




1 锁优化的思路和方法
一旦用到锁,就说明这是阻塞式的。这里提到的锁优化,是指在阻塞式的情况下,如何让性能不要变得太差。但是再怎么优化,一般来说性能都会比无锁的情况差一些。
1.1 减少锁持有时间
| public synchronized void syncMethod(){ othercode1(); mutextMethod(); othercode2(); } |
上述代码,线程在进入方法前都要先获取到锁,同时其他线程只能在外面等待。
这里优化的一点在于,要减少其他线程等待的时间,所以,只在有线程安全要求的程序上加锁。
| public void syncMethod2(){ othercode1(); synchronized(this){ mutextMethod(); } othercode2(); } |
1.2 减少锁粒度
将大对象(这个对象可能会被很多线程访问),折成小对象,大大增加并行度,降低锁竞争、降低了锁的竞争,偏向锁,轻量级锁成功率才会提高。
最典型的减少锁粒度的案例就是ConcurrentHashMap(ConcurrentHashMap内部使用Segment数组,每个Segment类似于Hashtable。put操作时,先定位到Segment,锁定一个Segment,执行put)。在减小锁粒度后, ConcurrentHashMap允许若干个线程同时进入。
1.3 锁分离
最常见的锁分离就是读写锁ReadWriteLock,根据功能进行分离成读锁和写锁,这样读读不互斥,读写互斥,写写互斥,即保证了线程的安全,又提高了性能。
读写分离思想可以延伸,只要操作互不影响,锁就可以分离。
比如:LinkedBlockingQueue(链表、队列)
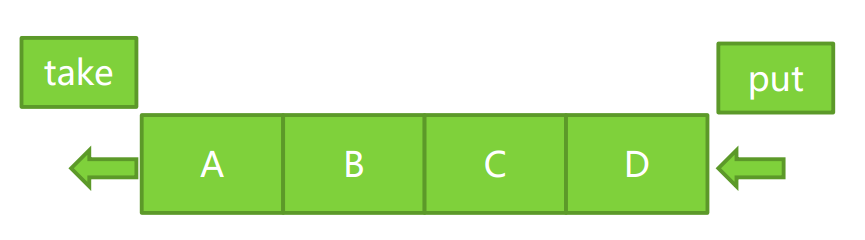
从头部取出,从尾部放数据。这有点类似ForkKoinPool中的工作窃取。
1.4 锁粗化
通常情况下,为了保证多线程间的有效并发,会要求每个线程持有锁的时间尽量短,即在使用完公共资源后,应该立即释放锁。只有这样,等待在这个锁上的其他线程才能尽早地获取资源执行任务。但是凡事都有一个度,如果对同一个锁不停地进行请求、同步和释放,其本身也会消耗系统宝贵的资源,反而不利于性能的优化。
举个例子:
| public void demoMethod(){ synchronized(lock){ //do sth. } //做其他不需要的同步的工作,但能很快执行完毕 synchronized(lock){ //do sth. } } |
这种情况,根据锁粗化的思想,应该合并:
| public void demoMethod(){ //整合成一次锁请求 synchronized(lock){ //do sth. //做其他不需要的同步的工作,但能很快执行完毕 } } |
当然这是有前提的,前提就是中间那么不需要同步的工作是很快执行完成的。
再举一个极端的例子:
| for(int i=0;i<CIRCLE;i++){ synchronized(lock){ } } |
在循环内不停地获取锁。虽然JDK内部会对这个代码做些优化,但是还不如直接写成
| synchronized(lock){ for(int i=0;i<CIRCLE;i++){ } } |
当然如果有需求说,循坏不能让其他线程等待太久,那只能写成第一种形式。如果没有这样类似的需求,还是直接写成第二种实现方式比较好。
1.5 锁消除
在即时编译时,如果发现不可能被共享的对象,则可以消除这些对象的锁操作。
也许你会觉得奇怪,既然有些对象不可能被多线程访问,那为什么要加锁呢?写代码时直接不加锁不就好了。
但是有些锁并不是程序员所写的,比如Vector和StringBuffer这样的类,它们中的很多方法都是有锁的。当我们在一些不会有线程安全的情况下使用这些类的方法时,达到某些条件时,编译器会将锁消除来提高性能。
例如:
| public static void main(String args[]) throws InterruptedException { public static String createStringBuffer(String s1, String s2) { |
上述代码中的StringBuffer.append是一个同步操作,但是StringBuffer却是一个局部变量,并且方法也没有把StringBuffer返回,所以不可能会有多线程去访问它。
那么此时StringBuffer中的同步操作就是没有意义的。
开启锁消除是在JVM参数上设置的,当然需要在server模式下:
| -server -XX:+DoEscapeAnalysis -XX:+EliminateLocks |
并且要开启逃逸分析。逃逸分析的作用呢,就是看看变量是否有可能逃出作用域的范围。
比如上述的StringBuffer,上述代码中createStringBuffer的返回是一个String,所以这个局部变量StringBuffer在其他地方都不会被使用。如果将createStringBuffer改成:
| public static StringBuffer craeteStringBuffer(String s1, String s2) { StringBuffer sb = new StringBuffer(); sb.append(s1); sb.append(s2); return sb; } |
那么这个StringBuffer被返回后,是有可能被任何其他地方所使用的。那么JVM的逃逸分析可以分析出,这个局部变量StringBuffer逃出了它的作用域,锁就不会被消除。
当JVM参数为:
| -server -XX:+DoEscapeAnalysis -XX:+EliminateLocks |
输出:
| craeteStringBuffer: 302 ms |
JVM参数为:
| -server -XX:+DoEscapeAnalysis -XX:-EliminateLocks |
输出:
| craeteStringBuffer: 660 ms |
显然,锁消除的效果还是很明显的。
2. 虚拟机内的锁优化
首先要介绍下对象头,在JVM中,每个对象都有一个对象头。
- Mark Word,对象头的标记,32位
- 描述对象的hash、锁信息,垃圾回收标记,年龄
– 指向锁记录的指针
– 指向monitor的指针
– GC标记
– 偏向锁线程ID
简单来说,对象头就是要保存一些系统性的信息。
2.1 偏向锁
- 大部分情况是没有竞争的,所以可以通过偏向来提高性能
- 所谓的偏向,就是偏心,即锁会偏向于当前已经占有锁的线程
- 将对象头Mark的标记设置为偏向,并将线程ID写入对象头Mark
- 只要没有竞争,获得偏向锁的线程,在将来进入同步块,不需要做同步
- 当其他线程请求相同的锁时,偏向模式结束
- --XX:+UseBiasedLocking(默认开启)
- 在竞争激烈的场合,偏向锁会增加系统负担(每次都要加一次是否偏向的判断)
偏向锁的例子:
| package test; import java.util.List; public class Test { public static void main(String[] args) throws InterruptedException { } |
Vector是一个线程安全的类,内部使用了锁机制。每次add都会进行锁请求。上述代码只要main一个线程在反复add请求锁。使用如下的JVM参数来设置偏向锁:
| -XX:+UseBiasedLocking -XX:BiasedLockingStartupDelay=0 |
BiasedLockingStartupDelay表示系统启动几秒钟后启用偏向锁。默认为4秒,原因在于,系统刚启动时,一般数据竞争是比较激烈的,此时启用偏向锁会降低性能。
由于这里为了测试偏向锁的性能,所以把延迟偏向锁的时间设置为0。
输出:9209
下面关闭偏向锁:
| -XX:-UseBiasedLocking |
输出:9627
一般在无竞争时,启用偏向锁性能会提高5%左右。
2.2 轻量级锁
Java的多线程安全是基于Lock机制实现的,而Lock的性能往往不如人意。
原因是,monitorenter与monitorexit这两个控制多线程同步的bytecode原语,是JVM依赖操作系统互斥(mutex)来实现的。
互斥是一种会导致线程挂起,并在较短的时间内又需要重新调度回原线程的,叫我消耗资源的操作。
- 普通的锁处理性能不够理想,轻量级锁是一种快速的锁定方法。
- 如果对象没有被锁定
- – 将对象头的Mark指针保存到锁对象中
- – 将对象头设置为指向锁的指针(在线程栈空间中)
轻量级锁的总结:
- 如果轻量级锁失败,表示存在竞争,升级为重量级锁(常规锁)
- 在没有锁竞争的前提下,减少传统锁使用OS互斥量产生的性能损耗
- 在竞争激烈时,轻量级锁会多做很多额外操作,导致性能下降。
2.3 自旋锁
当竞争存在时,因为轻量级锁尝试失败,之后有可能会直接升级成重要级锁动用操作系统层面的互斥,也有可能再尝试一下自旋锁。
- 当竞争存在时,如果线程可以很快获得锁,那么可以不在OS层挂起线程,让线程做几个空操作(自旋),并且不停地尝试拿到这个锁(类似tryLock),当然循坏的次数是有限制的,当循坏次数达到以后,仍然会升级成重量级锁。
- JDK1.6中-XX:+UseSpinning开启
- JDK1.7中,去掉此参数,改为内置实现
- 如果同步块很长,自旋失败,会降低系统性能
- 如果同步块很短,自旋成功,节省线程挂起切换时间,提升系统性能
偏向锁,轻量级锁,自旋锁总结:
- 不是Java语言层面的锁优化方法,是内置在JVM当中的
- 首先偏向锁是为了避免某个线程反复获取/释放同一把锁时的性能消耗,如果仍然是同个线程去获得这个锁,尝试偏向锁时会直接进入同步块。不需要再次获得锁。
- 而轻量级锁和自旋锁都是为了避免直接调用操作系统层面的互斥操作,因为挂起线程是一个很消耗资源的操作。
- 获取锁的优化方法和获取锁的步骤:
– 偏向锁可用会先尝试偏向锁
– 轻量级锁可用会先尝试轻量级锁
– 以上都失败(说明存在竞争),尝试自旋锁
– 再失败,尝试普通锁,使用OS互斥量在操作系统层挂起
3 一个错误使用锁的案例
| public class IntegerLock { public static class AddThread extends Thread { public static void main(String[] args) throws InterruptedException { |
一个很初级的错误在于,Integer是final不变的,每次++后,会产生一个新的Integer再赋值给i,所以两个线程竞争的锁是不同的。所以并不是线程安全的。
4 ThreadLocal及其源码分析
这里来提ThreadLocal可能有点不合适,但是ThreadLocal是可以把锁代替的方式。所以还是有必要提一下。
基本的思想就是,在一个多线程当中需要把有数据冲突的数据加锁,使用ThreadLocal的话,为每一个线程都提供一个对象。不同的线程只访问自己的对象,而不访问其他的对象。这样锁就没必要存在了。
| package test; import java.text.ParseException; public class Test { public static class ParseDate implements Runnable { public ParseDate(int i) { public void run() { public static void main(String[] args) { } |
由于SimpleDateFormat并不线程安全的,所以上述代码是错误的使用。最简单的方式就是,自己定义一个类去用synchronized包装(类似于Collections.synchronizedMap)。这样做在高并发时会有问题,对synchronized的争用导致每一次只能进去一个线程,并发量很低。这里使用ThreadLocal去封装SimpleDateFormat就解决了这个问题。
| package test; import java.text.ParseException; public class Test { public static class ParseDate implements Runnable { public ParseDate(int i) { public void run() { public static void main(String[] args) { } |
每个线程在运行时,会判断当前线程是否有SimpleDateFormat对象:
| if (tl.get() == null) |
如果没有的话,就new个SimpleDateFormat与当前线程绑定:
| tl.set(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")); |
然后用当前线程的SimpleDateFormat去解析:
| tl.get().parse("2016-02-16 17:00:" + i % 60); |
一开始的代码中,只有一个SimpleDateFormat,使用了ThreadLocal,为每一个线程都new了一个SimpleDateFormat。需要注意的是,这里不要把公共的一个SimpleDateFormat设置给每一个ThreadLocal,这样是没用的。需要给每一个都new一个SimpleDataFormar。
在hibernate中,对ThreadLocal有典型的应用。
下面来看一下ThreadLocal的源码实现
首先Thread类中有一个成员变量:
| ThreadLocal.ThreadLocalMap threadLocals = null; |
而这个Map就是ThreadLocal的实现关键:
| public void set(T value) { Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); if (map != null) map.set(this, value); else createMap(t, value); } |
根据ThreadLocal可以set和get相对应的value。这里的ThreadLocalMap实现和HashMap差不多,但是在hash冲突的处理上有区别。ThreadLocalMap中发生hash冲突时,不是像HashMap这样用链表来解决冲突,而是将索引++,放到下一个索引来解决冲突。

















 931
931

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









