
102 pq.add(iter.next());
103 }
104 }
105 // System.out.println("i="+i);
106 }
107
108 // 判断类别
109 public void classify(String testFileName) {
110 double[] arr = new double[catnum];
111 while (pq.size() > 0) {
112 String docName = pq.poll().getKey();
113 //System.out.println(docName);
114 int filerank = Integer.parseInt(docName);
115 if(filerank>=4345 && filerank<=5736) //C34
116 arr[6]++;
117 else if(filerank>=0 && filerank<=1069) //C39
118 arr[0]++;
119 else if(filerank>=6210 && filerank<=7195) //C19
120 arr[8]++;
121 else if(filerank>=2023 && filerank<=2838) //C32
122 arr[3]++;
123 else if(filerank>=3589 && filerank<=4344) //C38
124 arr[5]++;
125 else if(filerank>=2839 && filerank<=3588) //C31
126 arr[4]++;
127 else if(filerank>=1510 && filerank<=2022) //C3
128 arr[2]++;
129 else if(filerank>=5737 && filerank<=6209) //C11
130 arr[7]++;
131 else if(filerank>=1070 && filerank<=1509) //C7
132 arr[1]++;
133 }
134 //由于文档集倾斜,所以要按比例公平对待
135 for(int i=0;i<catnum;i++)
136 arr[i]=arr[i]*tdocnum/tnumperclass[i];
137 int max = select_sort(arr, catnum);
138 String dec=classes[max]; //分到了dec类
139 String t=testFileName.split("-")[0]; //实际属于t类
140 // 分类正确
141 if (dec.equals(t)) {
142 decide[max][0] += 1;
143 //return 0;
144 }
145 // 分类错误
146 else {
147 decide[max][1] += 1;
148 System.out.println("测试文档" + testFileName + "属于" + dec + "类!");
149 //return 1;
150 }
151 }
152
153 // 返回数组中最大者的下标
154 private int select_sort(double[] arr, int len) {
155 int k = 0;
156 double max = arr[k];
157 for (int i = 1; i < len; i++) {
158 if (arr[i] > max) {
159 max = arr[i];
160 k = i;
161 }
162 }
163 return k;
164 }
165
166 public void run(File testFile) throws DatabaseException,
167 FileNotFoundException {
168 if (testFile.isDirectory()) {
169 File[] children = testFile.listFiles();
170 for (File child : children) {
171 run(child);
172 }
173 } else if (testFile.isFile()) {
174 String testName = testFile.getName();
175 FileReader fr=new FileReader(testFile);
176 BufferedReader br=new BufferedReader(fr);
177 initV();
178 try{
179 String line=br.readLine().trim();
180 String[] cont=line.split("\\s+");
181 //System.out.println(cont.length);
182 //System.out.println(v.size());
183 for(int i=0;i<veclen;i++){
184 v.set(i, Double.parseDouble(cont[i]));
185 }
186 br.close();
187 }catch(IOException e){
188 e.printStackTrace();
189 }
190 fillQueue();
191 classify(testName);
192 }
193 }
194
195 public static void main(String[] args) throws DatabaseException,
196 IOException {
197 Date date=new Date();
198 int bd=date.getDay();
199 int bh=date.getHours();
200 int bm=date.getMinutes();
201 long mark=System.currentTimeMillis();
202 File result=new File("/home/orisun/master/fudan_corpus/result"+String.valueOf(mark));
203 result.createNewFile();
204 PrintWriter pw=new PrintWriter(new FileOutputStream(result));
205 KNN knn = new KNN("/home/orisun/master/fudan_corpus/BDB");
206 //System.out.println(knn.v.size());
207 File testFiles = new File("/home/orisun/master/fudan_corpus/answer_vec/C11-Space_ws");
208 System.out.println("----------错误报告---------------");
209 knn.run(testFiles);
210 knn.close();
211 double[] precision=new double[knn.catnum];
212 double[] recall=new double[knn.catnum];
213 pw.println();
214 pw.println("---------结果报表----------");
215 pw.println("类别\t\t正确\t错误\t精度\t召回度");
216 for (int i = 0; i < knn.decide.length; i++) {
217 pw.print(knn.classes[i] + "\t" + knn.decide[i][0]
218 + "\t" + knn.decide[i][1]);
219 int sum=knn.decide[i][0]+knn.decide[i][1];
220 precision[i]=1.0*knn.decide[i][0]/sum;
221 recall[i]=1.0*knn.decide[i][0]/knn.anumperclass[i];
222 pw.println("\t"+precision[i]+"\t"+recall[i]);
223 }
224 double p=0.0,r=0.0,f=0.0;
225 for(int i=0;i<knn.catnum;i++){
226 p+=precision[i]*knn.anumperclass[i]/knn.adocnum;
227 r+=recall[i]*knn.anumperclass[i]/knn.adocnum;
228 }
229 pw.println();
230 f=2*p*r/(p+r);
231 pw.println("精度p="+p+",召回率r="+r+",综合指数f="+f);
232 }
233 }
由于C++本身不能遍历目录,得借助于系统编程,那样就又跟系统平台相关了,为简化处理,我先把所有的训练文档和测试文档的完整路径分别写在了一个文本文件里,这样C++要遍历训练集或者测试集时只需要读这两个文件就可以了。这项工作是用Perl完成的:
View Code
1 #/usr/bin/perl
2 use File::Find;
3
4 $train_vec_files="/home/orisun/master/fudan_corpus/train_vec";
5 $answer_vec_files="/home/orisun/master/fudan_corpus/answer_vec";
6 $train_collection="/home/orisun/tc";
7 $answer_collection="/home/orisun/ac";
8 open TC,">$train_collection" or die "Can't open $train_collection:$!";
9 open AC,">$answer_collection" or die "Can't open $answer_collection:$!";
10
11 sub process1{
12 my $file=$File::Find::name;
13 if(-f $file){
14 unless($_=~/^\./){
15 print AC $file."\n";
16 }
17 }
18 }
19
20 sub process2{
21 my $file=$File::Find::name;
22 if(-f $file){
23 unless($_=~/^\./){
24 print TC $file."\n";
25 }
26 }
27 }
28
29 find(\&process1,$answer_vec_files);
30 find(\&process2,$train_vec_files);
31 close TC;
32 close AC;
C++版:
#include<iostream>
#include<cstdlib>
#include<vector>
#include<fstream>
#include<sstream>
#include<string>
#include<queue>
#include<functional>
#include<assert.h>
#include<cmath>
using namespace std;
//函数声明
int select_sort(vector<double> arr,int len); //选择数组中最大元素的下标
double cos(const vector<double>& vec1,const vector<double>& vec2); //计算两个向量的夹角余弦
void fillQueue(); //填充优先级队列
void classify(string testFileName,ostream &os); //文本分类
void run(string testFiles,ostream &os); //一次运行对所有的测试文本进行分类
//定义commiti结构体,它是优先队列中的元素类型
struct commiti{
string fn; //训练文档的文件名
double sim; //测试文档和训练文档的相似度
commiti(string f,double s):fn(f),sim(s){ //构造函数
}
bool operator < (const commiti& rhs)const{ //作为优先队列的元素,必须重载<运算符
return sim < rhs.sim;
}
bool operator > (const commiti& rhs)const{ //作为优先队列的元素,必须重载<运算符
return sim > rhs.sim;
}
};
//定义全局变量
const int K=15; //KNN中的K
const int veclen=1000; //文档向量的维度
const int catnum=9; //训练集(或测试集)总的类别数
const int tdocnum=7196; //训练文档的数目
const int adocnum=7193; //测试文档的数目
const string classes[]={"C39","C7","C3","C32","C31","C38","C34","C11","C19"}; //类别名称(训练集和测试集都按照这个顺序)
const int tnumperclass[]={1070,440,513,816,750,756,1392,473,986}; //训练集中各类别所含的文档数目
const int anumperclass[]={1066,447,508,822,741,758,1404,463,984}; //测试集中各类别所含的文档数目
priority_queue<commiti,vector<commiti>,greater<commiti> > pq; //优先队列,用来存储离测试文档最近的K个训练文档
vector<double> v; //测试文档的向量表示
int decide[catnum][2]; //存储每个类别判断正确和错误的文档数
int main(){
long begin=time(0);
ofstream ofs("/home/orisun/result",ios::out);
ofs<<"-------------------错误报告-------------------"<<endl;
run("/home/orisun/master/fudan_corpus/ac.txt",ofs);
double precision[catnum];
double recall[catnum];
//cout<<endl;
ofs<<"-------------------结果报表-------------------"<<endl;
ofs<<"类别\t正确\t错误\t精度\t召回度"<<endl;
for(int i=0;i<catnum;i++){
ofs<<classes[i]<<"\t"<<decide[i][0]<<"\t"<<decide[i][1]<<"\t"; //decide[i][0]是正确地归到了第i类的数目,decide[i][1]是错误地归到了第i类的数目
int sum=decide[i][0]+decide[i][1];
precision[i]=(double)decide[i][0]/sum;
recall[i]=(double)decide[i][0]/anumperclass[i];
ofs<<precision[i]<<"\t"<<recall[i]<<endl;
}
double p=0,r=0,f=0;
for(int i=0;i<catnum;i++){
p+=precision[i]*anumperclass[i]/adocnum; //总的精度是各类精度的加权和
r+=recall[i]*anumperclass[i]/adocnum; //权值为测试集中该类的文档数除以测试集文档总数
}
ofs<<endl;
f=2*p*r/(p+r);
ofs<<"精度="<<p<<"召回率="<<r<<"综合指数="<<f<<endl;
long finish=time(0);
ofs<<"用时:"<<(finish-begin)/60<<"分"<<endl;
ofs.close();
return 0;
}
double cos(const vector<double>& vec1,const vector<double>& vec2){
int len=vec1.size();
assert(len==vec2.size());
//if(len!=vec2.size()){
//cout<<len<<"\t"<<vec2.size()<<endl;
//exit(1);
//}
double res=0;
double mul=0;
double p1=0,p2=0;
for(int i=0;i<len;i++){
double one=vec1[i];
double two=vec2[i];
mul+=one*two;
p1+=one*one;
p2+=two*two;
}
res=mul/sqrt(p1*p2); //mul是向量内积,sqrt(p1)是向量1的模长,sqrt(p2)是向量2的模长
return res>0?res:0-res;
}
void fillQueue(){
while(!pq.empty()){ //清空优先队列
pq.pop();
}
ifstream itc("/home/orisun/master/fudan_corpus/tc.txt"); //对于每一个测试文档,都要遍历所有的训练文档
string line;
int i=0;
for(;i<tdocnum;i++){
getline(itc,line);
string::size_type pos=line.find_last_of('/');
string tfn=line.substr(pos+1);
ifstream itdoc(line.c_str());
string vs;
getline(itdoc,vs);
istringstream stream(vs);
vector<double> v2;
string word;
while(stream>>word)
v2.push_back(atof(word.c_str()));
itdoc.close();
double arc=cos(v,v2);
commiti node(tfn,arc);
if(i<K)
pq.push(node);
else{
if(pq.top()<node){
// cout<<tfn<<endl;
pq.pop();
pq.push(node);
}
}
}
// cout<<line<<endl;
// cout<<i<<endl;
itc.close();
}
int select_sort(vector<double> arr,int len){
int k=0;
double max=arr[k];
for(int i=1;i<len;i++){
if(arr[i]>max){
max=arr[i];
k=i;
}
}
return k;
}
void classify(string testFileName,ostream &os){
vector<double> arr(catnum); //arr记录邻居中各类的数目
while(!pq.empty()){
string tfn=pq.top().fn;
//cout<<tfn<<pq.top().sim<<endl;
pq.pop();
string::size_type pos=tfn.find_first_of('-');
string cs=tfn.substr(0,pos);
if(cs=="C34")
arr[6]++;
else if(cs=="C39") //C39
arr[0]++;
else if(cs=="C19") //C19
arr[8]++;
else if(cs=="C32") //C32
arr[3]++;
else if(cs=="C38") //C38
arr[5]++;
else if(cs=="C31") //C31
arr[4]++;
else if(cs=="C3") //C3
arr[2]++;
else if(cs=="C11") //C11
arr[7]++;
else if(cs=="C7") //C7
arr[1]++;
}
for(int i=0;i<catnum;i++)
arr[i]=arr[i]*tdocnum/tnumperclass[i];
int max=select_sort(arr,catnum);
string dec=classes[max];
string::size_type pos=testFileName.find_first_of('-');
string sc=testFileName.substr(0,pos);
if(dec.compare(sc)==0){
decide[max][0]+=1;
}
else{
decide[max][1]+=1;
os<<"测试文档"<<testFileName<<"分到了"<<dec<<"类"<<endl;
}
}
void run(string testFiles,ostream &os){
ifstream iiff(testFiles.c_str());
string testFile;
while(getline(iiff,testFile)){
string::size_type pos=testFile.find_last_of('/');
string filename=testFile.substr(pos+1);
v.clear();
//cout<<testFile<<endl;
ifstream ifs(testFile.c_str());
string line;
getline(ifs,line);
string weight;
//cout<<line<<endl;
istringstream iss(line);
while(iss>>weight){
v.push_back(atof(weight.c_str()));
}
ifs.close();
//if(v.size()!=1000)
//cout<<v.size()<<endl;
fillQueue();
classify(filename,os);
}
iiff.close();
}运行了五个多小时。
上一次特征词选300个,K=10,6个分类,训练集6000篇,测试集3000篇,每类数目都是均匀的,精度在0.92左右。
而这一次的情况是:
| 训练集train | begin | end | 测试集answer | begin | end | ||
| C34-Economy | 1392 | 4345 | 5736 | C34-Economy | 1404 | 4342 | 5745 |
| C39-Sports | 1070 | 0 | 1069 | C39-Sports | 1066 | 0 | 1065 |
| C19-Computer | 986 | 6210 | 7195 | C19-Computer | 984 | 6209 | 7192 |
| C32-Agriculture | 816 | 2023 | 2838 | C32-Agriculture | 822 | 2021 | 2842 |
| C38-Politics | 756 | 3589 | 4344 | C38-Politics | 758 | 3584 | 4341 |
| C31-Enviornment | 750 | 2839 | 3588 | C31-Enviornment | 741 | 2843 | 3583 |
| C3-Art | 513 | 1510 | 2022 | C3-Art | 508 | 1513 | 2020 |
| C11-Space | 473 | 5737 | 6209 | C11-Space | 463 | 5746 | 6208 |
| C7-History | 440 | 1070 | 1509 | C7-History | 447 | 1066 | 1512 |
| Total | 7196 | Total | 7193 | ||||
但这一次所有的文本长度都大于500,并且文档向量的长度取到了1000,K=15。
训练集和测试集各类分布是倾斜的,但各类所占的比例基本上保持一致。
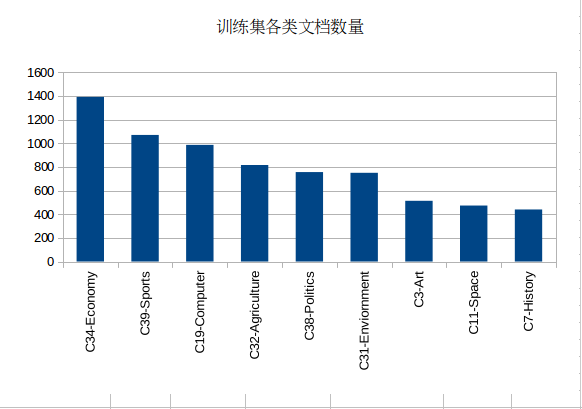
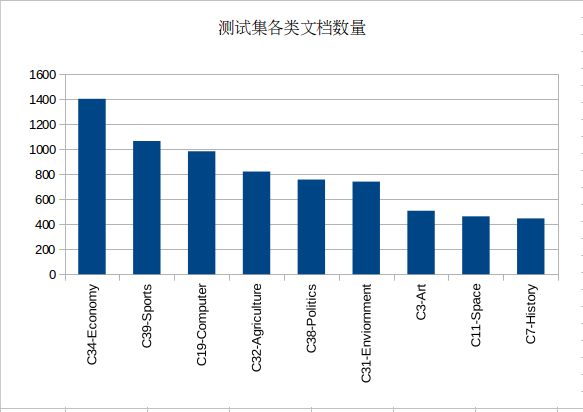
KNN的分类效果:
| 类别 | 正确 | 错误 | 精度 | 召回度 |
| C39 | 971 | 13 | 0.986789 | 0.910882 |
| C7 | 307 | 86 | 0.78117 | 0.686801 |
| C3 | 467 | 79 | 0.855311 | 0.919291 |
| C32 | 774 | 131 | 0.855249 | 0.941606 |
| C31 | 623 | 46 | 0.931241 | 0.840756 |
| C38 | 722 | 152 | 0.826087 | 0.952507 |
| C34 | 1261 | 96 | 0.929256 | 0.898148 |
| C11 | 374 | 119 | 0.758621 | 0.807775 |
| C19 | 895 | 77 | 0.920782 | 0.909553 |
| 总体指数 | ||||
| 精度 | 0.89209 | |||
| 召回率 | 0.88892 | |||
| 综合指数 | 0.890502 |


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









