






 本文探讨了深度图像先验(DeepImagePrior)如何革新图像复原技术,无需预训练网络和大量数据即可从损坏图像中恢复高质量图像。通过分析DeepImagePrior的原理,展示了其在图像去噪、超分辨率和图像修复任务中的优越性。
本文探讨了深度图像先验(DeepImagePrior)如何革新图像复原技术,无需预训练网络和大量数据即可从损坏图像中恢复高质量图像。通过分析DeepImagePrior的原理,展示了其在图像去噪、超分辨率和图像修复任务中的优越性。

本文为 AI 研习社编译的技术博客,原标题 :
Demystifying—Deep Image Prior
作者 | Pratik KatteFollow
翻译 | GAOLILI
校对 | 酱番梨 审核 | 约翰逊·李加薪 整理 | 立鱼王
原文链接:
https://towardsdatascience.com/demystifying-deep-image-prior-7076e777e5ba
在这篇文章中,我将主要介绍图像复原和深度图像先验如何用于图像复原。
图像复原的介绍
图像复原是指从退化的图像中恢复未知的真实图像。图像的退化可能出现在图像形成、传输和保存期间。图像复原技术广泛应用于卫星图像和低光摄影。并且由于数字技术、计算和通信技术的发展,从退化的图像中复原出原始的图像变得非常重要,这已经发展成一种与图像处理、计算机视觉以及计算成像相交叉的研究领域。
图像复原主要有三个任务:
1.图像去噪:
图像去噪是指复原包含多余噪声的图像。这是图像复原中最简单的任务,已经广泛被多个技术团队所研究。

图1 (左)包含噪声的图像,(中)不含噪声的图像,(右)高斯噪声
2. 超分辨率技术:
超分辨率技术是指从一组低分辨率图像重建出相应的高分辨率图像(或一系列高分辨率图像)的过程。

图2.(左)低分辨率图像,(右)高分辨率图像
3. 图像修复:
图像修复是指重建图像丢失损坏部分的过程。图像修复实际上是一种人们填补绘画作品中损坏和丢失部分的传统艺术,但在现如今的研究中已经提出了很多利用深度卷积网络自动修复的方法。

图3.(左)输入,(右)输出
什么是Deep Image Prior?
随着AlexNet在2012年ImageNet竞赛中取得成功,卷积神经网络开始流行起来并且被应用在每个计算机视觉和图像处理任务中,而且也被广泛用于执行图像重建这样的逆任务,并且已经取得了最好的表现。
深度卷积网络因其能够从大量图像数据中学习而取得成功。Dmitry Ulyanov发表的令人惊叹的论文“Deep Image Prior”表明解决像图像复原这样的逆问题,网络结构已经能够并且很好的从损坏的图像复原出原图像。这篇论文强调,进行图像复原不需要预训练网络和大量的图像数据,仅仅有损坏的图像就可以。
在图像复原中,基于学习的方法和基于非学习的方法是两种通用的并且研究人员主要使用的方法。
基于学习的方法是一种直接的方法,它将噪声图像作为输入数据,原始图像作为输出数据去训练深度卷积网络进行学习。另一方面,基于非学习的方法或手动制作先验的方法是我们从合成数据里强行加入和告知了什么类型的图像是自然的、真实的等等。用数学表达像自然这样的状态变数非常困难。
在Deep Image Prior里,作者试图通过使用卷积神经网络构造一个新的基于非学习的方法去弥补这两种通用的图像复原方法之间的鸿沟。
让我们看点技术的东西吧...

图4.(左)原始图像,(中)损坏的图像,(右)复原的图像
X→原始图像

→损坏的图像
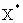
→复原图像
我们可以从经验数据中使用最大后验分布来估计看不到的值。

使用贝叶斯规则,我们可以将其表示为似然*先验。

我们可以将方程式表示为优化问题,而不是单独使用分布。
对式(1)应用负算法

E(x;ẋ)是数据项,它是负似然对数,R(x)是图像先验项,是先验的负对数。
现在的任务是最小化图像X上的公式(2)。传统的方法是用随机噪声初始化X,然后计算函数相对于X的梯度并遍历图像空间直到其收敛到某个点。
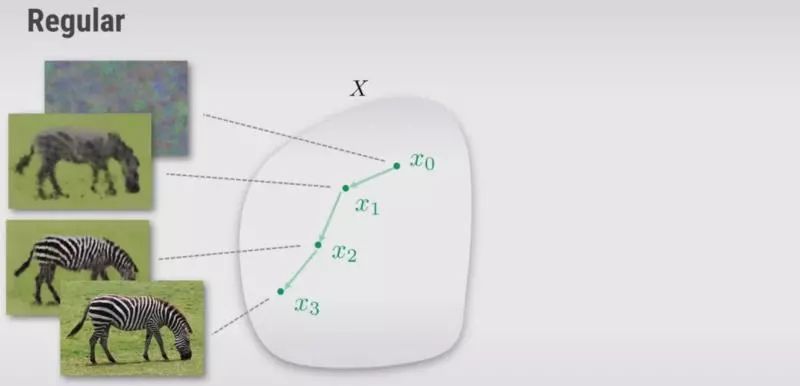
图5.常规方法的可视化
另一种方法是构造一个用随机数θ初始化的函数g,它来自不同空间的输出可以映射到图像X,并使用梯度下降更新θ直到其在某个点收敛。因此,与其优化图像空间,我们可以优化θ。


图6.参数化方法的可视化
但是,为什么这种方法可行并且我们要使用它呢?这可能是因为从理论上讲,如果g是满射的,g:θ →x (如果至少一个θ映射到图像X),那么这两种优化方法就是等价的,即它们具有相同的解。但是实际上g会极大地改变搜索图像空间的优化方法。我们实际上可以将g视为超参数并对它进行调整。如果我们观察一下就可以发现,g(θ)是作为一个先验的,它有助于选择一个良好的映射,给出一个我们想要的输出图像,并防止我们得到一个错误的图像。
因此,与其优化两个部分的总和,我们现在只需要优化第一个部分就可以。
现在,公式(2)可以表示为:
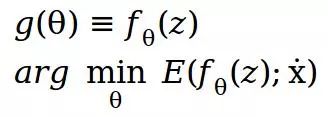
其中z是固定的随机输入图像,θ是随机初始化的权重,它将通过梯度下降来进行更新以获得目标输出图像。
但是,为什么我们应该考虑这种参数化方法的原因依然不明确。从理论上来看,它似乎会产生原始的噪声图像。在论文中作者进行了一项实验,该实验表明,在使用梯度下降来优化网络的时候,卷积神经网络对噪声图像不敏感,并且会更快更容易下降到看到更自然的图像。
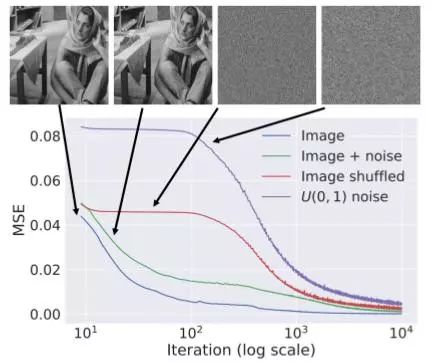
图7.复原任务的学习曲线:一个自然的图像,同样的图像加一些噪声,一样的随机乱码,和白噪声。看起来自然的图像会更快的收敛,而噪声图像会被拒绝。
Deep Image Prior 的步骤
是损坏的图像(观察到的)
1. 初始化Z:用均匀噪声或任何其他随机图像填充输入的Z。
2. 使用基于梯度的方法求解和优化函数。

3. 最后我们找到最佳θ时,我们可以通过将固定输入z向前传递到具有参数θ的网络来获得最佳图像。

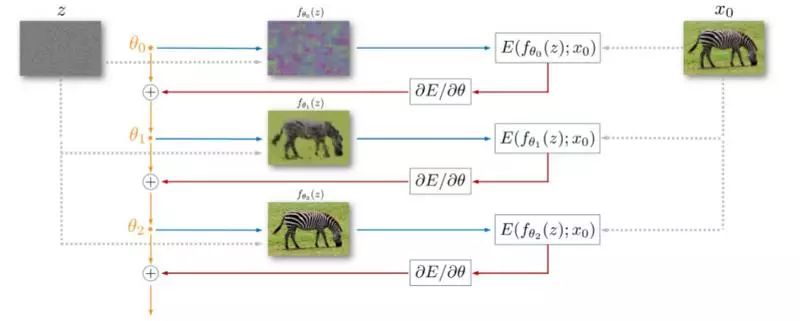
图8.图像复原使用Deep Image Prior。从一个随机的权重θ0开始,我们迭代地更新它来达到最小化数据项公式(2)。在每次迭代时权重θ被映射到图像,x = f θ (z),其中Z是固定张量,映射f是具有参数θ的神经网络。图像X被用于计算和任务相关的损失E(x, x 0 )。损失w.r.t.的梯度和权重θ被计算并且用于更新参数。
总结
《Deep Image Prior》这篇论文试图证明构造具有随机权重的隐式先验在深度卷积神经网络体系结构里非常适合于图像复原任务。论文中的结果表明正确的手动构造的网络结构足以解决图像复原问题。
想要继续查看该篇文章相关链接和参考文献?
点击【使用《Deep Image Prior》】或长按下方地址打开:
https://ai.yanxishe.com/page/TextTranslation/1498
AI研习社今日推荐:雷锋网雷锋网(公众号:雷锋网)雷锋网
卡耐基梅隆大学 2019 春季《神经网络自然语言处理》是CMU语言技术学院和计算机学院联合开课,主要内容是教学生如何用神经网络做自然语言处理。神经网络对于语言建模任务而言,可以称得上是提供了一种强大的新工具,与此同时,神经网络能够改进诸多任务中的最新技术,将过去不容易解决的问题变得轻松简单。
加入小组免费观看视频:https://ai.yanxishe.com/page/groupDetail/33


















 8355
8355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









