



 本文分享了一个使用Python进行网络爬虫的实战案例——爬取糗事百科网站的内容。通过构造HTTP请求,获取并解析网页数据,实现了段子内容、作者、点赞数及评论数的抓取。
本文分享了一个使用Python进行网络爬虫的实战案例——爬取糗事百科网站的内容。通过构造HTTP请求,获取并解析网页数据,实现了段子内容、作者、点赞数及评论数的抓取。

到这里,我们爬取糗事百科这个入门项目已经结束了,下面贴上源码:
---------------------------------爬取糗事百科段子源码----------------------------
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
__author__ = '217小月月坑'
import urllib2
import re
# url:存放url网址的变量
url = 'http://www.qiushibaike.com/'
# user_agent:存放身份识别信息的变量
user_agent = 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:40.0) Geck
o/20100101 Firefox/40.0'
# 一个headers的字典,headers可以有很多项,所以要用一个字典来存放
headers = {'User-Agent': user_agent}
'''
req = urllib2.Request(url, headers)
这样写是错误的,TypeError: must be string or buffer, not dict
'''
'''
为什么要使用headers=headers
原因:urllib2.Request 有三个参数,url,data,和headers,
如果将所有参数都写上去的话,可以直接写urllib2.Request(url, data, headers)
如果第二个参数不写的话,要指明第三个参数
'''
# 加入异常处理,注意try,expetc,if语句后面要有冒号
try:
# 构造一个请求
req = urllib2.Request(url, headers=headers)
# 发送请求,获取返回的数据
response = urllib2.urlopen(req)
# 将爬取的网页源码存入一个变量中
content = response.read()
# 使用compile将正则表达式编译并存入一个pattern变量中
# 注:这里使用了四个正则额表达式,每一个表达式获取一个想要的信息
pattern = re.compile(r'<h2>(.*?)</h2>.*?'+'<div.*?class="content">
(.*?)<!.*?'+'<div.*?class="stats".*?class="number">(.*?)</i>.*?'+
'<span.*?class="dash".*?class="number">(.*?)</i>.*?',re.S)
# 使用findall方法按re查找,findall返回的是一个列表
items = re.findall(pattern,content)
# 使用for循环遍历列表中的元素并将它们打印出来
for item in items:
print '发布人:'+item[0]+'\n','段子内容:'+item[1]+'\n','点赞数:'
+item[2]+'\n','评论数:'+item[3]+'\n'
except urllib2.URLError, e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
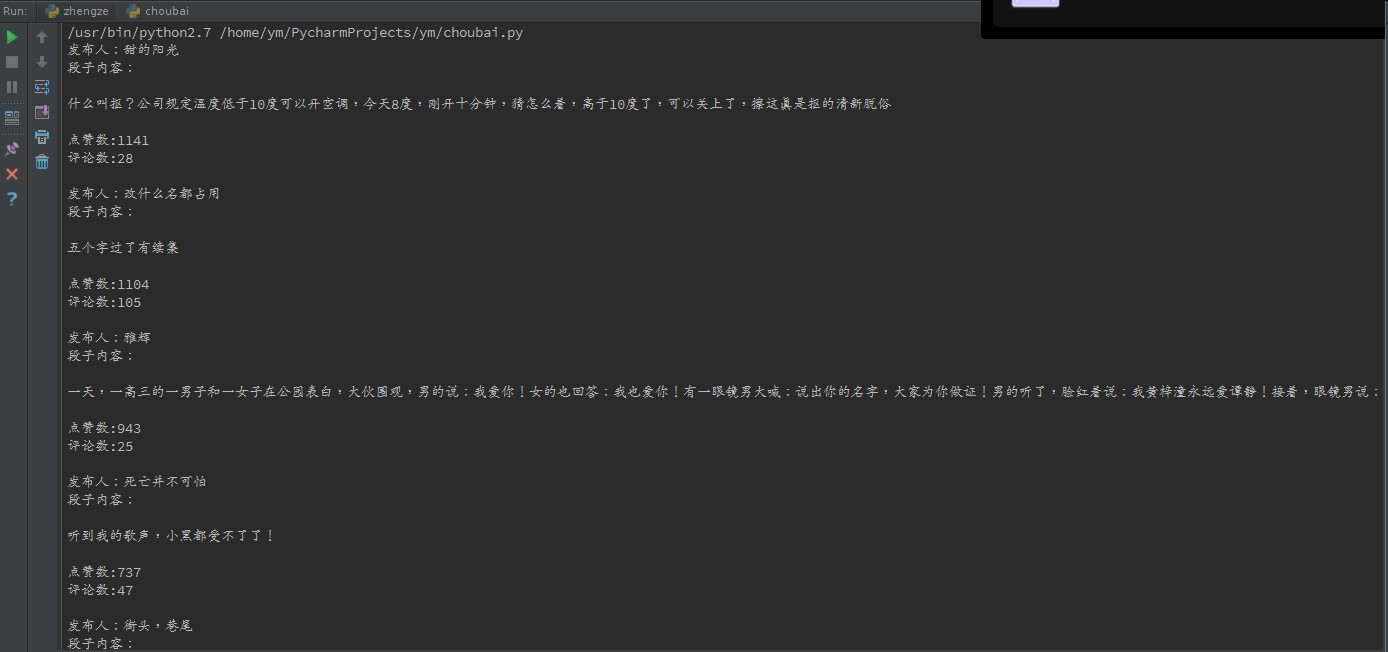
print e.reason输出的结果如下:

















 458
458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









