






转载请以链接形式注明文章来源,公众号:MicroPython玩家汇
0x00前言
之前看到一篇文章是关于TPYBoardv102控制OLED屏显示的,看到之后就想尝试一下使用OLED屏来显示中文。最近利用空余时间搞定了这个实验,特此将实验过程及源码分享出来,方便以后使用。
0x01实验器材
TPYBoardv102开发板1块
0.96寸OLED显示屏(ssd1306)1块
杜邦线若干
0x02前期准备
1、 首先我们先来看一下,之前参考的OLED显示字符的文章。
http://docs.tpyboard.com/zh/latest/tpyboard/tutorial/v10x/oled/?highlight=oled
文章中的源码文件都已上传到GitHub。地址:https://github.com/TPYBoard/developmentBoard/tree/master/TPYBoard-v10x-master
找到[11.学习使用OLED显示屏]里面就是源程序。我就是在font.py和ssd1306.py基础上做的开发。
2、 在font.py中增加中文字模。
font.py中已有英文、数字和符号的字符,我们需要做中文的字模添加到font.py中。
2.1首先下载字模提取工具。地址:http://tpyboard.com/download/tool/187.html
解压,双击运行PCtoLCD2002.exe。
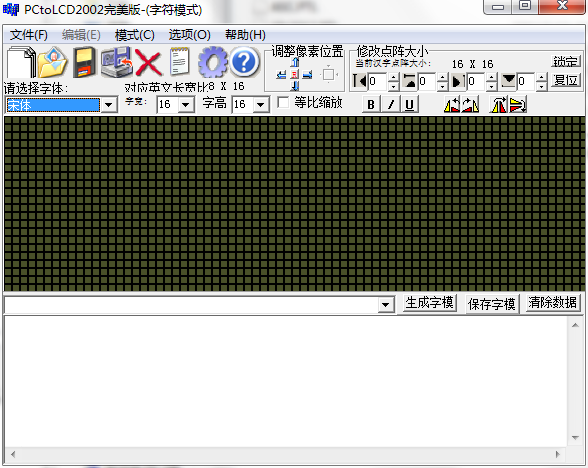
2.2 顶端菜单栏,点击[选项]按下方图片设置,设置完毕后点击[确定]保存设置。
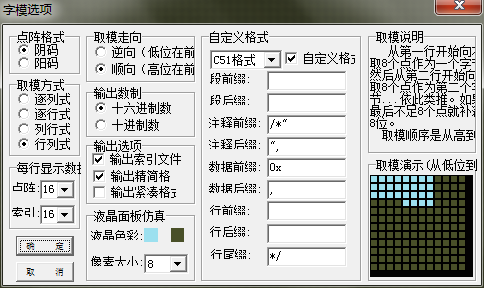
2.3 回到主界面,在输入框中输入“我”点击[生成字模]。
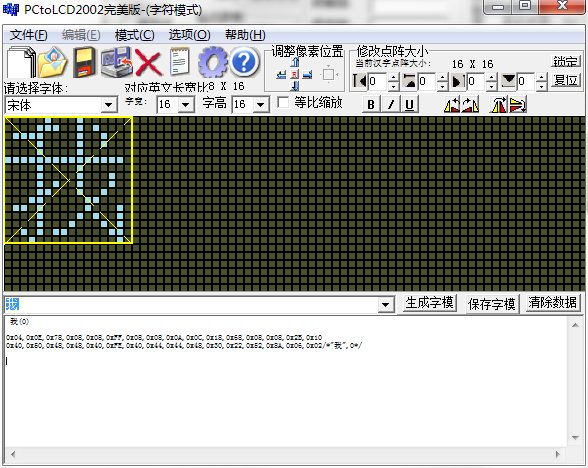
取得的字模数据如下:
|
0x04,0x0E,0x78,0x08,0x08,0xFF,0x08,0x08,0x0A,0x0C,0x18,0x68,0x08,0x08,0x2B,0x10 0x40,0x50,0x48,0x48,0x40,0xFE,0x40,0x44,0x44,0x48,0x30,0x22,0x52,0x8A,0x06,0x02/*"我",0*/ |
2.4 将取到的字模数据添加到font.py中。

绿色框中是“我”的16进制utf-8编码。
在线工具:http://tool.lu/hexstr/
参照以上方法,我依次添加了“我爱你祖国”这5个汉字的字模。
|
byte2 = {
0xe68891: [ 0x04,0x0E,0x78,0x08,0x08,0xFF,0x08,0x08,0x0A,0x0C,0x18,0x68,0x08,0x08,0x2B,0x10, 0x40,0x50,0x48,0x48,0x40,0xFE,0x40,0x44,0x44,0x48,0x30,0x22,0x52,0x8A,0x06,0x02, ],#我 0xe788b1: [ 0x00,0x01,0x7E,0x22,0x11,0x7F,0x42,0x82,0x7F,0x04,0x07,0x0A,0x11,0x20,0x43,0x1C, 0x08,0xFC,0x10,0x10,0x20,0xFE,0x02,0x04,0xF8,0x00,0xF0,0x10,0x20,0xC0,0x30,0x0E, ],#爱 0xe4bda0: [ 0x08,0x08,0x08,0x11,0x11,0x32,0x34,0x50,0x91,0x11,0x12,0x12,0x14,0x10,0x10,0x10, 0x80,0x80,0x80,0xFE,0x02,0x04,0x20,0x20,0x28,0x24,0x24,0x22,0x22,0x20,0xA0,0x40, ],#你 0xe7a596: [ 0x20,0x11,0x11,0xF9,0x09,0x11,0x11,0x39,0x55,0x95,0x11,0x11,0x11,0x11,0x17,0x10, 0x00,0xF8,0x08,0x08,0x08,0xF8,0x08,0x08,0x08,0xF8,0x08,0x08,0x08,0x08,0xFE,0x00 ],#祖 0xe59bbd: [ 0x00,0x7F,0x40,0x40,0x5F,0x41,0x41,0x4F,0x41,0x41,0x41,0x5F,0x40,0x40,0x7F,0x40, 0x00,0xFC,0x04,0x04,0xF4,0x04,0x04,0xE4,0x04,0x44,0x24,0xF4,0x04,0x04,0xFC,0x04 ],#国 } |
3、 在ssd1306.py文件中增加了draw_chinese显示中文的方法。
|
def draw_chinese(self,ch_str,x_axis,y_axis): offset_=0 y_axis=y_axis*8#中文高度一行占8个 x_axis=127-(x_axis*16)#中文宽度占16个 for k in ch_str: code = 0x00#将中文转成16进制编码 data_code = k.encode("utf-8") code |= data_code[0]<<16 code |= data_code[1]<<8 code |= data_code[2] byte_data=font.byte2[code] for y in range(0,16): a_=bin(byte_data[y]).replace('0b','') while len(a_)<8: a_='0'+a_
b_=bin(byte_data[y+16]).replace('0b','') while len(b_)<8: b_='0'+b_ for x in range(0,8): self.set_pixel(x_axis-x-offset_,y+y_axis,int(a_[x]))#文字的上半部分 self.set_pixel(x_axis-x-8-offset_,y+y_axis,int(b_[x]))#文字的下半部分 offset_+=16 |
github源码地址:https://github.com/TPYBoard/developmentBoard/tree/master/TPYBoard-v10x-master/
找到[20.学习OLED显示中文]。
0x03硬件连接
本次实验使用OLED的SPI通讯方式,TPYBoardv102带有2个SPI接口,我用的SPI1。
具体接线方法如下:
|
TPYBoard v102 (SPI1) |
OLED显示屏(SPI) |
|
3.3V |
VCC (2.8V~5.5V) |
|
GND |
GND |
|
X6(SCK) |
SCK/D0 |
|
X8(MOSI) |
SDA/D1 |
|
Y10 |
RES |
|
Y9 |
DC |
|
NC(悬空) |
CS |
0x04效果展示
硬件接线OK后,将源码全部拷贝到TPYBaordv102加载的磁盘中,按下RST按键复位或者使用Putty软件Ctrl+D软复位,重新运行效果如下:


















 2628
2628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









