



 本文通过一个统计日志中ERROR的示例介绍了Spark程序模型的基本概念。包括如何使用SparkContext从HDFS读取日志文件,如何过滤并统计含有特定关键词的行数。此外还讨论了RDD的操作方式以及其与Scala集合的相似性和区别。
本文通过一个统计日志中ERROR的示例介绍了Spark程序模型的基本概念。包括如何使用SparkContext从HDFS读取日志文件,如何过滤并统计含有特定关键词的行数。此外还讨论了RDD的操作方式以及其与Scala集合的相似性和区别。
本节书摘来自华章出版社《循序渐进学Spark》一书中的第2章,第2.2节,作者 小象学院 杨 磊,更多章节内容可以访问云栖社区“华章计算机”公众号查看。
2.2 Spark程序模型
下面给出一个经典的统计日志中ERROR的例子,以便读者直观理解Spark程序模型。
1)SparkContext中的textFile函数从存储系统(如HDFS)中读取日志文件,生成file变量。
scala> var file = sc.textFile("hdfs://...")
2)统计日志文件中,所有含ERROR的行。
scala> var errors = file.filer(line=>line.contains("ERROR"))
3)返回包含ERROR的行数。
errors.count()
RDD的操作与Scala集合非常类似,这是Spark努力追求的目标:像编写单机程序一样编写分布式应用。但二者的数据和运行模型却有很大不同,如图2-3所示。
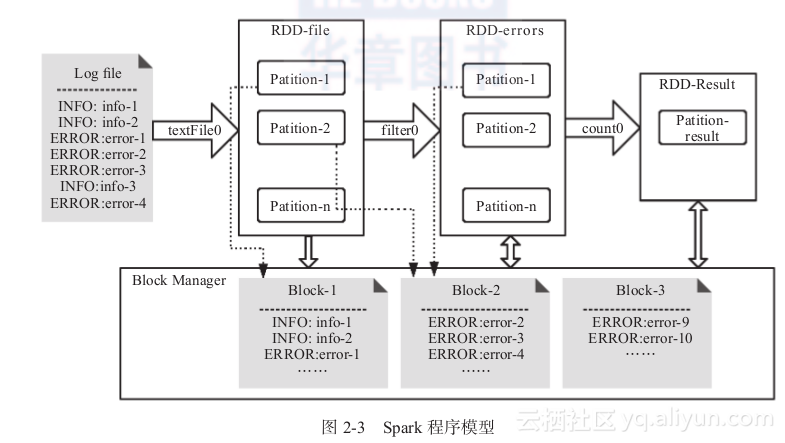
在图2-3中,每一次对RDD的操作都造成了RDD的变换。其中RDD的每个逻辑分区Partition都对应Block Manager(物理存储管理器)中的物理数据块Block(保存在内存或硬盘上)。前文已强调,RDD是应用程序中核心的元数据结构,其中保存了逻辑分区与物理数据块之间的映射关系,以及父辈RDD的依赖转换关系。

















 7021
7021

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









